
- Расшифровываем Текст: Наш Глубокий Дайв в Мир NLP с Python
- Фундамент Понимания: Первые Шаги в Предобработке Текста
- Токенизация, Стемминг и Лемматизация: Разбираем Слова по Косточкам
- Регулярные Выражения (re): Ваш Швейцарский Нож для Текста
- Очистка Данных: Убираем Шум и Мусор
- Извлечение Смысла: От Слов к Идеям и Концепциям
- Распознавание Именованных Сущностей (NER): Имена, Места, Даты
- Векторизация Текста: Переводим Слова в Числа
- Тематическое Моделирование: Выявляем Скрытые Темы
- Извлечение Ключевых Фраз: Самое Главное в Тексте
- Анализ Тональности и Эмоций: За Гранью Слов
- Инструменты для Анализа Тональности
- Продвинутые Методы и Модели: Современный NLP в Действии
- Трансформеры (Hugging Face): Новая Эра в NLP
- Нейросети для NLP: PyTorch и TensorFlow
- Специализированные Задачи и Инструменты: От Веб-Скрейпинга до Чат-Ботов
- Работа с Многоязычными Данными
- Сбор и Извлечение Текста
- Разработка Интеллектуальных Систем на Базе NLP
- Анализ и Визуализация Текстовых Данных
Расшифровываем Текст: Наш Глубокий Дайв в Мир NLP с Python
Привет, дорогие читатели и любители технологий! Сегодня мы погрузимся в одну из самых увлекательных и быстро развивающихся областей искусственного интеллекта – обработку естественного языка, или NLP (Natural Language Processing). Представьте себе: миллиарды слов, написанных и произнесенных каждый день по всему миру. Как превратить этот хаотичный поток информации в нечто осмысленное, чтобы компьютеры могли его понимать, анализировать и даже генерировать? Именно этим и занимается NLP, и мы с вами узнаем, как Python стал де-факто стандартом для решения этих задач.
Наш путь в мире NLP начался не так давно, но за это время мы успели поработать с огромным количеством текстов: от отзывов клиентов и новостных статей до юридических документов и медицинских записей. Мы видели, как правильно подобранные инструменты и методики могут творить чудеса, извлекая скрытые смыслы, автоматизируя рутинные процессы и открывая новые горизонты для бизнеса и исследований. В этой статье мы поделимся нашим личным опытом, расскажем о самых мощных библиотеках и подходах, которые мы используем каждый день, и покажем, как вы можете начать свой собственный путь в этом захватывающем мире. Приготовьтесь, будет интересно!
Фундамент Понимания: Первые Шаги в Предобработке Текста
Любой текст, прежде чем стать пищей для алгоритмов машинного обучения, должен пройти серьезную подготовку. Представьте себе сырой алмаз – он красив сам по себе, но чтобы он засиял во всей красе, требуется искусная огранка. То же самое и с текстом. В естественном языке слишком много шума, избыточности и неоднозначности, которые могут сбить с толку даже самые продвинутые модели. Поэтому предобработка текста – это не просто важный, а абсолютно критический этап, который часто определяет успех всего проекта. Мы всегда начинаем именно с этого.
Наш опыт показывает, что без качественной предобработки даже самые мощные модели могут давать неудовлетворительные результаты. Это как пытаться читать книгу, где все слова написаны слитно, с орфографическими ошибками и без знаков препинания. Мы должны привести текст в стандартизированный и чистый вид, который позволит нашим алгоритмам сосредоточиться на истинном смысле, а не на синтаксическом мусоре или вариациях слов.
Токенизация, Стемминг и Лемматизация: Разбираем Слова по Косточкам
Самый первый шаг в предобработке – это токенизация. Это процесс разбиения текста на отдельные единицы, или "токены". Чаще всего токенами являются слова и знаки препинания. Мы используем такие библиотеки, как NLTK (Natural Language Toolkit) и spaCy, которые предлагают эффективные токенизаторы для различных языков. NLTK, например, предоставляет несколько видов токенизаторов, включая токенизаторы для предложений и слов, что позволяет нам гибко подходить к задаче.
После того как мы разбили текст на токены, часто возникает необходимость привести слова к их базовой форме. Здесь в игру вступают стемминг и лемматизация.
