
- Разгадывая Язык Цифрового Мира: Наш Путь в Мир Обработки Естественного Языка (NLP)
- Первые Шаги: Строим Фундамент Понимания Текста
- Токенизация и Стемминг: Азбука NLP с NLTK
- Продвинутая Лемматизация и Регулярные Выражения: Точность превыше всего
- Главные Инструменты: Наша NLP-Мастерская
- От NLTK к spaCy: Скорость и Элегантность
- Gensim и Scikit-learn: Раскрываем Скрытые Смыслы и Классифицируем Мир
- TextBlob: Простота и Быстрый Анализ
- Представление Текста: Как Компьютеры "Видят" Слова
- CountVectorizer и TF-IDF: Первые Шаги в Векторизации
- Word Embeddings: Отдельные Слова в Пространстве Смыслов
- FastText и Doc2Vec: От слов к документам
- Ключевые Задачи NLP: От Чувств до Скрытых Смыслов
- Анализ Тональности (Sentiment Analysis): Понимая Эмоции
- Тематическое Моделирование: Раскрываем Скрытые Темы
- Классификация Текстов: Автоматическая Организация Информации
- Продвинутые Техники и Современные Тенденции: Заглядывая в Будущее
- Трансформеры (Hugging Face): Новый Уровень Понимания
- Создание Нейросетей с PyTorch/TensorFlow: Полный Контроль
- Многоязычная Обработка: Стираем Языковые Барьеры
- Практические Приложения и Инструменты: От Данных к Инсайтам
- Извлечение Информации: Ключевые Фразы и Сущности
- Веб-Скрейпинг и Работа с PDF: Получаем Данные, Где Бы Они Ни Были
- Визуализация Текстовых Данных: Делаем Невидимое Видимым
- Вызовы и Решения: Наш Опыт Преодоления Трудностей
- Проблемы с Данными: Очистка и Нормализация
- Масштабирование: Большие Данные NLP
- Оценка Качества Моделей: Как Понять, Что Мы Делаем Правильно
Разгадывая Язык Цифрового Мира: Наш Путь в Мир Обработки Естественного Языка (NLP)
Привет, дорогие читатели и коллеги-энтузиасты! Сегодня мы хотим поделиться с вами чем-то по-настоящему захватывающим, тем, что изменило наш взгляд на взаимодействие с информацией и открыло бескрайние горизонты возможностей. Мы говорим об Обработке Естественного Языка, или NLP (Natural Language Processing) – области, где компьютеры учатся понимать, интерпретировать и даже генерировать человеческий язык. Звучит как научная фантастика, не правда ли? Но поверьте нам, это самая что ни на есть реальность, и мы готовы провести вас по всем её лабиринтам, опираясь на наш собственный, местами тернистый, но всегда увлекательный опыт.
За годы, что мы погружались в мир данных и искусственного интеллекта, мы обнаружили, что текст — это не просто набор символов. Это сокровищница знаний, эмоций, мнений и фактов, ждущая своего исследователя. От анализа отзывов клиентов до создания умных чат-ботов, от перевода сложных документов до выявления скрытых тенденций в социальных сетях — NLP повсюду. И мы, как заядлые блогеры, всегда стремились не просто понять, как это работает, но и объяснить это максимально доступно и интересно. Приготовьтесь, ведь наше путешествие начинается прямо сейчас!
Первые Шаги: Строим Фундамент Понимания Текста
Прежде чем мы сможем научить машину "читать", нам необходимо подготовить текст. Представьте, что вы хотите научить ребенка читать – сначала мы учим его буквы, затем слова, и только потом предложения. В NLP этот процесс начинается с таких фундаментальных операций, как токенизация и стемминг. Это наши самые первые инструменты, которые мы освоили, чтобы "разбить" большой текст на управляемые кусочки.
Мы помним, как впервые столкнулись с NLTK (Natural Language Toolkit) – это была наша отправная точка. Эта библиотека, словно швейцарский нож для работы с текстом, предоставила нам базовые инструменты. Токенизация, например, позволяет нам разделить текст на слова или предложения. Кажется простым, но попробуйте справиться с пунктуацией, сокращениями или составными словами! Стемминг, в свою очередь, помогает нам свести различные словоформы к их общей основе, к "стеблю". Например, слова "бежать", "бежит", "бегал" будут сведены к "беж". Это критически важно для анализа, так как позволяет нам считать эти слова как одно целое, а не как три разных сущности.
