
- Раскрываем Тайны Текста: Наш Путь в Мире NLP с Python
- Первые Шаги: От Сырого Текста к Понятным Данным
- NLTK: Наш Верный Спутник в Основах NLP
- Магия Регулярных Выражений
- Когда NLTK Не Хватает: Мощные Библиотеки в Деле
- spaCy: Скорость и Точность для Продакшена
- TextBlob: Простота для Быстрых Задач
- Векторизация Текста: Говорим с Машинами на Их Языке
- Классические Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: От Слов к Смыслам
- Погружение в Смысл: От Тональности до Темы
- Анализ Тональности (Sentiment Analysis): Чувства в Коде
- Тематическое Моделирование: Выявление Скрытых Смыслов
- Извлечение Ключевых Фраз и Суммаризация
- Эра Трансформеров и Глубокого Обучения в NLP
- Hugging Face и Предварительно Обученные Модели
- Контекстное Встраивание и Flair
- Практические Приложения и Инструменты
- Работа с Различными Типами Данных
- Многоязычность и Редкие Языки
- Создание Интеллектуальных Систем
- Вызовы и Перспективы
- Работа с Несовершенными Данными
- Визуализация и Оценка Качества
- Будущее NLP: Генерация и Глубокое Понимание
Раскрываем Тайны Текста: Наш Путь в Мире NLP с Python
Привет‚ дорогие читатели и коллеги по цеху! С вами снова мы‚ команда‚ которая уже не первый год погружается в захватывающий мир обработки естественного языка‚ или как его принято называть‚ NLP. Если вы когда-либо задумывались‚ как машины понимают‚ что мы пишем‚ как они отвечают на наши вопросы или даже генерируют связные тексты‚ то эта статья для вас. Мы собрали весь наш многолетний опыт‚ наши шишки и наши прорывы‚ чтобы поделиться с вами комплексным руководством по NLP с использованием Python.
За годы работы мы видели‚ как эта область стремительно развивалась: от простых алгоритмов стемминга до сложных трансформерных моделей‚ способных генерировать тексты‚ неотличимые от человеческих. Наш путь начался с любопытства и желания заставить компьютер "понять" обычный текст‚ и это привело нас к созданию удивительных инструментов и систем. Мы хотим показать вам‚ что NLP — это не просто набор сложных алгоритмов‚ а мощный инструмент‚ способный преобразить то‚ как мы взаимодействуем с информацией.
Первые Шаги: От Сырого Текста к Понятным Данным
Любое путешествие в NLP начинается с подготовки данных. Текст‚ каким мы его видим‚ для компьютера — это просто последовательность символов. Чтобы он стал чем-то осмысленным‚ его нужно обработать. Это похоже на то‚ как мы‚ люди‚ учимся читать: сначала буквы‚ потом слова‚ предложения‚ и только потом смысл. Для машин этот процесс называется предобработкой.
NLTK: Наш Верный Спутник в Основах NLP
Когда мы только начинали‚ библиотека NLTK (Natural Language Toolkit) была и остается нашим незаменимым помощником. Она предоставляет огромное количество инструментов для работы с текстом на самых базовых уровнях. Мы часто используем её для таких фундаментальных операций‚ как токенизация и стемминг.
Токенизация – это процесс разбиения текста на отдельные единицы‚ или "токены". Чаще всего токенами являются слова или знаки препинания. Например‚ предложение "Мы любим NLP!" после токенизации может превратиться в список ["Мы"‚ "любим"‚ "NLP"‚ "!"]. Мы всегда начинаем с этого шага‚ ведь без него сложно двигаться дальше.
Стемминг – это упрощение слова до его "корня" или основы. Например‚ слова "бежать"‚ "бежит"‚ "бежал" могут быть сведены к одному и тому же "беж". Это помогает уменьшить количество уникальных слов в тексте‚ что упрощает дальнейший анализ. Однако‚ как мы убедились на собственном опыте‚ стемминг может быть довольно агрессивным и иногда обрезать слово слишком сильно‚ теряя его истинное значение.
