
- Расшифровка Языка Машин: Наш Путеводитель по Магии NLP с Python
- Фундамент Понимания: Токенизация‚ Стемминг и Лемматизация
- Регулярные Выражения: Хирургическая Точность в Предобработке
- От Слов к Числам: Векторизация и Представления Текста
- Простые‚ но Эффективные: CountVectorizer и TF-IDF
- Глубокое Понимание: Word Embeddings (Word2Vec‚ GloVe‚ FastText‚ Doc2Vec)
- Распознавание Именованных Сущностей (NER): Выделение Важного
- Анализ Тональности (Sentiment Analysis): Понимание Эмоций
- Тематическое Моделирование: Открытие Скрытых Смыслов
- Извлечение Ключевых Фраз: RAKE и TextRank
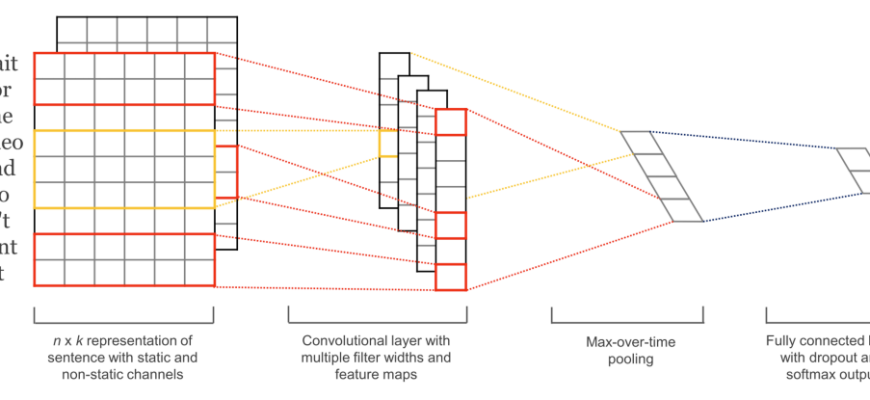
- Трансформеры и Глубокое Обучение в NLP: Новый Уровень Понимания
- Практические Приложения и Инструменты: От Веб-Скрейпинга до Чат-Ботов
- Сбор Данных: Beautiful Soup и PyMuPDF
- Многоязычный NLP: Polyglot‚ Stanza
- Создание Интеллектуальных Систем: Чат-боты и QA
- Анализ и Визуализация: Word Clouds‚ Heatmaps и Sweetviz
- Продвинутые Темы и Нишевые Приложения
Расшифровка Языка Машин: Наш Путеводитель по Магии NLP с Python
Дорогие читатели‚ когда мы оглядываемся на путь‚ который прошли в мире технологий‚ одна область всегда заставляла нас замирать от восхищения — это обработка естественного языка‚ или NLP. Представьте себе: машины‚ которые не просто обрабатывают данные‚ а понимают человеческую речь‚ анализируют её‚ а иногда даже генерируют свою собственную‚ неотличимую от нашей. Это уже не фантастика‚ а повседневная реальность‚ в которой мы активно участвуем‚ создавая и исследуя новые горизонты. Наш опыт показывает‚ что Python стал бесспорным королем в этой области‚ предоставляя разработчикам и исследователям невероятно мощные и гибкие инструменты.
В этой статье мы хотим поделиться с вами нашим глубоким погружением в мир NLP‚ рассказать о ключевых концепциях‚ мощных библиотеках и практических приложениях‚ которые мы освоили и успешно внедрили. Мы покажем вам‚ как мы преобразуем сырой текст в ценные инсайты‚ решаем сложные задачи и строим интеллектуальные системы‚ способные взаимодействовать с миром так‚ как мы и мечтали. Приготовьтесь к увлекательному путешествию‚ где мы раскроем секреты токенизации‚ стемминга‚ тематического моделирования‚ распознавания сущностей и многого другого‚ используя самые передовые Python-библиотеки.