Токенизация и Стемминг: Азбука NLP с NLTK
Наш опыт показал, что без качественной токенизации все последующие этапы обработки текста будут неэффективны. NLTK предлагает различные токенизаторы, каждый из которых подходит для своих задач. Например, для русского языка это особенно актуально из-за богатой морфологии.
Стемминг, хотя и полезен, имеет свои ограничения. Мы быстро обнаружили, что он может приводить к образованию не существующих в языке основ. Например, "красивая" и "красивый" могут свестись к "красив", что вполне корректно, но "учитель" и "учить" могут стать "учит", что уже не совсем точно. Именно поэтому мы начали исследовать более продвинутые методы, такие как лемматизация.
- Токенизация: Разделение текста на минимальные смысловые единицы (токены), обычно слова или предложения.
- Стемминг: Приведение слова к его основе путём отсечения суффиксов и окончаний, часто без гарантии того, что результат будет корректным словом.
- Лемматизация: Более сложный процесс, который приводит слово к его словарной форме (лемме), учитывая морфологию и часть речи. Результат всегда является существующим словом.
Продвинутая Лемматизация и Регулярные Выражения: Точность превыше всего
Когда мы перешли к более сложным проектам, стало очевидно, что стемминг не всегда дает нужную точность. Тут на помощь пришла лемматизация. Используя такие библиотеки, как spaCy или Stanza, мы смогли получать более качественные основы слов. Например, "были", "есть", "будут" все приведутся к лемме "быть", что значительно улучшает качество анализа.
Параллельно с этим, мы активно использовали регулярные выражения (модуль `re` в Python) для предобработки текста. Это мощный инструмент для очистки данных: удаления HTML-тегов, пунктуации, чисел, лишних пробелов или специфических символов, которые могут мешать дальнейшему анализу. Мы часто сталкивались с "грязными" данными, полученными, например, путем веб-скрейпинга, и без регулярных выражений наша работа была бы в разы сложнее.
| Метод | Описание | Пример | Типичные Инструменты |
|---|---|---|---|
| Стемминг | Отсечение окончаний для получения основы слова. | "играл" -> "игра"; "компьютеры" -> "компьютер" | NLTK (PorterStemmer, SnowballStemmer) |
| Лемматизация | Приведение слова к словарной форме (лемме). | "играл" -> "играть"; "компьютеры" -> "компьютер" | spaCy, NLTK (WordNetLemmatizer), Stanza |
Главные Инструменты: Наша NLP-Мастерская
После того как мы освоили азы, пришло время познакомиться с тяжелой артиллерией – библиотеками, которые делают большую часть работы за нас. Мы всегда считали, что выбор правильного инструмента – половина успеха. И за годы работы мы перепробовали многие из них, формируя свой собственный набор "фаворитов".
От NLTK к spaCy: Скорость и Элегантность
Как мы уже упоминали, NLTK – это отличный старт. Но когда мы столкнулись с необходимостью обрабатывать большие объемы текста быстро и эффективно, мы открыли для себя spaCy. Эта библиотека поразила нас своей скоростью и элегантностью. spaCy не просто обрабатывает текст; она предоставляет нам готовую конвейерную обработку, включая токенизацию, POS-теггинг (определение частей речи), синтаксический парсинг и, что особенно ценно, NER (Распознавание Именованных Сущностей).
Распознавание именованных сущностей (NER) стало для нас настоящим открытием. Представьте, что у вас есть огромный объем текста – новости, статьи, отчеты. И вам нужно быстро найти все имена людей, названия компаний, географические объекты, даты. Вручную это заняло бы вечность! spaCy делает это за нас, и делает это очень хорошо. Мы использовали его для анализа текстов новостей, выявляя ключевых участников событий и места их действий. Это значительно упрощает процесс извлечения информации и позволяет нам фокусироваться на более глубоком анализе.
Gensim и Scikit-learn: Раскрываем Скрытые Смыслы и Классифицируем Мир
Когда мы захотели копнуть глубже и понять не только "что" говорится в тексте, но и "о чем" он, мы обратились к Gensim. Эта библиотека – наш незаменимый помощник в тематическом моделировании. Алгоритмы, такие как LDA (Латентное размещение Дирихле) и LSI (Латентное семантическое индексирование), позволяют нам выявлять скрытые темы в больших коллекциях документов. Мы использовали Gensim для анализа тысяч отзывов клиентов, чтобы понять, какие аспекты продукта или услуги чаще всего упоминаются и какие проблемы волнуют пользователей. Это дало нам ценные инсайты для улучшения качества.