Для более точной обработки мы часто обращаемся к лемматизации. В отличие от стемминга‚ лемматизация стремится привести слово к его словарной форме (лемме) с учетом морфологии языка. Например‚ "бежал" превратится в "бежать"‚ а не в "беж". Это гораздо полезнее для многих задач‚ особенно когда точность значения слова критична. Мы используем как NLTK‚ так и spaCy для продвинутой лемматизации и стемминга‚ выбирая инструмент в зависимости от языка и требуемой глубины анализа.
Магия Регулярных Выражений
Предобработка текста не обходится без регулярных выражений (re). Это мощный инструмент в Python‚ который позволяет нам находить‚ извлекать и заменять фрагменты текста по сложным шаблонам. Мы часто используем их для:
- Удаления HTML-тегов из веб-страниц‚ полученных через веб-скрейпинг (о нем чуть позже).
- Очистки данных от нежелательных символов‚ таких как эмодзи‚ сленг или специальные символы.
- Извлечения дат‚ чисел‚ адресов электронной почты и других структурированных данных из неструктурированного текста.
- Нормализации пунктуации‚ чтобы‚ например‚ "точка с запятой" всегда была одним токеном‚ а не двумя.
Наш опыт показывает‚ что умение работать с `re` – это как владение волшебной палочкой для очистки и структурирования текстовых данных. Это один из первых навыков‚ которые мы оттачивали‚ и он до сих пор остается краеугольным камнем в нашей работе.
Когда NLTK Не Хватает: Мощные Библиотеки в Деле
Хотя NLTK прекрасен для основ‚ для более сложных и быстрых задач мы переходим к другим инструментам. Каждый из них имеет свои преимущества‚ и мы научились выбирать подходящий для конкретной проблемы.
spaCy: Скорость и Точность для Продакшена
spaCy – это библиотека‚ которая быстро завоевала наше доверие благодаря своей скорости и эффективности‚ особенно когда речь идет о развертывании моделей в продакшене. Мы активно используем spaCy для:
- Распознавания именованных сущностей (NER): Это одна из самых впечатляющих возможностей spaCy. Она позволяет нам автоматически находить и классифицировать сущности в тексте‚ такие как имена людей‚ организации‚ локации‚ даты. Например‚ из предложения "Тим Кук посетил Москву 15 мая" spaCy может выделить "Тим Кук" как PERSON‚ "Москву" как GPE (геополитическая сущность) и "15 мая" как DATE. Это критически важно для извлечения информации и построения баз знаний.
- Синтаксического парсинга: spaCy позволяет нам анализировать грамматическую структуру предложений‚ определяя зависимости между словами. Это помогает понять‚ кто что делает‚ с кем‚ где и когда‚ что является основой для создания вопросно-ответных систем и более глубокого понимания текста.
- POS-теггинга (Part-of-Speech Tagging): Определение частей речи для каждого слова (существительное‚ глагол‚ прилагательное и т.д.). Это не только базовый шаг для многих задач‚ но и отличный способ улучшить качество стемминга или лемматизации‚ применяя правила только к определенным частям речи.
Наш опыт показывает‚ что spaCy особенно хорош‚ когда нужна высокая производительность и готовые‚ предварительно обученные модели для различных языков‚ включая русский. Мы часто используем его‚ когда нужно быстро создать прототип или внедрить решение в реальное приложение.
TextBlob: Простота для Быстрых Задач
Для простых и быстрых задач‚ особенно на начальных этапах проекта или для быстрого анализа‚ мы часто обращаемся к TextBlob. Эта библиотека является надстройкой над NLTK и предоставляет очень удобный API для выполнения распространенных операций:
- Определение языка текста.
- Перевод текста.
- Базовый анализ тональности.
- Извлечение n-грамм.
Однако‚ со временем мы осознали и её ограничения. Для действительно сложных задач TextBlob может быть недостаточно точным или гибким. В таких случаях мы переключаемся на более мощные и специализированные библиотеки‚ но для быстрого старта она незаменима.
Векторизация Текста: Говорим с Машинами на Их Языке
Компьютеры не понимают слова в их лингвистическом смысле. Чтобы они могли работать с текстом‚ его нужно преобразовать в числовой формат – векторы. Это называется векторизацией‚ и это один из ключевых этапов в любом проекте NLP. Мы прошли долгий путь от простых методов до самых современных.