Стемминг – это более грубый процесс, который отсекает окончания слов, чтобы получить их "корень" (стем). Например, слова "бегает", "бегал", "бегущий" могут быть приведены к одному и тому же стему "бег". Мы часто используем стеммеры из NLTK, такие как PorterStemmer или SnowballStemmer, особенно для английского языка. Его преимущество в скорости, но иногда он может создавать несуществующие слова.
Лемматизация – это более сложный и точный процесс. Он не просто отсекает окончания, а приводит слово к его словарной (канонической) форме, учитывая морфологию и часть речи. Так, "бегает", "бегал", "бегущий" будут приведены к "бежать". Для лемматизации мы предпочитаем spaCy, так как он предоставляет более качественные результаты благодаря использованию статистических моделей и контекста. Для языков с богатой морфологией, таких как русский, Stanza также показал себя отлично, обеспечивая продвинутую лемматизацию.
Разница между стеммингом и лемматизацией часто критична. Если нам нужна высокая точность и сохранение грамматического смысла, мы всегда выбираем лемматизацию. Если скорость и приблизительная форма слова достаточны, стемминг может быть вполне приемлемым решением, особенно для больших объемов данных.
Регулярные Выражения (re): Ваш Швейцарский Нож для Текста
Когда дело доходит до тонкой настройки и очистки текста, мы не можем обойтись без регулярных выражений. В Python для этого есть встроенная библиотека re. Она позволяет нам находить и манипулировать строками по сложным шаблонам. Это невероятно мощный инструмент для решения таких задач, как удаление HTML-тегов, извлечение email-адресов, номеров телефонов, дат и других структурированных данных из неструктурированного текста.
Например, мы часто используем регулярные выражения для:
- Удаления HTML-тегов из веб-страниц, полученных через веб-скрейпинг.
- Извлечения конкретных паттернов, таких как коды товаров или даты, которые не являются частью стандартных сущностей.
- Нормализации пунктуации, чтобы все знаки препинания были отделены пробелами или заменены на стандартные аналоги.
- Очистки текста от специальных символов или лишних пробелов.
Регулярные выражения требуют некоторого времени для освоения, но как только вы ими овладеете, они станут незаменимым инструментом в вашем арсенале NLP. Мы всегда держим справочник по re под рукой, потому что каждый проект приносит свои уникальные задачи по очистке.
Очистка Данных: Убираем Шум и Мусор
Помимо токенизации и лемматизации, существует множество других этапов очистки текста, которые мы применяем. Эти шаги направлены на удаление "шума", который может негативно сказаться на производительности наших моделей.
Вот некоторые из наиболее распространенных задач по очистке, с которыми мы сталкиваемся:
- Удаление стоп-слов: Это часто встречающиеся слова, такие как "и", "в", "на", "он", которые не несут значительного смыслового значения для анализа. NLTK и spaCy предоставляют списки стоп-слов для многих языков, которые мы можем использовать или расширять.
- Удаление пунктуации и специальных символов: Зачастую знаки препинания не нужны для семантического анализа, и их удаление или замена на пробелы упрощает дальнейшую обработку.
- Приведение к нижнему регистру: Это помогает унифицировать слова, чтобы "Слово" и "слово" воспринимались как одно и то же.
- Обработка эмодзи и сленга: В текстах из социальных сетей эмодзи и сленг играют важную роль. Мы либо удаляем их, либо пытаемся нормализовать, переводя сленг в стандартные формы или присваивая эмодзи текстовые описания. Для этого иногда приходится создавать собственные словари или использовать специализированные библиотеки.
- Удаление URL-адресов и чисел: В зависимости от задачи, ссылки и числовые значения могут быть бесполезными или даже вредными, и мы их удаляем или заменяем на специальные токены.
- Обработка неполных и ошибочных данных: Опечатки, грамматические ошибки – все это реальность пользовательского контента. Мы используем инструменты для проверки грамматики и орфографии, а также библиотеки типа Jellyfish для сравнения строк и поиска похожих слов, чтобы минимизировать влияние таких ошибок.
Каждый проект уникален, и мы всегда индивидуально подходим к выбору методов очистки, чтобы добиться наилучших результатов. Главное – не переусердствовать, чтобы не потерять важную информацию.
