
- От Базовых Слов к Глубоким Смыслам: Наш Путь в Мир NLP с Python
- Первые Шаги: Разгадываем Азбуку Текста
- Токенизация и Стемминг: Разбираем Слова на Части
- Лемматизация: В поисках Истинной Формы Слова
- Регулярные Выражения: Хирургия Текста
- От Слов к Числам: Векторизация Текста
- Классические Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: От Счетов к Смыслам
- Doc2Vec и Sentence Transformers: Векторы для Документов и Предложений
- Задачи NLP: От Базовых до Продвинутых
- Распознавание Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis)
- Тематическое Моделирование: Открываем Скрытые Темы
- Классификация Текстов: Распределяем по Категориям
- Эра Трансформеров: Новый Уровень Понимания Языка
- BERT и Его Применение
- Генерация Текста с GPT
- Сложные Задачи с Трансформерами
- Инструменты и Методы для Специфических Задач
- Работа с Многоязычными Данными
- Извлечение Ключевых Фраз и Суммаризация
- Работа с Неструктурированными Данными
- Специализированные Инструменты
- Визуализация и Оценка: Делаем Результаты Понятными
- Визуализация: От Облаков Слов до Тепловых Карт
- Оценка Качества Моделей
- Будущее NLP и Наши Перспективы
От Базовых Слов к Глубоким Смыслам: Наш Путь в Мир NLP с Python
Привет, дорогие читатели! Сегодня мы хотим поделиться с вами нашим захватывающим путешествием в одну из самых интригующих областей искусственного интеллекта – Обработку Естественного Языка, или NLP (Natural Language Processing). Мы, как команда энтузиастов и практиков, провели бесчисленные часы, погружаясь в океан текстовых данных, и готовы рассказать, как Python стал нашим верным компаньоном в этом приключении. Эта статья, не просто перечень инструментов, это наш личный опыт, наши открытия и те моменты озарения, которые мы хотим передать вам. Мы уверены, что каждый, кто когда-либо задумывался о том, как заставить компьютер "понять" человеческую речь, найдет здесь что-то ценное.
В современном мире, где объемы текстовой информации растут экспоненциально, способность анализировать, интерпретировать и генерировать человеческий язык становится не просто полезным навыком, а критически важной компетенцией. От анализа отзывов клиентов до создания умных чат-ботов, от машинного перевода до выявления скрытых тем в огромных массивах данных – везде мы сталкиваемся с задачами NLP. Python с его богатой экосистемой библиотек стал де-факто стандартом для этих целей, предлагая нам мощные и гибкие инструменты для решения самых амбициозных задач. Давайте вместе разберемся, как мы осваивали этот увлекательный мир, шаг за шагом превращая хаос слов в осмысленные инсайты.
Первые Шаги: Разгадываем Азбуку Текста
Наше погружение в NLP началось с самых основ, с того, как компьютер вообще воспринимает текст. Для нас было очевидно, что для машины текст – это просто последовательность символов, и чтобы начать с ним работать, его нужно структурировать. Именно здесь на помощь приходят базовые операции, которые закладывают фундамент для всего дальнейшего анализа. Мы быстро поняли, что без качественной предобработки все наши усилия по созданию сложных моделей могут пойти прахом.
Токенизация и Стемминг: Разбираем Слова на Части
Первое, что мы освоили, это токенизация – процесс разделения текста на отдельные слова или фразы, которые мы называем токенами. Это как разобрать предложение на отдельные кирпичики. Мы использовали библиотеку NLTK (Natural Language Toolkit), которая стала для нас отправной точкой. NLTK предлагает различные токенизаторы, и мы экспериментировали с ними, чтобы понять, какой лучше подходит для наших задач. Например, для русского языка важен учет падежей и окончаний, и NLTK справляется с этим весьма достойно.