А для задач классификации текстов, будь то спам-фильтрация, категоризация новостей или определение тональности, нашим выбором стал Scikit-learn. Это универсальный набор инструментов для машинного обучения, который предоставляет широкий спектр алгоритмов: от наивного байесовского классификатора до SVM. Мы разрабатывали системы для автоматической категоризации статей, где каждая новая публикация автоматически относилась к одной из предопределенных рубрик, экономя огромное количество времени и ресурсов.
- NLTK: Идеален для академических исследований и базовых задач, имеет широкое сообщество.
- spaCy: Высокопроизводительная библиотека для продакшн-систем, предлагает готовые модели и быстрый синтаксический анализ.
- TextBlob: Простой и интуитивно понятный API для быстрого прототипирования и анализа тональности.
- Gensim: Специализируеться на тематическом моделировании и работе с векторными представлениями слов.
- Scikit-learn: Общая библиотека ML, но с мощными инструментами для векторизации и классификации текста.
TextBlob: Простота и Быстрый Анализ
Иногда нам нужен был быстрый и простой способ получить общие сведения о тексте без погружения в сложности. Для таких случаев мы обнаружили TextBlob. Эта библиотека, построенная на NLTK, предоставляет интуитивно понятный API для выполнения общих задач NLP, таких как POS-теггинг, извлечение существительных, перевод и, конечно же, анализ тональности. Мы использовали ее для быстрого скрининга настроений в коротких сообщениях или комментариях, когда не требовалась высочайшая точность, а скорость была приоритетом.
TextBlob позволяет нам буквально за несколько строк кода определить, является ли отзыв положительным, отрицательным или нейтральным. Это прекрасный инструмент для быстрого прототипирования и для тех, кто только начинает свой путь в NLP и хочет увидеть результаты здесь и сейчас.
Представление Текста: Как Компьютеры "Видят" Слова
Текст для компьютера – это всего лишь последовательность символов. Чтобы он мог с ним работать, нам нужно преобразовать слова в числовой формат. Это называется векторизацией. Мы прошли долгий путь от простейших методов до самых современных, и каждый из них имеет свои преимущества.
CountVectorizer и TF-IDF: Первые Шаги в Векторизации
Наш первый опыт векторизации начался с CountVectorizer. Это простой, но эффективный метод, который подсчитывает частоту вхождения каждого слова в документе. Мы создаем словарь из всех уникальных слов в нашем корпусе, а затем каждый документ представляем в виде вектора, где каждая позиция соответствует слову из словаря, а значение – количеству его вхождений. Это хорошо работает для небольших задач, но быстро становится громоздким для больших текстов.
Затем мы открыли для себя TF-IDF (Term Frequency-Inverse Document Frequency). Этот метод не просто считает слова, но и взвешивает их. Он учитывает, насколько часто слово встречается в конкретном документе (TF) и насколько редко оно встречается во всем корпусе документов (IDF). Таким образом, слова, которые являются уникальными для данного документа и редко встречаются в других, получают больший вес, что позволяет нам лучше понять его смысл. Мы активно использовали TF-IDF для извлечения ключевых фраз и для задач классификации, когда было важно выделить наиболее значимые термины.
Word Embeddings: Отдельные Слова в Пространстве Смыслов
CountVectorizer и TF-IDF хороши, но у них есть существенный недостаток: они не учитывают семантическую связь между словами. "Кошка" и "кот" – это два разных слова для этих методов. Но мы знаем, что они близки по смыслу. Именно здесь на сцену вышли Word Embeddings.
Мы были поражены, когда впервые увидели, как работают Word2Vec и GloVe с использованием Gensim. Эти модели учатся представлять каждое слово в виде плотного вектора чисел таким образом, что слова с похожим значением имеют похожие векторные представления. Мы обнаружили, что математические операции с этими векторами могут давать удивительные результаты, например, "король" ⎼ "мужчина" + "женщина" ≈ "королева". Это открыло для нас совершенно новый уровень понимания текста, позволяя моделям улавливать тонкие смысловые нюансы.
С помощью Word Embeddings мы смогли значительно улучшить качество наших систем классификации текстов, поскольку модели теперь "понимали" контекст слов, а не просто их наличие. Это было особенно полезно при анализе отзывов, где синонимы играют важную роль.