Извлечение Смысла: От Слов к Идеям и Концепциям
После того как текст очищен и приведен в порядок, мы переходим к самой интересной части – извлечению из него смысла. Наша цель – не просто обработать слова, но понять, что они означают, какие сущности упоминаются, о чем идет речь, и каково общее настроение текста. Это этап, где компьютеры начинают "читать" между строк.
Мы используем целый арсенал техник и библиотек для того, чтобы превратить голый текст в структурированные данные, которые затем можно анализировать, визуализировать или использовать для построения более сложных интеллектуальных систем. Это своего рода детективная работа, где каждый токен – это улика, ведущая к более глубокому пониманию.
Распознавание Именованных Сущностей (NER): Имена, Места, Даты
Одной из наиболее фундаментальных задач в NLP является Распознавание Именованных Сущностей (NER). Это процесс идентификации и классификации именованных сущностей в тексте по заранее определенным категориям, таким как имена людей, названия организаций, географические местоположения, даты, денежные значения и т.д. Представьте, насколько это важно для анализа новостей или юридических документов!
Для быстрого и эффективного NER мы чаще всего обращаемся к spaCy. Он поставляется с предварительно обученными моделями для различных языков, которые обеспечивают впечатляющую точность и скорость. Мы можем легко извлечь все сущности из текста и их типы, что очень удобно для быстрого прототипирования и анализа.
Однако, когда требуется более высокая точность или работа со специфическими предметными областями (например, медицинские термины или юридические определения), мы используем более продвинутые подходы. Это включает в себя тонкую настройку (fine-tuning) предварительно обученных моделей, таких как BERT, или использование библиотек, таких как Flair, которая известна своими State-of-the-Art результатами в NER благодаря использованию контекстных строковых эмбеддингов. Также мы экспериментировали с CRF (Conditional Random Fields) для распознавания сущностей, особенно когда данные для обучения были не очень большими, но требовалась высокая интерпретируемость модели.
Оценка качества NER-моделей является ключевым моментом. Мы используем стандартные метрики, такие как F1-score, Precision и Recall, чтобы убедиться, что наши модели работают так, как нам нужно, особенно в критически важных приложениях, таких как анализ юридических документов или медицинских записей.
Векторизация Текста: Переводим Слова в Числа
Компьютеры не понимают слова в их лингвистическом смысле. Они работают с числами. Поэтому одним из краеугольных камней NLP является векторизация текста – процесс преобразования текста (слов, предложений, документов) в числовые векторы. От того, насколько хорошо мы это сделаем, зависит способность наших моделей "понимать" текст.
Мы прошли долгий путь от простых методов к сложным:
- Методы на основе частотности:
- CountVectorizer: Создает матрицу, где каждая строка – это документ, каждый столбец – уникальное слово, а значения – количество вхождений слова в документ. Просто и понятно.
- TfidfVectorizer: Улучшенная версия CountVectorizer, которая учитывает не только частоту слова в документе (TF — Term Frequency), но и его редкость во всем корпусе (IDF ― Inverse Document Frequency). Это помогает выделить более значимые слова. Мы активно используем их из библиотеки Scikit-learn.
- Word Embeddings (Векторные представления слов):
Эти методы учатся представлять слова в виде плотных векторов, где слова с похожим значением имеют похожие векторные представления. Мы буквально видим, как слова с семантической близостью оказываются рядом в многомерном пространстве.
- Word2Vec (Skip-gram и CBOW) и GloVe: Мы используем библиотеку Gensim для работы с Word2Vec и GloVe. Эти модели учатся контексту слов, предсказывая либо слово по его контексту (CBOW), либо контекст по слову (Skip-gram). Это был настоящий прорыв, позволивший нам работать с семантикой слов.
- FastText: Разработанный Facebook, FastText похож на Word2Vec, но учитывает суб-словарные единицы (n-граммы символов). Это делает его особенно эффективным для работы с редкими словами и морфологически богатыми языками, а также для классификации текста.
- Векторизация предложений и документов:
- Doc2Vec: Расширение Word2Vec, которое позволяет создавать векторные представления не только для слов, но и для целых документов. Это невероятно полезно для поиска похожих документов или кластеризации текстов.