После токенизации мы столкнулись с проблемой: одно и то же слово может иметь разные формы (бежать, бежит, бежал). Для компьютера это разные слова, но для нас они обозначают одно и то же действие. Здесь на помощь пришел стемминг – процесс сокращения слов до их корневой формы (стема), удаляя суффиксы и окончания. Хотя стемминг и не всегда выдает осмысленные слова (например, "красивый" может стать "красив"), он значительно уменьшает размер словаря и упрощает анализ, что было критически важно на ранних этапах.
Лемматизация: В поисках Истинной Формы Слова
Но стемминг имел свои недостатки. Иногда он был слишком агрессивен, обрезая слова до неузнаваемости. Нам хотелось чего-то более точного, что возвращало бы слова к их словарной форме (лемме). И вот мы открыли для себя лемматизацию. В отличие от стемминга, лемматизация учитывает морфологию языка и контекст, пытаясь вернуть слово к его базовой форме, которая всегда является реальным словом из словаря. Для этой цели мы активно использовали spaCy – библиотеку, которая поразила нас своей скоростью и точностью, особенно для языков с богатой морфологией, таких как русский.
Сравнение стемминга и лемматизации стало для нас важным уроком. Мы поняли, что выбор метода зависит от конкретной задачи. Для быстрого анализа и уменьшения размерности стемминг подходит отлично, но для задач, требующих глубокого понимания смысла, лемматизация – наш лучший друг.
Регулярные Выражения: Хирургия Текста
Предобработка текста не ограничивается только токенизацией и лемматизацией. Нам постоянно приходилось очищать данные от шума: HTML-тегов, специальных символов, ссылок, лишних пробелов. Здесь наши незаменимыми помощниками стали регулярные выражения (модуль re в Python). Мы научились создавать сложные паттерны для точечного удаления или замены определенных элементов в тексте, что позволило нам получить действительно чистые данные для дальнейшего анализа. Это был своего рода хирургический инструмент, позволяющий нам точно "отрезать" ненужное и сохранить только самое важное.
| Этап Предобработки | Описание | Основные Инструменты | Цель |
|---|---|---|---|
| Токенизация | Разделение текста на слова/фразы. | NLTK, spaCy | Получение базовых единиц анализа. |
| Стемминг | Удаление окончаний для получения корня слова. | NLTK (PorterStemmer, SnowballStemmer) | Уменьшение размерности словаря, грубая нормализация. |
| Лемматизация | Приведение слов к словарной форме. | spaCy, NLTK (WordNetLemmatizer) | Точная нормализация, сохранение смысла. |
| Регулярные выражения | Поиск и замена паттернов в тексте. | Модуль re | Очистка от шума (URL, HTML, спецсимволы). |
| Удаление стоп-слов | Удаление часто встречающихся, но малозначимых слов. | NLTK, spaCy | Снижение шума, фокусировка на ключевых словах. |
От Слов к Числам: Векторизация Текста
После того как мы научились очищать и нормализовывать текст, перед нами встала следующая фундаментальная задача: как представить эти слова и предложения таким образом, чтобы компьютер мог с ними работать? Ведь машины понимают только числа. И здесь мы вошли в мир векторизации текста, где слова и документы превращаются в числовые векторы. Это был один из самых важных этапов, который открыл нам путь к применению алгоритмов машинного обучения.
Классические Векторизаторы: CountVectorizer и TF-IDF
Начали мы с простых, но эффективных методов. CountVectorizer из Scikit-learn просто подсчитывает частоту вхождения каждого слова в документе. Это дает нам вектор, где каждое измерение соответствует слову из нашего словаря, а значение – его счетчику. Простой, но эффективный подход для многих задач.
Однако мы быстро поняли, что не все слова одинаково важны. Часто встречающиеся слова, такие как "и", "в", "на", не несут много информации. Здесь нам помог TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает частоту слова в документе (TF), но и дает ему больший вес, если оно редко встречается в других документах корпуса (IDF). Таким образом, мы могли выделить слова, которые действительно уникальны и характерны для конкретного текста, отфильтровывая общий шум.