FastText и Doc2Vec: От слов к документам
Мы не остановились на Word2Vec и GloVe. Наш путь привел нас к FastText, который, помимо прочего, умеет работать с редкими словами и даже с теми, которых нет в словаре, благодаря использованию подсловных единиц (n-грамм символов). Это стало критически важным для нас при работе с неформальными текстами, содержащими опечатки или сленг.
А для представления целых документов мы освоили Doc2Vec. Вместо того чтобы создавать вектор для каждого слова, Doc2Vec создает вектор для всего документа, учитывая порядок слов и их контекст. Это позволяет нам измерять сходство между документами и кластеризовать их по смыслу, что мы успешно применяли для анализа больших текстовых массивов и поиска похожих статей.
Ключевые Задачи NLP: От Чувств до Скрытых Смыслов
С фундаментом в виде предобработки и векторизации, мы смогли взяться за реальные задачи, которые решают бизнес-проблемы и помогают нам лучше понимать мир вокруг.
Анализ Тональности (Sentiment Analysis): Понимая Эмоции
Пожалуй, одной из самых востребованных задач, с которой мы регулярно сталкиваемся, является анализ тональности. Понимание настроения клиентов, общественного мнения или реакции на продукт – это бесценная информация. Мы начинали с простых подходов, таких как TextBlob, но быстро перешли к более сложным моделям.
Одной из наших первых специализированных моделей для анализа тональности был VADER (Valence Aware Dictionary and sEntiment Reasoner). VADER уникален тем, что он разработан специально для анализа тональности в социальных сетях и учитывает такие нюансы, как восклицательные знаки, капслок и даже эмодзи. Мы использовали его для анализа сообщений в социальных сетях (Twitter, Reddit), чтобы отслеживать реакцию на наши публикации или на новые продукты.
"Язык, это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
— Рита Мэй Браун
Мы также экспериментировали с обучением собственных моделей на Scikit-learn, используя TF-IDF или Word Embeddings, чтобы адаптироваться к специфике конкретных предметных областей, например, анализу тональности финансовых новостей. Здесь обычные слова могут иметь совершенно иной эмоциональный окрас, и общие модели не всегда справляются.
Тематическое Моделирование: Раскрываем Скрытые Темы
Как мы уже упоминали, Gensim стал нашим проводником в мир тематического моделирования. Мы использовали LDA и LSI для анализа больших корпусов текстов, например, научных статей или блогов. Это позволило нам выявить основные темы, которые обсуждаются в этих текстах, и понять, как они соотносятся друг с другом. Это особенно полезно, когда у вас тысячи документов, и вы хотите быстро получить высокоуровневое представление об их содержании.
Мы также сравнивали различные модели тематического моделирования, такие как LDA и NMF (Non-negative Matrix Factorization). Каждый метод имеет свои сильные и слабые стороны, и выбор часто зависит от характера данных и конкретной задачи. Например, NMF часто дает более интерпретируемые темы для коротких текстов.
| Метод | Принцип работы | Преимущества | Недостатки |
|---|---|---|---|
| LDA | Вероятностная модель, предполагающая, что документы являются смесью тем, а темы — смесью слов. | Хорошо работает с большими корпусами, позволяет оценить долю каждой темы в документе. | Требует настройки количества тем, может быть чувствителен к шуму. |
| NMF | Матричная факторизация, раскладывающая матрицу "документ-слово" на две матрицы: "документ-тема" и "тема-слово". | Часто дает более легко интерпретируемые темы, подходит для коротких текстов. | Может быть менее гибким, чем LDA, в некоторых случаях. |
Классификация Текстов: Автоматическая Организация Информации
Классификация – это, пожалуй, одна из самых распространенных задач в NLP. Мы использовали ее для множества целей: от определения спама в комментариях до автоматической категоризации юридических документов. Scikit-learn с его реализациями SVM, наивного байесовского классификатора и других моделей был нашим основным инструментом.
