
- Разгадывая Язык Машин: Наш Путь в Мире NLP с Python
- Первые Шаги: Подготовка Текста к Анализу
- Токенизация, Стемминг и Лемматизация: Разбираем Текст на Части
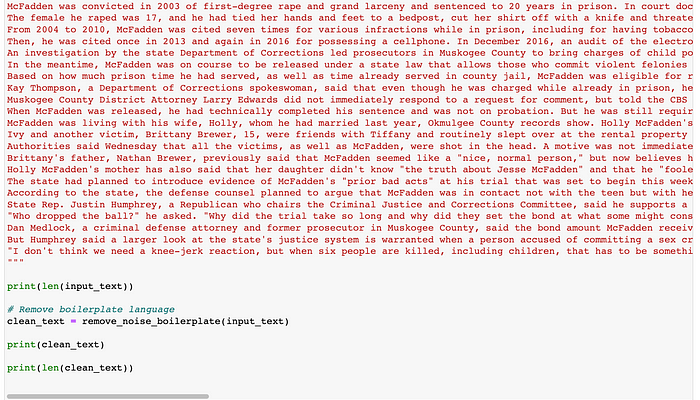
- Регулярные Выражения и Очистка Данных: Наводим Порядок
- Превращая Слова в Числа: Векторизация Текста
- Простые, но Мощные: CountVectorizer и TF-IDF
- Глубокое Понимание: Word Embeddings (Word2Vec, GloVe, FastText)
- Векторизация Документов и Предложений: Doc2Vec и Sentence Transformers
- Извлечение Знаний из Текста: От Сущностей до Тональности
- Распознавание Именованных Сущностей (NER)
- Тематическое Моделирование: Обнаружение Скрытых Тем
- Анализ Тональности (Sentiment Analysis): Чувства в Тексте
- Продвинутые Методы и Глубокое Обучение в NLP
- Трансформеры (Hugging Face) и Контекстные Встраивания
- Классификация Текстов и Нейросети
- Суммаризация Текста и Вопросно-Ответные Системы (QA)
- Специализированные Задачи и Практические Инструменты
- Работа с Разнообразными Источниками и Языками
- Извлечение Ключевых Фраз и Анализ Частотности
- Дополнительные Инструменты и Сценарии Применения
- Будущее NLP: Генерация и Более Глубокое Понимание
Разгадывая Язык Машин: Наш Путь в Мире NLP с Python
Приветствуем вас, дорогие читатели, на страницах нашего блога! Сегодня мы погрузимся в одну из самых увлекательных и быстроразвивающихся областей искусственного интеллекта – обработку естественного языка (Natural Language Processing, NLP). Мы, как команда увлеченных исследователей и практиков, видим, как NLP буквально преобразует способы взаимодействия человека и компьютера. От простых чат-ботов до сложных систем машинного перевода, от анализа настроений в социальных сетях до автоматического суммирования огромных текстов – везде задействованы алгоритмы, способные понимать и генерировать человеческую речь. И лучшим инструментом для этого, по нашему глубокому убеждению, является Python с его невероятно богатой экосистемой библиотек.
Наш путь в NLP начался с чистого любопытства и желания понять, как можно научить компьютер не просто обрабатывать символы, но и осмысливать их. Мы прошли через множество экспериментов, столкнулись с бесчисленными вызовами и открыли для себя мощь инструментов, которые сегодня хотим представить вам. Эта статья – не просто теоретический обзор, а квинтэссенция нашего практического опыта, наших находок и, конечно же, наших любимых библиотек и подходов. Мы покажем вам, как шаг за шагом освоить эту захватывающую область, начиная с самых азов и заканчивая продвинутыми методами, которые лежат в основе современных интеллектуальных систем. Приготовьтесь к увлекательному путешествию, где текст перестает быть просто набором букв и превращается в источник ценной информации и глубоких инсайтов.
Первые Шаги: Подготовка Текста к Анализу
Любое путешествие начинается с первых шагов, и в мире NLP это – предобработка текста. Представьте, что у нас есть огромный массив сырых данных: статьи, отзывы, посты в социальных сетях; Если мы просто бросим их в алгоритм, он ничего не поймет. Текст для машины – это просто последовательность символов, и наша задача – придать ему структуру, сделав его понятным для вычислений. Мы обнаружили, что этот этап критически важен, ведь от качества предобработки напрямую зависит успех всего последующего анализа. Именно здесь Python показывает свою гибкость и мощь.