Фундамент Понимания: Токенизация‚ Стемминг и Лемматизация
Прежде чем машина сможет "понять" текст‚ его необходимо подготовить. Этот этап‚ который мы называем предобработкой‚ является краеугольным камнем любого NLP-проекта. Мы всегда начинаем с того‚ что разбиваем текст на более мелкие‚ осмысленные единицы. Этот процесс известен как токенизация. Представьте себе предложение: "Мы любим изучать NLP". Для компьютера это просто строка символов. Но когда мы применяем токенизацию‚ оно превращается в список слов: ["Мы"‚ "любим"‚ "изучать"‚ "NLP"]‚ или даже на уровне предложений.
В нашей практике мы часто используем библиотеку NLTK (Natural Language Toolkit) для таких базовых операций. Она предоставляет множество алгоритмов для токенизации‚ позволяя нам выбирать наиболее подходящий для конкретной задачи – будь то токенизация по словам‚ предложениям или даже более сложным правилам. Это первый шаг к тому‚ чтобы превратить неструктурированный поток текста в нечто‚ что можно анализировать.
После токенизации мы сталкиваемся с проблемой вариативности слов. Например‚ "бежать"‚ "бежит"‚ "бежал" – все они несут одно и то же смысловое ядро. Здесь на помощь приходят стемминг и лемматизация. Стемминг – это грубый‚ но быстрый процесс отсечения окончаний слов для приведения их к общей "основе" (стему); Мы часто используем стеммеры вроде Портера или Сноуболла из NLTK. Они работают по набору эвристических правил‚ и хотя результат может быть не всегда морфологически корректным (например‚ "красота" может стать "красот")‚ для многих задач‚ таких как поиск и индексация‚ этого вполне достаточно.
Однако‚ когда нам требуется более точное лингвистическое представление‚ мы обращаемся к лемматизации. В отличие от стемминга‚ лемматизация стремится привести слово к его словарной форме (лемме)‚ учитывая при этом часть речи и контекст. Например‚ "лучше" будет лемматизировано до "хорошо"‚ а не просто обрезано. Для этого мы активно используем spaCy‚ которая предлагает высокопроизводительные и точные модели для лемматизации различных языков‚ включая русский. Это позволяет нам сохранять семантическую целостность текста‚ что критически важно для глубокого анализа.
Регулярные Выражения: Хирургическая Точность в Предобработке
Помимо специализированных библиотек‚ в нашем арсенале всегда есть регулярные выражения (re). Это мощный инструмент для поиска‚ замены и извлечения текстовых паттернов. Мы используем их для удаления лишних символов‚ HTML-тегов‚ ссылок‚ знаков пунктуации или для извлечения конкретных данных‚ таких как даты‚ номера телефонов или адреса электронной почты. С их помощью мы можем "очистить" данные‚ сделав их пригодными для дальнейшего анализа.
Например‚ для удаления HTML-тегов из веб-страниц‚ которые мы собираем с помощью Beautiful Soup‚ мы используем регулярные выражения‚ чтобы оставить только чистый текст. Это позволяет нам сосредоточиться на содержании‚ а не на форматировании‚ что существенно улучшает качество наших моделей.
От Слов к Числам: Векторизация и Представления Текста
Компьютеры не "понимают" слова в том смысле‚ в каком понимаем их мы. Для них это просто последовательность символов. Чтобы машины могли работать с текстом‚ нам необходимо преобразовать его в числовой формат — векторы. Это ключевой этап‚ который позволяет применять алгоритмы машинного обучения к текстовым данным. Мы используем различные подходы для векторизации‚ каждый из которых имеет свои преимущества и области применения.
Простые‚ но Эффективные: CountVectorizer и TF-IDF
Начинаем мы часто с простых‚ но очень эффективных методов. CountVectorizer из библиотеки Scikit-learn позволяет нам создать матрицу‚ где каждая строка представляет документ‚ а каждый столбец – уникальное слово (термин) из всего корпуса текстов. Значение в ячейке показывает‚ сколько раз данное слово встречается в документе. Это простой способ подсчета частотности слов‚ который уже дает машине представление о содержании.
Однако простое количество слов не всегда отражает их значимость. Слово "и" или "в" встречается часто‚ но не несет много информации. Здесь в игру вступает TF-IDF (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает частоту слова в документе (TF)‚ но и его редкость во всем корпусе (IDF). Чем реже слово встречается в других документах‚ тем выше его "вес" в данном конкретном документе. Мы активно применяем TF-IDF для задач классификации и поиска‚ поскольку он отлично выделяет наиболее значимые слова для каждого документа.