- Sentence Transformers: Современные модели, основанные на архитектуре трансформеров, которые позволяют получать высококачественные векторные представления для предложений и документов. Они значительно превосходят традиционные методы в задачах, требующих понимания семантики целых фраз.
- Контекстное встраивание (Contextual Embeddings): Это представление слов, которое изменяется в зависимости от контекста, в котором слово используется. Эмбеддинги от моделей типа BERT и ELMo являются отличными примерами. Мы видим, как одно и то же слово может иметь разные векторы в разных предложениях, что отражает его полисемию.
Выбор метода векторизации зависит от задачи. Для задач классификации на небольших данных TF-IDF может быть достаточно, но для глубокого понимания семантики и современных задач мы всегда обращаемся к векторным представлениям слов и трансформерам.
Тематическое Моделирование: Выявляем Скрытые Темы
Часто нам нужно понять, о чем говорят большие массивы текста, не читая каждый документ по отдельности. Здесь на помощь приходит тематическое моделирование – набор алгоритмов, которые позволяют автоматически выявлять "скрытые темы" в коллекции документов.
Мы активно используем библиотеку Gensim для этой цели. Она предоставляет мощные реализации алгоритмов, таких как:
- LDA (Latent Dirichlet Allocation): Один из самых популярных алгоритмов. Он предполагает, что каждый документ представляет собой смесь нескольких тем, а каждая тема – это распределение слов. LDA помогает нам понять, какие темы присутствуют в нашем корпусе и какие слова с ними связаны. Мы часто применяем LDA для анализа отзывов клиентов, чтобы выявить основные болевые точки или преимущества продуктов.
- LSI (Latent Semantic Indexing): Более старый, но все еще полезный метод, основанный на сингулярном разложении матрицы терм-документ. LSI хорошо работает для поиска похожих документов и понимания общих концепций.
Помимо LDA и LSI, мы также сравниваем их с NMF (Non-negative Matrix Factorization), который часто дает сопоставимые, а иногда и более интерпретируемые результаты, особенно когда темы должны быть представлены неотрицательными весами. Сравнение этих моделей (LDA vs NMF) – это всегда интересный эксперимент, который помогает нам выбрать наилучший подход для конкретного набора данных.
Тематическое моделирование – это мощный инструмент для анализа блогов, форумов, новостных статей и других больших текстовых массивов, позволяющий быстро получить представление о содержании и выявить тренды.
Извлечение Ключевых Фраз: Самое Главное в Тексте
Чтобы быстро понять суть документа, нам часто нужны его ключевые слова или фразы. Мы используем различные подходы для извлечения ключевых фраз, которые помогают нам суммировать содержание или создавать теги для контента.
- RAKE (Rapid Automatic Keyword Extraction): Это алгоритм, который достаточно прост в реализации и эффективно извлекает ключевые фразы, анализируя частоту слов и их встречаемость в пределах слов-кандидатов, ограниченных стоп-словами. Он отлично подходит для быстрого получения списка важных терминов.
- TextRank: Основанный на алгоритме PageRank, TextRank позволяет не только извлекать ключевые слова, но и ключевые предложения. Он строит граф слов или предложений, где ребра представляют их взаимосвязи, а затем ранжирует их по важности. Мы используем TextRank для суммаризации текста, когда нам нужно получить наиболее репрезентативные предложения, и для выделения тем в больших документах.
Эти методы позволяют нам автоматизировать процесс тегирования контента, создания кратких аннотаций и анализа текстовых данных для извлечения наиболее значимой информации.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
— Рита Мэй Браун
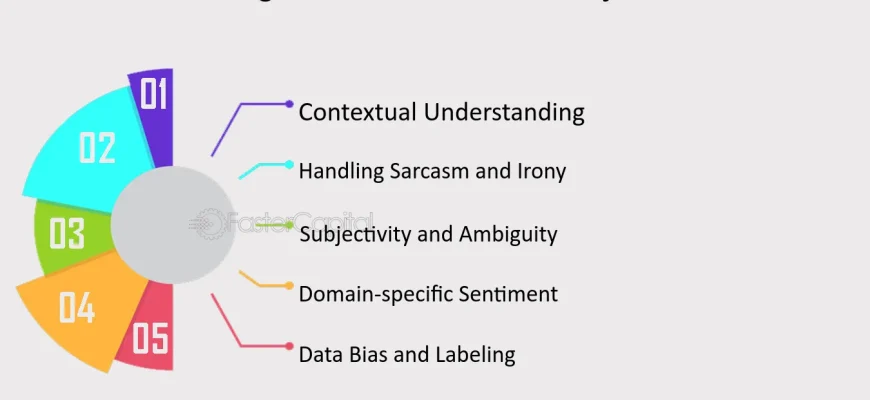
Анализ Тональности и Эмоций: За Гранью Слов
Понимание того, как люди относятся к продукту, услуге или событию, является бесценным для бизнеса и социологии. Анализ тональности (Sentiment Analysis) – это задача определения эмоциональной окраски текста: позитивной, негативной или нейтральной. Для нас это один из самых востребованных видов анализа.