Классические Векторизаторы: CountVectorizer и TF-IDF
Наше знакомство с векторизацией началось с двух фундаментальных методов из библиотеки Scikit-learn:
- CountVectorizer: Этот векторизатор просто подсчитывает частоту вхождения каждого слова в документе. Создается словарь всех уникальных слов в корпусе‚ и каждый документ представляется как вектор‚ где каждый элемент – это количество вхождений соответствующего слова из словаря; Просто‚ но эффективно для многих задач.
- TfidfVectorizer (Term Frequency-Inverse Document Frequency): Это более продвинутый метод. Он не только учитывает частоту слова в документе (TF)‚ но и его редкость во всем корпусе (IDF). Слова‚ которые часто встречаются во многих документах (например‚ "и"‚ "в"‚ "на")‚ получают меньший вес‚ а слова‚ уникальные для конкретного документа‚ получают больший. Это помогает выделить наиболее важные слова.
Мы часто используем эти векторизаторы для задач классификации текстов‚ когда нужно определить категорию документа (например‚ "спорт"‚ "политика"‚ "технологии"). Scikit-learn предоставляет мощный набор инструментов для классификации‚ включая SVM‚ наивный байесовский классификатор и другие‚ которые мы успешно применяли.
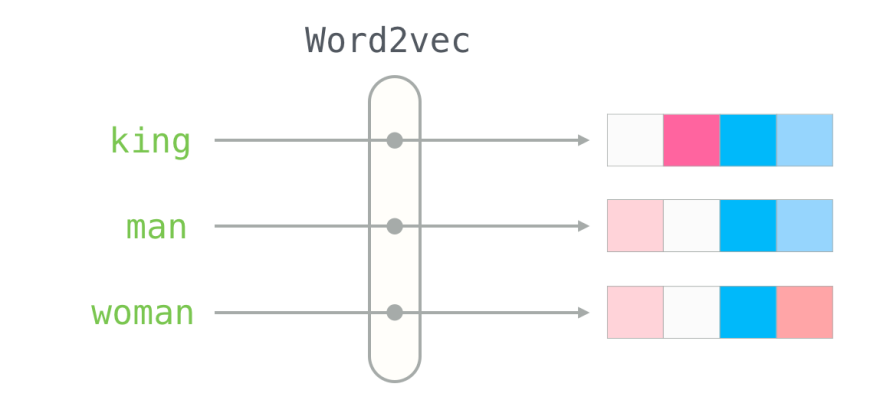
Word Embeddings: От Слов к Смыслам
Классические векторизаторы не учитывают семантическое значение слов. "Кошка" и "собака" для них так же далеки‚ как "кошка" и "телефон". Здесь на помощь приходят Word Embeddings – это плотные векторные представления слов‚ которые улавливают их семантические и синтаксические отношения. Слова со схожим значением располагаются близко друг к другу в многомерном пространстве.
Мы активно работали с двумя пионерами в этой области:
- Word2Vec (с использованием Gensim): Этот алгоритм‚ разработанный Google‚ стал революцией. Мы использовали его для обучения собственных векторов на больших текстовых корпусах. Он имеет два основных подхода: Skip-gram (предсказывает контекстные слова по целевому слову) и CBOW (предсказывает целевое слово по контексту).
- GloVe (Global Vectors for Word Representation): Разработанный в Стэнфорде‚ GloVe сочетает в себе идеи Word2Vec и матричной факторизации‚ опираясь на глобальную статистику частотности слов.
Библиотека Gensim стала для нас незаменимым инструментом для работы с Word Embeddings‚ а также для других задач‚ таких как тематическое моделирование (LDA‚ LSI). Она позволяет эффективно работать с большими текстовыми массивами и обучать модели на значительных объемах данных.
Помимо отдельных слов‚ мы также освоили векторизацию предложений и документов. Методы вроде Doc2Vec (расширение Word2Vec) позволяют получать плотные векторные представления для целых предложений или документов‚ что открывает двери для сравнения документов‚ поиска похожих статей или анализа поведенческих паттернов в чатах.
Погружение в Смысл: От Тональности до Темы
После того‚ как мы научились представлять текст в числовом виде‚ мы можем начинать извлекать из него более глубокие смыслы. Это включает понимание эмоций‚ выявление ключевых тем и даже генерацию новых текстов.