"Язык – это дорожная карта культуры. Он говорит вам‚ откуда пришли его люди и куда они идут."
, Рита Мэй Браун
Именно поэтому наше стремление научить машины понимать язык так важно – мы даём им возможность читать эти карты.
Глубокое Понимание: Word Embeddings (Word2Vec‚ GloVe‚ FastText‚ Doc2Vec)
Современные задачи NLP требуют более глубокого понимания семантики слов. Простое подсчитывание частоты не улавливает смысловых связей между словами. Здесь на сцену выходят Word Embeddings, векторные представления слов‚ которые кодируют их семантическое и синтаксическое значение. Мы были свидетелями революции‚ когда появились такие модели‚ как Word2Vec и GloVe.
С помощью библиотеки Gensim мы обучали свои собственные модели Word2Vec (Skip-gram и CBOW) на больших текстовых корпусах. Это позволило нам получать векторы слов‚ где семантически близкие слова (например‚ "король" и "королева") расположены близко друг к другу в многомерном пространстве. А такие операции‚ как "король ‒ мужчина + женщина = королева"‚ стали реальностью! Мы также использовали GloVe‚ который строит эмбеддинги на основе глобальной статистики совместной встречаемости слов.
Для работы с редкими словами и морфологически богатыми языками‚ где Word2Vec и GloVe могут испытывать трудности‚ мы активно применяем FastText. Эта модель учитывает не только целые слова‚ но и их подслова (n-граммы символов)‚ что позволяет ей генерировать осмысленные векторы даже для слов‚ не встречавшихся в обучающем корпусе.
Когда же нам нужно получить векторное представление для целых предложений или документов‚ мы обращаемся к Doc2Vec (расширение Word2Vec) или Sentence Transformers. Эти методы позволяют нам сравнивать документы по их смысловому содержанию‚ что невероятно полезно для поиска похожих статей‚ кластеризации текстов или построения рекомендательных систем.
Распознавание Именованных Сущностей (NER): Выделение Важного
Одной из самых захватывающих задач в NLP для нас является Распознавание Именованных Сущностей (NER). Это процесс идентификации и классификации именованных сущностей в тексте‚ таких как имена людей‚ названия организаций‚ географические объекты‚ даты‚ денежные суммы и т.д.. Представьте‚ сколько ценной информации можно извлечь из простого текста‚ если машина способна автоматически находить и категоризировать эти элементы!
Для быстрого и эффективного NER мы регулярно используем spaCy. Её предварительно обученные модели (для английского‚ русского и многих других языков) обладают высокой точностью и скоростью. Мы часто применяем spaCy для первоначального извлечения сущностей из больших объемов текста‚ например‚ из новостных статей или отчетов.
| Инструмент | Преимущества | Недостатки/Особенности | Типичные задачи |
|---|---|---|---|
| spaCy | Высокая скорость‚ предварительно обученные модели‚ простота использования‚ поддержка многих языков. | Менее гибок для очень специфичных сущностей без дообучения. | Быстрое извлечение PERSON‚ ORG‚ LOC‚ DATE из общих текстов. |
| Flair | Современные‚ state-of-the-art модели‚ контекстуальные эмбеддинги‚ отличная точность‚ гибкость в дообучении. | Может быть медленнее spaCy‚ требует больше ресурсов. | Высокоточный NER‚ работа с нестандартными сущностями. |
| CRF (Conditional Random Fields) | Классический‚ но очень мощный метод‚ хорошо работает с признаками‚ не требует огромных данных для обучения. | Требует ручного извлечения признаков‚ не так "глубок"‚ как нейросети. | NER на небольших‚ специфичных наборах данных‚ когда нет готовых моделей. |
| BERT (с Hugging Face) | Максимальная точность‚ понимание контекста‚ возможность тонкой настройки под любую задачу. | Требует значительных вычислительных ресурсов‚ сложнее в освоении для новичков. | State-of-the-art NER для сложных и специализированных доменов. |
Для более продвинутых задач‚ особенно когда стандартные сущности недостаточны или нам нужна максимальная точность‚ мы переходим к библиотеке Flair или используем трансформерные модели‚ такие как BERT‚ через фреймворк Hugging Face Transformers. Flair‚ с его контекстуальными строковыми эмбеддингами‚ часто демонстрирует поразительные результаты‚ а BERT‚ после тонкой настройки (fine-tuning) на наших данных‚ позволяет нам достигать уровня точности‚ который был недостижим всего несколько лет назад. Мы применяем NER для анализа юридических документов‚ извлечения ключевых данных из финансовых отчетов и даже для автоматической категоризации статей.