Мы активно применяем его для анализа отзывов клиентов, постов в социальных сетях, финансовых новостей и многого другого. Это позволяет нам не только понять общее настроение, но и выявить конкретные аспекты, вызывающие негатив или позитив.
Инструменты для Анализа Тональности
Для анализа тональности мы используем различные библиотеки и подходы:
- VADER (Valence Aware Dictionary and sEntiment Reasoner): Это лексико-ориентированный инструмент, специально обученный для анализа тональности текстов из социальных сетей. Он отлично справляется с эмодзи, сленгом и акронимами, что делает его нашим выбором по умолчанию для анализа сообщений в социальных сетях, таких как Twitter или Reddit.
- TextBlob: Предоставляет простой API для анализа тональности и других NLP-задач. Он удобен для быстрого прототипирования, но имеет свои ограничения, особенно для русского языка или специфических доменов. Мы используем его для быстрого анализа и определения языка текста.
- Машинное обучение и глубокое обучение: Для более сложных и точных задач мы обучаем собственные модели классификации тональности, используя Scikit-learn (SVM, Наивный Байес) или глубокие нейронные сети с PyTorch/TensorFlow. Здесь особую роль играют трансформерные модели, такие как BERT, которые могут быть тонко настроены (fine-tuned) для задачи анализа тональности, обеспечивая State-of-the-Art результаты.
Одной из самых сложных задач является анализ тональности с учетом сарказма и иронии. Это требует глубокого контекстного понимания и часто решается с помощью более продвинутых моделей и большого количества размеченных данных. Мы также проводим анализ тональности финансовых новостей, где даже малейшие оттенки могут влиять на рынки, требуя особенно тщательного подхода.
Помимо общей тональности, мы также работаем над распознаванием эмоций. Современные трансформерные архитектуры позволяют нам не просто определить позитив или негатив, но и классифицировать более тонкие эмоции, такие как радость, гнев, печаль, страх, удивление и отвращение, что открывает новые возможности для более глубокого понимания пользовательского опыта.
Продвинутые Методы и Модели: Современный NLP в Действии
Мир NLP не стоит на месте, и последние несколько лет принесли революционные изменения благодаря развитию глубокого обучения и, в частности, архитектуры трансформеров. Мы с головой погрузились в эти новые технологии, и они кардинально изменили наш подход к решению многих задач.
Эти методы позволяют нам достигать невероятной точности и гибкости, которые раньше казались недостижимыми. Они открывают двери для создания систем, которые не просто обрабатывают текст, а по-настоящему "понимают" его, генерируют и взаимодействуют с ним на качественно новом уровне.
Трансформеры (Hugging Face): Новая Эра в NLP
Появление архитектуры трансформеров и таких моделей, как BERT, GPT, T5, стало настоящим прорывом. Они позволили нам решить множество сложных задач NLP с беспрецедентной эффективностью. Библиотека Hugging Face Transformers – это наш основной инструмент для работы с этими моделями. Она предоставляет удобный и унифицированный интерфейс для сотен предварительно обученных моделей, а также инструменты для их тонкой настройки.
Что мы делаем с трансформерами:
- Классификация текста: Используем BERT и его варианты для задач классификации, таких как анализ тональности, категоризация статей или определение спама. Тонкая настройка (Fine-tuning) предварительно обученных моделей на наших данных дает потрясающие результаты.