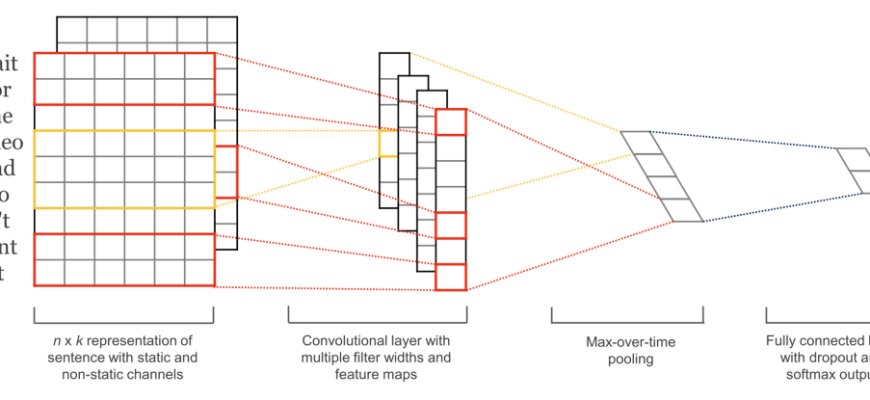
Для более сложных задач мы начали применять PyTorch/TensorFlow для создания нейросетей NLP, таких как LSTM-сети (Long Short-Term Memory). Эти сети способны улавливать долгосрочные зависимости в тексте, что критически важно для понимания контекста в больших предложениях или абзацах. Мы использовали их для анализа текстов отзывов клиентов, где требовалось более глубокое понимание нюансов, чем могли дать классические методы.
Продвинутые Техники и Современные Тенденции: Заглядывая в Будущее
Мир NLP развивается невероятно быстро. То, что еще вчера казалось вершиной технологий, сегодня уже является стандартом. Мы всегда стремимся быть в курсе последних достижений и внедрять их в свою практику.
Трансформеры (Hugging Face): Новый Уровень Понимания
Появление архитектуры Трансформеров стало настоящей революцией в NLP. Мы помним, как впервые начали работать с библиотекой Hugging Face Transformers. Это было похоже на открытие совершенно нового континента. Модели, такие как BERT, GPT, T5, способны выполнять широкий спектр задач с невиданной ранее точностью.
Мы использовали BERT для задач классификации, NER и даже для тонкой настройки (fine-tuning) предварительно обученных моделей под наши специфические задачи. Например, для распознавания сущностей в медицинских записях, где нужно было выявлять названия лекарств, диагнозы и процедуры. А модели GPT открыли для нас двери в мир генерации текста – от создания черновиков статей до автоматического ответа на запросы в чат-ботах.
Hugging Face предоставила нам не просто модели, а целую экосистему для работы с ними: готовые веса, инструменты для обучения, тонкой настройки и развертывания. Это значительно упростило наш процесс разработки и позволило сосредоточиться на креативных аспектах.
Создание Нейросетей с PyTorch/TensorFlow: Полный Контроль
Хотя готовые трансформеры очень мощны, иногда нам требовался полный контроль над архитектурой модели. Для этого мы углубились в PyTorch и TensorFlow. Мы разрабатывали собственные нейросети для NLP, например, для создания систем вопросно-ответных систем (QA). Это позволяло нам максимально точно адаптировать модель под конкретные требования и данные, что особенно важно для задач, где требуется очень высокая точность, например, в юридических документах.
Многоязычная Обработка: Стираем Языковые Барьеры
В нашем блогерском мире мы часто сталкиваемся с многоязычным контентом. Поэтому мы освоили инструменты для обработки многоязычных текстовых корпусов. Библиотеки, такие как Polyglot и Stanza, стали нашими незаменимыми помощниками. Stanza, разработанная Стэнфордским университетом, особенно хороша для языков с богатой морфологией, таких как русский, предоставляя высококачественный синтаксический парсинг, лемматизацию и POS-теггинг.
Мы также начали экспериментировать с разработкой систем машинного перевода на Python, используя трансформерные модели. Это сложная, но невероятно увлекательная область, которая открывает возможности для глобального охвата нашей аудитории.
Практические Приложения и Инструменты: От Данных к Инсайтам
Теория – это хорошо, но без практического применения она теряет смысл. Мы всегда стремились создавать реальные инструменты и системы, которые решают конкретные задачи.
Извлечение Информации: Ключевые Фразы и Сущности
Помимо NER, мы активно занимались извлечением ключевых фраз. Для этого мы использовали такие алгоритмы, как RAKE (Rapid Automatic Keyword Extraction) и TextRank (для извлечения ключевых предложений и суммаризации). Эти методы позволяют нам быстро понять основную суть документа, выделить наиболее важные идеи и термины. Мы применяли их для автоматического тегирования контента и для создания кратких аннотаций к статьям.
Мы также разрабатывали модели для выявления связей между сущностями. Например, если в тексте упоминаются "Иван Иванов" и "компания АБВ", мы можем определить, является ли Иван сотрудником АБВ, основателем или клиентом. Это очень сложная, но крайне важная задача для построения графов знаний.