Анализ Тональности (Sentiment Analysis): Чувства в Коде
Одной из самых востребованных задач в NLP является анализ тональности. Это позволяет нам понять‚ является ли текст позитивным‚ негативным или нейтральным. Мы применяем его для анализа отзывов клиентов‚ постов в социальных сетях‚ финансовых новостей и многого другого.
Наш опыт включает использование различных инструментов:
- VADER (Valence Aware Dictionary and sEntiment Reasoner): Специально разработан для анализа тональности в социальных медиа. Он учитывает не только слова‚ но и использование заглавных букв‚ восклицательных знаков и эмодзи‚ что делает его очень эффективным для неформального текста. Мы часто применяем его для анализа тональности сообщений в Twitter/Reddit.
- TextBlob: Как мы упоминали‚ TextBlob предлагает простой API для анализа тональности‚ что удобно для быстрых оценок.
- Машинное обучение: Для более сложных задач и специфичных доменов мы обучаем собственные модели классификации (SVM‚ наивный байесовский классификатор‚ логистическая регрессия) на размеченных данных. Это позволяет нам адаптироваться к нюансам языка и контекста‚ например‚ для анализа тональности финансовых новостей‚ где значение слов может сильно отличаться от бытового.
Особую сложность представляет анализ тональности с учетом сарказма или иронии. Это та область‚ где даже современные модели сталкиваются с трудностями‚ и где человеческий фактор в разметке данных остается критически важным.
Тематическое Моделирование: Выявление Скрытых Смыслов
Представьте‚ что у вас есть тысячи документов‚ и вам нужно понять‚ о чем они. Перечитывать каждый – не вариант. Здесь на помощь приходит тематическое моделирование – набор алгоритмов‚ которые позволяют автоматически выявлять скрытые темы в большом корпусе текстов.
Мы активно используем:
- LDA (Latent Dirichlet Allocation): Один из самых популярных алгоритмов. Он предполагает‚ что каждый документ состоит из смеси нескольких тем‚ а каждая тема – это распределение слов. Мы применяем Gensim для эффективной реализации LDA на больших данных.
- LSI (Latent Semantic Indexing): Также доступен через Gensim. LSI использует сингулярное разложение (SVD) для выявления скрытых семантических структур.
Мы часто сравниваем модели тематического моделирования (LDA vs NMF)‚ чтобы понять‚ какая из них лучше подходит для конкретной задачи и типа данных. Это позволяет нам‚ например‚ анализировать отзывы о продуктах по категориям‚ выявлять скрытые темы в статьях или даже анализировать поведенческие паттерны в пользовательских запросах.
"Язык – это дорожная карта культуры. Он говорит вам‚ откуда люди пришли и куда они идут." – Рита Мэй Браун
Эта цитата прекрасно отражает нашу философию. Работая с NLP‚ мы не просто обрабатываем данные; мы пытаемся понять язык как проявление человеческой культуры и мышления‚ чтобы затем научить машины взаимодействовать с этим богатым наследием.
Извлечение Ключевых Фраз и Суммаризация
Для быстрого понимания сути документа мы используем методы извлечения ключевых фраз. Мы работали с такими инструментами‚ как RAKE (Rapid Automatic Keyword Extraction)‚ который эффективно выделяет наиболее значимые слова и фразы. Также‚ мы применяем TextRank – алгоритм‚ основанный на PageRank‚ который может использоваться как для извлечения ключевых слов‚ так и для суммаризации текста путем выделения наиболее важных предложений.
Суммаризация текста – еще одна захватывающая область. Мы различаем два основных подхода:
- Экстрактивная суммаризация: Выбирает наиболее важные предложения из исходного текста и объединяет их. Это как выделить главное маркером.
- Абстрактивная суммаризация: Генерирует совершенно новый текст‚ который передает основной смысл исходного документа. Это гораздо сложнее и часто требует использования продвинутых нейронных сетей.
Сравнение моделей суммирования‚ экстрактивной и абстрактной‚ всегда показывает‚ что каждая из них имеет свои сильные и слабые стороны‚ и выбор зависит от конкретной задачи и объема исходного текста.