- Генерация текста: С помощью моделей GPT мы можем генерировать связный и осмысленный текст. Это может быть автоматическое написание статей, создание диалогов для чат-ботов, генерация описаний товаров или даже помощь в написании кода.
- Машинный перевод: Трансформеры являются основой современных систем машинного перевода. Мы используем их для разработки систем автоматического перевода узкоспециализированных текстов, где стандартные переводчики могут давать неточные результаты.
- Вопросно-ответные системы (QA): Создаем системы, которые могут отвечать на вопросы, основываясь на заданном тексте или корпусе документов. Это очень полезно для автоматизации поддержки клиентов или создания FAQ на основе обширной документации.
- Суммаризация текста: Трансформерные модели отлично справляются с задачей суммаризации, как экстрактивной (извлечение ключевых предложений), так и абстрактивной (генерация нового краткого текста).
Работа с трансформерами часто требует значительных вычислительных ресурсов, поэтому мы активно используем GPU-ускорение для обучения и инференса моделей. Hugging Face отлично интегрируется с PyTorch и TensorFlow, что упрощает этот процесс.
Нейросети для NLP: PyTorch и TensorFlow
Когда стандартных решений недостаточно, или нам нужна максимальная гибкость для экспериментальных моделей, мы переходим к разработке нейросетей для NLP с использованием фреймворков PyTorch и TensorFlow/Keras.
Мы создаем различные архитектуры:
- LSTM-сети (Long Short-Term Memory): До появления трансформеров LSTM были основным инструментом для работы с последовательными данными, такими как текст. Мы до сих пор используем их для некоторых задач, где требуется моделирование длительных зависимостей, например, для анализа временных рядов в текстовых данных или для создания простых языковых моделей.
- Сверточные нейронные сети (CNN): Хотя CNN чаще ассоциируются с обработкой изображений, они также могут быть эффективны для извлечения локальных признаков из текста, например, для классификации.
- Графовые эмбеддинги (Graph Embeddings): Для анализа взаимосвязей между сущностями в тексте мы иногда применяем графовые нейронные сети и графовые эмбеддинги. Это позволяет нам находить сложные связи, например, между персонажами в литературных произведениях или компаниями в новостных статьях.
Разработка собственных нейросетей дает нам полный контроль над архитектурой и процессом обучения, что критически важно для решения уникальных и нетривиальных задач.
Специализированные Задачи и Инструменты: От Веб-Скрейпинга до Чат-Ботов
Помимо основных задач, мы постоянно сталкиваемся с широким спектром специализированных приложений NLP. Это позволяет нам расширять наши горизонты и применять наши знания в самых разных областях – от анализа больших данных до создания интерактивных систем.
Каждый из этих проектов требует особого подхода и набора инструментов, и мы всегда готовы экспериментировать и осваивать новые технологии.
Работа с Многоязычными Данными
Мир не ограничивается английским языком. Мы часто работаем с многоязычными текстовыми корпусами, и это ставит перед нами дополнительные вызовы.
- Polyglot: Эта библиотека отлично подходит для мультиязычности, предлагая широкий спектр функций, включая определение языка, токенизацию, NER, анализ тональности и перевод для множества языков, в т.ч. редких.
- Stanza: Разработанная Stanford NLP Group, Stanza – это мощный инструмент для языков с богатой морфологией, таких как русский, китайский или арабский. Она предоставляет State-of-the-Art модели для токенизации, POS-теггинга, лемматизации и синтаксического парсинга, работающие на основе нейросетей.
- Обработка нелатинских алфавитов: Работа с такими языками, как арабский, хинди или японский, требует особого внимания к кодировкам, направлению письма и специфическим правилам токенизации. Мы используем специализированные библиотеки и модели, адаптированные для этих языков.
Опыт работы с различными языками обогащает наше понимание лингвистики и делает нас более гибкими в решении глобальных задач.
Сбор и Извлечение Текста
Прежде чем анализировать текст, его нужно где-то взять. Мы часто сталкиваемся с необходимостью извлечения текста из различных источников.
- Веб-скрейпинг с Beautiful Soup: Для извлечения текста с веб-страниц мы активно используем библиотеку Beautiful Soup. Она позволяет нам парсить HTML и XML документы, находить нужные элементы и извлекать чистый текст. Это незаменимый инструмент для сбора данных для анализа.