Анализ Тональности (Sentiment Analysis): Понимание Эмоций
В современном мире‚ переполненном текстами — от отзывов клиентов до постов в социальных сетях, способность понять эмоциональный окрас сообщения является бесценной. Анализ тональности (Sentiment Analysis) — это область NLP‚ которая позволяет нам определять‚ является ли текст позитивным‚ негативным или нейтральным. Это мощный инструмент для мониторинга репутации бренда‚ анализа обратной связи и понимания общественного мнения.
Для быстрых и простых задач анализа тональности‚ особенно на английском языке‚ мы часто используем библиотеку VADER (Valence Aware Dictionary and sEntiment Reasoner). VADER уникален тем‚ что он разработан специально для социальных медиа и способен учитывать знаки пунктуации‚ использование заглавных букв и эмодзи‚ которые сильно влияют на тональность. Мы применяем его для анализа тональности сообщений в Twitter или Reddit.
Для более глубокого анализа и работы с русскоязычным текстом или специфическими доменами‚ где VADER может быть не так эффективен‚ мы разрабатываем собственные модели. Это может быть классификация текста с использованием Scikit-learn (например‚ SVM или наивный байесовский классификатор) на предварительно размеченных данных‚ или даже тонкая настройка моделей BERT. Мы также используем TextBlob для простого NLP‚ включая базовый анализ тональности‚ хотя для серьезных проектов мы предпочитаем более мощные инструменты.
Одной из сложных‚ но интересных задач‚ с которой мы сталкивались‚ является анализ тональности с учетом сарказма или иронии. Это требует не только понимания слов‚ но и контекста‚ а иногда и культурных нюансов. Для таких случаев мы исследуем более продвинутые трансформерные архитектуры‚ способные улавливать тонкие смысловые оттенки.
Тематическое Моделирование: Открытие Скрытых Смыслов
Представьте‚ что у вас есть огромный корпус текстов – тысячи новостных статей‚ научных публикаций или отзывов клиентов. Как понять‚ о чем эти тексты? Здесь на помощь приходит тематическое моделирование. Это класс алгоритмов‚ которые позволяют нам автоматически обнаруживать скрытые "темы" или "топики" в коллекции документов‚ без необходимости ручной разметки. Для нас это как волшебная палочка‚ которая проявляет невидимые связи.
Мы активно используем библиотеку Gensim‚ которая является нашим незаменимым помощником в этой области. Два наиболее популярных алгоритма‚ которые мы применяем:
- LDA (Latent Dirichlet Allocation): Это‚ пожалуй‚ самый известный алгоритм тематического моделирования. LDA предполагает‚ что каждый документ является смесью нескольких тем‚ а каждая тема – это смесь слов; Мы обучаем модель LDA на нашем корпусе‚ и она выявляет N тем‚ каждая из которых представлена набором наиболее характерных слов. Это позволяет нам быстро понять основные смысловые блоки в больших коллекциях текстов.
- LSI (Latent Semantic Indexing): Хотя LSI является более старым методом‚ он по-прежнему эффективен для некоторых задач. Он основан на сингулярном разложении (SVD) матрицы "слова-документы" и позволяет выявить скрытые семантические структуры. Мы часто сравниваем результаты LDA и LSI‚ чтобы получить более полное представление о тематической структуре данных.
Мы также исследуем и применяем NMF (Non-negative Matrix Factorization) для тематического моделирования‚ особенно когда требуется более интерпретируемые результаты. Сравнение моделей тематического моделирования (LDA vs NMF) часто становится частью нашего рабочего процесса‚ чтобы выбрать оптимальный подход для конкретного проекта. Например‚ мы использовали тематическое моделирование для анализа отзывов о продуктах‚ выявляя ключевые аспекты‚ которые волнуют клиентов.