Эра Трансформеров и Глубокого Обучения в NLP
Последние годы ознаменовались настоящим прорывом в NLP благодаря архитектуре трансформеров и глубокому обучению. Эти технологии изменили правила игры‚ позволив создавать системы‚ которые ранее казались фантастикой.
Hugging Face и Предварительно Обученные Модели
Когда мы говорим о современных задачах NLP‚ мы не можем обойти стороной библиотеку Hugging Face Transformers. Это настоящая сокровищница предварительно обученных моделей (BERT‚ GPT‚ RoBERTa и многих других)‚ которые значительно упрощают разработку сложных NLP-систем. Мы используем их для:
- Сложных задач NER: Трансформеры значительно превосходят классические подходы в точности распознавания сущностей‚ особенно на многоязычных данных.
- Классификации текстов: Тонкая настройка (Fine-tuning) предварительно обученных моделей BERT для задач классификации дает впечатляющие результаты.
- Генерации текста: Модели вроде GPT позволяют нам генерировать связные и осмысленные тексты‚ что мы используем в прототипах для чат-ботов или автоматического создания контента.
- Машинного перевода: Трансформерные архитектуры лежат в основе самых продвинутых систем машинного перевода.
- Вопросно-ответных систем (QA): Разработка QA-систем‚ способных находить точные ответы в больших документах‚ стала значительно проще благодаря трансформерам.
Работая с трансформерами‚ мы также используем библиотеки PyTorch и TensorFlow‚ которые предоставляют мощные фреймворки для создания и обучения нейронных сетей NLP. Это позволяет нам создавать собственные архитектуры или тонко настраивать существующие модели под наши специфические нужды.
Контекстное Встраивание и Flair
Традиционные Word Embeddings не учитывают контекст‚ в котором используется слово. Слово "банк" имеет разное значение в "берег банка" и "финансовый банк". Здесь на помощь приходит векторизация текста с учётом контекста (контекстное встраивание)‚ которое предоставляют трансформерные модели.
Мы также активно используем библиотеку Flair‚ которая предлагает современные методы векторизации и распознавания именованных сущностей‚ особенно когда требуется высокая точность и контекстная осведомленность. Flair также отлично подходит для работы с языками с богатой морфологией‚ такими как русский.
Практические Приложения и Инструменты
Знания без практики – ничто. Мы постоянно применяем наши навыки NLP для решения реальных задач‚ создавая полезные инструменты и системы.
Работа с Различными Типами Данных
Наш опыт включает обработку самых разнообразных текстовых данных:
| Тип Данных | Примеры Задач | Используемые Инструменты/Методы |
|---|---|---|
| Веб-страницы | Веб-скрейпинг текста‚ извлечение статей. | Beautiful Soup‚ регулярные выражения для очистки HTML-тегов. |
| PDF-документы | Извлечение текста из юридических документов‚ отчетов. | PyMuPDF‚ для анализа юридических документов – BERT для NER. |
| Отзывы клиентов | Анализ тональности‚ выявление проблемных зон‚ категоризация. | VADER‚ Scikit-learn для классификации‚ Topic Modeling (LDA/NMF). |
| Социальные сети | Анализ тональности‚ работа с эмодзи и сленгом. | VADER‚ TextBlob‚ регулярные выражения‚ Sentence Transformers. |
| Медицинские записи | Извлечение ключевой информации‚ NER. | SpaCy‚ Flair‚ специализированные модели BERT. |
Многоязычность и Редкие Языки
Мир не ограничивается английским языком. Мы активно работаем с многоязычными текстовыми корпусами. Для этого мы используем такие библиотеки‚ как Polyglot‚ которая предоставляет поддержку для множества языков‚ и Stanza (от Stanford NLP Group)‚ особенно ценную для языков с богатой морфологией‚ как русский‚ предлагая продвинутые возможности для лемматизации‚ POS-теггинга и синтаксического анализа.
Разработка систем машинного перевода на Python – это сложная‚ но невероятно интересная задача‚ где трансформерные модели показывают себя наилучшим образом. Мы также занимались созданием словарей и тезаурусов для узкоспециализированных или редких языков‚ что является фундаментом для более глубокого анализа.