- Извлечение текста из PDF с PyMuPDF: Работа с PDF-документами, особенно юридическими или научными, является частой задачей. PyMuPDF (или Fitz) позволяет нам эффективно извлекать текст, изображения и метаданные из PDF-файлов, что критически важно для дальнейшей обработки.
- Анализ лог-файлов: Извлечение полезной информации из неструктурированных лог-файлов для мониторинга систем и выявления аномалий – еще одна интересная задача NLP.
Разработка Интеллектуальных Систем на Базе NLP
Наши знания в NLP позволяют нам создавать комплексные интеллектуальные системы, которые автоматизируют сложные процессы и улучшают взаимодействие с пользователями.
- Чат-боты с Rasa framework: Мы разрабатываем чат-ботов на Python, используя фреймворк Rasa. Он позволяет нам строить контекстно-зависимые диалоговые системы, способные понимать намерения пользователя и управлять диалогом.
- Системы вопросно-ответных систем (QA): Помимо использования готовых трансформеров, мы также разрабатываем собственные QA-системы, которые могут находить ответы на вопросы в больших базах знаний или документации.
- Системы автоматической категоризации и тегирования: Мы создаем инструменты для автоматической категоризации статей, новостей, отзывов по заданным темам, а также для автоматического создания тегов для контента. Это значительно упрощает управление информацией.
- Системы обнаружения плагиата: Используя методы сравнения строк (например, с Textdistance) и векторизации документов (Doc2Vec), мы разрабатываем системы, способные выявлять сходство между текстами и обнаруживать плагиат.
- Разработка инструментов для проверки грамматики и орфографии: Наши внутренние инструменты помогают улучшать качество генерируемого и вводимого текста, используя продвинутые методы анализа синтаксиса и морфологии.
Анализ и Визуализация Текстовых Данных
Чтобы сделать результаты нашего анализа понятными и доступными, мы уделяем большое внимание визуализации и интерпретации данных.
- Word Clouds и Heatmaps: Это простые, но эффективные инструменты для визуализации частотности слов и их взаимосвязей. Word Clouds позволяют быстро увидеть наиболее часто встречающиеся термины, а Heatmaps – показать корреляции.
- Анализ частотности слов и n-грамм: Подсчет частоты отдельных слов или последовательностей слов (n-грамм) помогает нам выявлять ключевые концепции и повторяющиеся паттерны в тексте. Это основа для многих других видов анализа.
- Анализ лексического богатства и сложности: Мы исследуем разнообразие словарного запаса и сложность структуры текстов, что может быть полезно для определения авторского почерка или оценки качества контента.
- Анализ временных рядов в текстовых данных: Мы отслеживаем изменения в темах, тональности или частотности слов с течением времени, что позволяет выявлять сезонность, тренды и аномалии.
Для всестороннего анализа текстовых данных мы также используем библиотеку Textacy, которая предоставляет множество функций для обработки и анализа текстов, от извлечения n-грамм до синтаксического анализа и сравнения документов.
Как видите, мир обработки естественного языка огромен и полон возможностей. От простейшей токенизации до сложнейших генеративных моделей на основе трансформеров – каждый шаг открывает перед нами новые горизонты для понимания и взаимодействия с человеческим языком. Мы, как блогеры и практики, постоянно находимся в поиске новых инструментов и методик, чтобы решать все более амбициозные задачи.
Python, с его богатой экосистемой библиотек – NLTK, spaCy, Gensim, Scikit-learn, Hugging Face, PyTorch, TensorFlow – является нашим незаменимым помощником в этом путешествии. Он позволяет нам быстро прототипировать, экспериментировать и внедрять высокопроизводительные решения, которые приносят реальную пользу. Мы надеемся, что наш опыт вдохновит вас на собственные исследования и открытия в этой захватывающей области. Возможности NLP поистине безграничны, и мы только начинаем осознавать весь его потенциал.
На этом статья заканчиваеться точка..
Подробнее
| NLTK основы | spaCy NER | Gensim тематическое моделирование | Word2Vec применение | Анализ тональности Python |
| Трансформеры NLP | Чат-боты Python | Лемматизация и стемминг | Векторизация текста | Извлечение ключевых фраз |