Извлечение Ключевых Фраз: RAKE и TextRank
Помимо общих тем‚ часто возникает потребность в извлечении наиболее важных слов или фраз из отдельного документа. Для этого мы используем такие алгоритмы‚ как RAKE (Rapid Automatic Keyword Extraction) и TextRank. RAKE — это быстрый и эффективный алгоритм для извлечения ключевых слов на основе частотности и совместной встречаемости слов. TextRank‚ вдохновленный PageRank‚ строит граф слов и ранжирует их по важности‚ что позволяет нам не только извлекать ключевые слова‚ но и даже ключевые предложения для суммаризации. Мы активно применяем TextRank для суммаризации текста и выделения тем в статьях.
Трансформеры и Глубокое Обучение в NLP: Новый Уровень Понимания
Если Word Embeddings стали революцией‚ то трансформерные архитектуры произвели настоящий взрыв в мире NLP. Мы были поражены возможностями‚ которые открылись с появлением таких моделей‚ как BERT‚ GPT и их многочисленных производных. Эти модели способны улавливать сложнейшие контекстуальные зависимости в тексте‚ что позволило достичь беспрецедентной точности в самых разнообразных задачах.
Для работы с трансформерами мы используем библиотеку Hugging Face Transformers‚ которая предоставляет доступ к сотням предварительно обученных моделей и удобные инструменты для их тонкой настройки. Мы применяем BERT для задач классификации текста‚ распознавания именованных сущностей (NER) и даже для выявления связей между сущностями.
Особенно захватывающим направлением является использование трансформерных моделей для генерации текста. Мы экспериментировали с GPT-подобными моделями для создания диалогов‚ суммаризации текста и даже генерации кода. Возможность тонкой настройки (Fine-tuning) предварительно обученных моделей на наших специфических данных позволяет нам достигать выдающихся результатов‚ создавая системы‚ которые ранее казались фантастикой.
Мы также используем фреймворки PyTorch/TensorFlow для создания собственных нейросетей NLP‚ когда требуется максимальная гибкость и контроль над архитектурой. Это позволяет нам исследовать передовые методы‚ такие как LSTM-сети‚ для решения уникальных задач‚ требующих глубокого последовательного понимания текста.
Практические Приложения и Инструменты: От Веб-Скрейпинга до Чат-Ботов
Теория без практики мертва. Наш блог посвящен реальному опыту‚ и поэтому мы хотим поделиться тем‚ как мы применяем все эти знания и инструменты для решения повседневных и сложных задач.
Сбор Данных: Beautiful Soup и PyMuPDF
Первый шаг в любом NLP-проекте – это получение данных. Если текст находится в интернете‚ мы обращаемся к библиотеке Beautiful Soup для веб-скрейпинга. Она позволяет нам удобно парсить HTML-страницы‚ извлекать нужные текстовые блоки и подготавливать их к дальнейшей обработке.
Когда же источник данных – PDF-документы‚ мы используем PyMuPDF (или Fitz). Эта библиотека позволяет нам эффективно извлекать текст из PDF-файлов‚ сохраняя структуру‚ что критически важно для анализа юридических или научных документов.
Многоязычный NLP: Polyglot‚ Stanza
Мир не ограничивается английским языком. В нашей практике мы постоянно сталкиваемся с необходимостью обработки многоязычных текстовых корпусов. Для этого мы используем:
- Polyglot: Отличная библиотека для мультиязычности‚ которая поддерживает множество языков для токенизации‚ NER‚ анализа тональности и определения языка. Мы часто применяем ее для анализа редких языков‚ для которых нет специализированных моделей.
- Stanza (StanfordNLP): Мощный инструмент‚ особенно хорош для языков с богатой морфологией‚ таких как русский. Stanza предоставляет state-of-the-art модели для токенизации‚ POS-теггинга‚ лемматизации и синтаксического парсинга‚ что делает ее незаменимой для глубокого лингвистического анализа.
Создание Интеллектуальных Систем: Чат-боты и QA
Одной из самых амбициозных задач‚ которые мы решаем‚ является разработка чат-ботов на Python. Мы используем фреймворк Rasa‚ который предоставляет все необходимое для создания диалоговых систем‚ способных понимать намерения пользователя и управлять диалогом. Это включает в себя не только NLP-компоненты для понимания естественного языка (NLU)‚ но и механизмы управления диалогом.