Создание Интеллектуальных Систем
Наши знания и опыт позволили нам работать над созданием по-настоящему интеллектуальных систем:
- Чат-боты: Мы разрабатывали чат-боты на Python‚ используя фреймворк Rasa‚ который позволяет создавать диалоговые системы с возможностью понимания естественного языка и управления диалогом.
- Системы обнаружения плагиата: Используя библиотеки вроде Textdistance для измерения сходства строк и документов‚ мы создавали инструменты для выявления плагиата.
- Системы автоматической категоризации и тегирования: Мы разрабатываем системы‚ которые автоматически присваивают категории статьям или генерируют теги для контента‚ опираясь на тематическое моделирование и классификацию текста.
- Инструменты для проверки грамматики и орфографии: Используя комбинацию правил‚ словарей и моделей машинного обучения‚ мы создаем инструменты для улучшения качества текста.
- Разработка инструмента для автоматического перефразирования: С помощью трансформерных моделей мы исследуем возможности автоматического перефразирования текстов‚ что может быть полезно для создания уникального контента или суммаризации.
Вызовы и Перспективы
Мир NLP – это постоянное движение. Мы постоянно сталкиваемся с новыми вызовами и видим невероятные перспективы.
Работа с Несовершенными Данными
Наш практический опыт показал‚ что реальные данные редко бывают идеальными. Мы постоянно имеем дело с неполными и ошибочными данными‚ сленгом‚ опечатками‚ эмодзи‚ неструктурированным текстом из лог-файлов. Очистка данных – это часто 80% работы. Для этого мы применяем регулярные выражения‚ разрабатываем инструменты для нормализации сленга и используем библиотеки вроде Textacy для расширенного анализа текста.
Обработка больших текстовых массивов (Big Data NLP) также требует особых подходов‚ включая оптимизацию алгоритмов и использование GPU-ускорения для обучения моделей глубокого обучения.
Визуализация и Оценка Качества
Чтобы понять‚ что происходит с нашими данными и моделями‚ мы активно используем инструменты для визуализации текстовых данных‚ такие как Word Clouds‚ Heatmaps‚ а также библиотеки вроде Sweetviz для анализа текстовых данных. Это помогает нам быстро выявлять паттерны и проблемы.
Оценка качества NER-моделей (F1-score‚ Precision‚ Recall) и других систем – это наш ежедневный хлеб. Мы постоянно сравниваем различные методы векторизации (TF-IDF vs Word2Vec)‚ модели тематического моделирования (LDA vs NMF)‚ алгоритмы кластеризации (K-Means vs DBSCAN) и другие подходы‚ чтобы выбрать наиболее эффективное решение для каждой конкретной задачи.
Будущее NLP: Генерация и Глубокое Понимание
Мы видим‚ что будущее NLP за еще более сложными генеративными моделями. Использование Transformer-моделей для генерации кода‚ диалогов‚ автоматического перевода узкоспециализированных текстов – это уже не фантастика‚ а активно развивающаяся реальность. Анализ стилистики текстов‚ выявление связей между сущностями‚ разработка систем для автоматического перефразирования – все это области‚ где мы продолжаем активно работать и исследовать.
Наше путешествие в мире NLP с Python – это бесконечный процесс обучения и открытий. От первых шагов с NLTK и регулярными выражениями до освоения мощных трансформерных архитектур‚ мы прошли долгий‚ но невероятно увлекательный путь. Мы надеемся‚ что наш опыт и знания помогут вам в ваших собственных проектах и вдохновят на новые свершения. Помните‚ что каждый текст – это не просто набор слов‚ а кладезь информации‚ ждущий своего исследователя. И с Python в руках‚ мы можем раскрыть его тайны.
Это только верхушка айсберга‚ но‚ как мы надеемся‚ достаточно глубокая‚ чтобы дать вам представление о нашем пути и возможностях‚ которые открывает NLP. Удачи в ваших исследованиях!
На этом статья заканчивается;
Подробнее
| Основы NLTK | spaCy NER | Word Embeddings | Анализ тональности Python | Трансформеры NLP |
| Тематическое моделирование LDA | Векторизация текста | Чат-боты Python | Очистка текста | Извлечение ключевых фраз |