Word Embeddings: От Счетов к Смыслам
Следующим прорывом для нас стало знакомство с Word Embeddings, или векторными представлениями слов. В отличие от CountVectorizer и TF-IDF, которые рассматривают слова как независимые сущности, Word Embeddings пытаются уловить семантические отношения между словами. Идея проста, но гениальна: слова, которые часто встречаются в схожих контекстах, должны иметь схожие векторные представления. Мы окунулись в мир Gensim и его реализаций Word2Vec (Skip-gram и CBOW) и GloVe.
Мы были поражены, когда увидели, как эти модели могут улавливать аналогии, например, что "король" ⎻ "мужчина" + "женщина" = "королева". Это открыло для нас совершенно новый уровень понимания текста, позволяя моделям машинного обучения работать не просто с символами, а с семантикой. Мы также исследовали FastText, который оказался особенно полезным для работы с редкими словами и языками с богатой морфологией, так как он учитывает подслова.
Doc2Vec и Sentence Transformers: Векторы для Документов и Предложений
Когда нам понадобилось сравнивать целые документы или предложения, а не отдельные слова, мы обратились к Doc2Vec, также доступному в Gensim. Это расширение Word2Vec, которое генерирует векторные представления для целых текстов, сохраняя их смысловую близость. Это было чрезвычайно полезно для задач поиска похожих документов или кластеризации текстов.
Позднее мы обнаружили Sentence Transformers, которые стали нашим фаворитом для векторизации предложений и даже небольших абзацев. Эти модели, основанные на архитектурах трансформеров, позволяют получать высококачественные эмбеддинги, которые очень хорошо отражают смысл текста и превосходно подходят для задач семантического поиска, кластеризации и сравнения предложений.
"Язык, это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут." – Рита Мэй Браун
Задачи NLP: От Базовых до Продвинутых
Овладев основами предобработки и векторизации, мы были готовы приступить к решению реальных задач NLP. Этот этап был для нас самым захватывающим, поскольку мы начали видеть, как все эти инструменты превращаются в работающие системы, способные извлекать ценную информацию из текста.
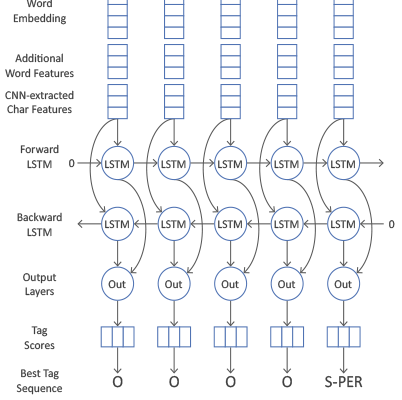
Распознавание Именованных Сущностей (NER)
Одной из первых практических задач, которую мы освоили, было Распознавание Именованных Сущностей (NER). Это процесс идентификации и классификации именованных сущностей в тексте, таких как имена людей, названия организаций, локации, даты и т.д. spaCy оказался здесь невероятно мощным инструментом благодаря своим предварительно обученным моделям. Мы использовали его для быстрого и точного NER, что было критично для извлечения структурированной информации из неструктурированных текстов. Позже мы экспериментировали с Flair, который предлагал state-of-the-art модели для NER, а также с CRF (Conditional Random Fields) для более тонкой настройки и работы с специфическими наборами данных.
Анализ Тональности (Sentiment Analysis)
Мы прекрасно понимали, что понимание настроения или тональности текста – это ключ к анализу отзывов клиентов, постов в социальных сетях и многого другого. Мы начали с простого, но эффективного инструмента – VADER (Valence Aware Dictionary and sEntiment Reasoner), который хорошо работает с текстами из социальных медиа. Затем мы перешли к более сложным подходам, используя TextBlob для быстрого анализа и, конечно же, модели машинного обучения (SVM, наивный байесовский классификатор) с Scikit-learn, обучая их на размеченных данных. Анализ тональности в социальных сетях, особенно с учетом сарказма, эмодзи и сленга, стал отдельной сложной, но очень интересной задачей, где мы применяли кастомные словари и более сложные модели на основе трансформеров.