Веб-Скрейпинг и Работа с PDF: Получаем Данные, Где Бы Они Ни Были
Часто нужная нам информация находится не в аккуратных CSV-файлах, а разбросана по веб-страницам или заперта в PDF-документах. Для этих целей мы освоили Beautiful Soup для веб-скрейпинга текста. Эта библиотека позволяет нам парсить HTML-страницы и извлекать нужный контент, игнорируя лишние элементы;
А для работы с PDF мы используем PyMuPDF. Он позволяет нам извлекать текст из PDF-файлов, а также метаданные. Это оказалось незаменимым при анализе юридических документов, отчетов и научных публикаций, которые чаще всего распространяются именно в этом формате.
Визуализация Текстовых Данных: Делаем Невидимое Видимым
Голые данные – это одно, но красиво представленные данные – это совсем другое. Мы убеждены, что визуализация является ключом к пониманию и донесению инсайтов. Мы активно используем Word Clouds для быстрого отображения частотности слов и Heatmaps для визуализации матриц сходства или корреляции между темами.
Мы также экспериментировали с более сложными визуализациями, такими как графы взаимосвязей между сущностями или временные ряды в текстовых данных, чтобы отслеживать эволюцию тем или настроений с течением времени.
Вызовы и Решения: Наш Опыт Преодоления Трудностей
Путь в NLP не всегда был гладким. Мы сталкивались с множеством проблем, но каждая из них делала нас только сильнее и опытнее.
Проблемы с Данными: Очистка и Нормализация
Одна из самых частых проблем – это "грязные" данные. Неполные тексты, опечатки, грамматические ошибки, сленг, эмодзи, сокращения – все это может серьезно затруднить анализ. Мы разработали целый арсенал инструментов для очистки данных: от удаления стоп-слов и пунктуации до нормализации сленга и исправления орфографии (с использованием, например, библиотеки Jellyfish для сравнения строк).
Особенно интересной была работа с эмодзи и сленгом в современных текстах, например, при анализе сообщений в социальных сетях. Здесь стандартные словари тональности часто бессильны, и нам приходилось обучать свои модели или создавать специализированные словари.
Масштабирование: Большие Данные NLP
Когда речь заходит о миллионах и миллиардах документов, обычные подходы перестают работать. Мы учились обрабатывать большие текстовые массивы (Big Data NLP), используя распределенные вычисления и оптимизированные библиотеки. Это требовало переосмысления архитектуры наших решений и использования более эффективных алгоритмов.
Работа с текстом в режиме реального времени (Streaming NLP) – еще один вызов, который мы активно исследовали. Анализ поступающих данных "на лету", например, потока твитов, требует очень быстрых и легковесных моделей.
Оценка Качества Моделей: Как Понять, Что Мы Делаем Правильно
Создать модель – это полдела. Гораздо важнее убедиться, что она работает хорошо. Мы всегда уделяли особое внимание оценке качества наших NLP-моделей. Для задач классификации и NER мы используем стандартные метрики, такие как F1-score, Precision и Recall. Эти метрики позволяют нам объективно оценить производительность модели и сравнить различные подходы.
Мы также разрабатывали инструменты для автоматической разметки данных, что значительно ускоряет процесс подготовки обучающих выборок для наших моделей. Это критически важно, поскольку качество модели напрямую зависит от качества данных, на которых она обучалась.
Наш путь в мире Обработки Естественного Языка – это постоянное обучение и эксперименты. Мы прошли от основ токенизации до сложнейших трансформерных архитектур, от простого анализа частотности слов до выявления скрытых тем и эмоций. Мы видели, как NLP превращается из академической дисциплины в мощный инструмент, меняющий бизнес и повседневную жизнь.
Мы верим, что потенциал NLP еще далек от исчерпания. С каждым днем появляются новые модели, алгоритмы и применения. И мы, как блогеры и энтузиасты, продолжим делиться нашим опытом, открытиями и, конечно же, нашими ошибками, чтобы вместе с вами исследовать этот удивительный и постоянно меняющийся мир. Присоединяйтесь к нам, ведь самые интересные открытия еще впереди!
На этом статья заканчивается.
Подробнее
| Основы NLTK | Использование spaCy | Библиотека Gensim | Word Embeddings | Анализ тональности VADER |
| Трансформеры Hugging Face | Классификация текстов Scikit-learn | Регулярные выражения NLP | Лемматизация и стемминг | Разработка чат-ботов Python |