Мы также работаем над системами вопросно-ответных систем (QA). Это системы‚ которые могут отвечать на вопросы‚ основываясь на заданном корпусе текстов. Здесь трансформерные модели‚ такие как BERT‚ играют ключевую роль‚ позволяя нам находить точные ответы в больших объемах информации.
Анализ и Визуализация: Word Clouds‚ Heatmaps и Sweetviz
Полученные данные должны быть не только обработаны‚ но и представлены в понятном виде. Мы используем различные инструменты для визуализации текстовых данных. Word Clouds (облака слов) – это простой и эффектный способ показать наиболее часто встречающиеся слова. Для более глубокого анализа мы строим Heatmaps (тепловые карты)‚ чтобы визуализировать‚ например‚ корреляции между темами или словами.
Для быстрого и полного анализа текстовых данных мы недавно открыли для себя библиотеку Sweetviz‚ которая автоматически генерирует подробные отчеты с визуализациями‚ что очень удобно для первоначального исследования данных.
Продвинутые Темы и Нишевые Приложения
Мир NLP постоянно развивается‚ и мы всегда стремимся быть на передовой. Вот несколько продвинутых тем и нишевых приложений‚ в которых мы активно работаем:
- Анализ стилистики текстов (авторский почерк): Мы разрабатываем системы для определения авторства текста‚ анализируя уникальные лексические‚ синтаксические и морфологические паттерны. Это находит применение в криминалистике и литературоведении.
- Работа с эмодзи и сленгом: Современные тексты‚ особенно в социальных сетях‚ изобилуют эмодзи и сленгом. Мы разрабатываем инструменты для нормализации сленга и учета эмоциональной нагрузки эмодзи в анализе тональности.
- Анализ юридических и медицинских документов: Эти области требуют высокой точности и специфического понимания терминологии. Мы используем Python для извлечения ключевых фактов‚ дат‚ имен из юридических контрактов и медицинских записей.
- Системы обнаружения плагиата: С помощью методов сравнения строк (например‚ с использованием библиотеки Jellyfish) и векторных представлений документов (Doc2Vec‚ Sentence Transformers) мы создаем системы‚ способные выявлять схожесть текстов и обнаруживать плагиат.
- Обработка больших текстовых массивов (Big Data NLP): Когда речь идет о терабайтах текста‚ стандартные подходы могут быть неэффективны. Мы исследуем и применяем распределенные вычисления и оптимизированные библиотеки (например‚ Gensim для анализа больших данных) для обработки таких объемов.
- Разработка инструментов для проверки грамматики и орфографии: Мы создаем собственные модули для исправления опечаток и грамматических ошибок‚ используя методы на основе n-грамм‚ лексических словарей и языковых моделей.
Проделав этот путь по миру NLP‚ мы видим‚ насколько далеко мы продвинулись. От базовых операций вроде токенизации и стемминга до сложных трансформерных моделей‚ способных генерировать связный и осмысленный текст — каждый шаг открывает новые горизонты. Python‚ с его богатой экосистемой библиотек‚ таких как NLTK‚ spaCy‚ Gensim‚ Scikit-learn и Hugging Face Transformers‚ остается нашим верным спутником в этом увлекательном путешествии.
Мы убеждены‚ что будущее NLP за еще более глубоким пониманием контекста‚ мультимодальными моделями (объединяющими текст‚ изображение‚ звук) и‚ конечно же‚ за созданием по-настоящему интеллектуальных агентов‚ способных взаимодействовать с нами нашими же языками. Мы продолжаем экспериментировать‚ учиться и делиться своими открытиями‚ ведь нет ничего более вдохновляющего‚ чем видеть‚ как машины начинают понимать мир так‚ как понимаем его мы. И наш блог всегда будет местом‚ где мы рассказываем об этих приключениях.
Подробнее: 10 LSI запросов
| Основы токенизации NLTK | Сравнение TF-IDF Word2Vec | Применение BERT для NER | Анализ тональности с VADER | Тематическое моделирование LDA Gensim |
| Продвинутая лемматизация spaCy | Разработка чат-ботов Rasa | Трансформеры Hugging Face | Извлечение ключевых слов TextRank | Обработка многоязычных корпусов Stanza |