Токенизация, Стемминг и Лемматизация: Разбираем Текст на Части
Начнем с основ – токенизации. Это процесс разбиения текста на мельчайшие значимые единицы, или "токены". Чаще всего токенами являются слова, но это могут быть и пунктуационные знаки, и даже целые предложения. Мы используем NLTK (Natural Language Toolkit) для этих задач, так как это одна из старейших и наиболее полных библиотек для NLP в Python. Она предоставляет различные токенизаторы, позволяя нам выбрать наиболее подходящий для конкретной задачи. Например, для разбиения текста на слова мы часто применяем `word_tokenize`, а для предложений – `sent_tokenize`.
После токенизации слова могут иметь разные формы: "бежать", "бежит", "бегал", "бегущий". Для многих задач анализа все эти формы должны быть сведены к одной основе. Здесь на помощь приходят стемминг и лемматизация. Стемминг – это процесс отсечения окончаний и суффиксов от слова, чтобы получить его "корень" или "основу". Например, "running" и "runs" могут быть сведены к "run". Мы применяем стеммеры NLTK, такие как PorterStemmer или SnowballStemmer, которые достаточно эффективны для многих языков, включая русский. Однако у стемминга есть недостаток: полученные "корни" часто не являются настоящими словами, что может затруднить интерпретацию.
Например, "красивый", "красивая", "красивые" после стемминга могут превратиться в нечто вроде "красив", что не является полноценным словом. Это, конечно, не всегда критично для машинных алгоритмов, но для человека может быть немного странно.
Лемматизация – это более продвинутый процесс, который сводит слово к его базовой словарной форме (лемме), которая всегда является существующим словом. Например, "бегущий", "бежать", "бежал" будут сведены к "бежать". Для качественной лемматизации нам нужна информация о части речи слова, и здесь мы активно используем spaCy. spaCy – это высокопроизводительная библиотека, которая предоставляет готовые модели для различных языков, способные выполнять токенизацию, POS-теггинг (определение частей речи) и лемматизацию с высокой точностью и скоростью. Мы часто сравниваем методы лемматизации SpaCy и NLTK, и для языков с богатой морфологией, таких как русский, SpaCy часто показывает себя лучше, благодаря своим более сложным моделям.
Регулярные Выражения и Очистка Данных: Наводим Порядок
Предобработка не ограничивается только токенизацией и лемматизацией. Сырой текст часто содержит много "шума": HTML-теги, специальные символы, лишние пробелы, URL-адреса, эмодзи, сленг. Мы активно используем регулярные выражения (модуль `re` в Python) для очистки данных. С их помощью мы можем удалять теги, заменять множественные пробелы на одиночные, извлекать или удалять определенные паттерны. Например, для удаления HTML-тегов мы часто применяем `re.sub(r'<.*?>’, », text)`.
Когда мы работаем с данными из социальных сетей, нам приходится сталкиваться со сленгом, сокращениями и эмодзи. Для этого мы разрабатываем собственные инструменты для нормализации сленга, создаем словари для замены эмодзи на текстовые описания и даже пытаемся автоматически проверять грамматику и орфографию, чтобы улучшить качество входных данных.
Важно также помнить о стоп-словах – это часто встречающиеся слова (например, "и", "в", "на", "он"), которые обычно не несут смысловой нагрузки для анализа. Мы их удаляем, чтобы уменьшить размерность данных и сосредоточиться на более значимых словах. NLTK предоставляет списки стоп-слов для многих языков, но мы часто дополняем их собственными, специфичными для конкретной предметной области.
Превращая Слова в Числа: Векторизация Текста
После того как текст очищен и разбит на токены, возникает вопрос: как научить машину "понимать" эти слова? Компьютеры работают с числами, а не с текстом. Поэтому следующий критически важный этап – это векторизация текста, то есть преобразование слов и документов в числовые векторы. Этот процесс лежит в основе почти всех задач NLP. Мы исследовали множество методов и хотим поделиться нашими излюбленными.
Простые, но Мощные: CountVectorizer и TF-IDF
Самые простые, но часто очень эффективные методы векторизации – это CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn.
CountVectorizer: Этот метод просто подсчитывает частоту вхождения каждого слова в каждом документе. Результатом является матрица, где строки соответствуют документам, столбцы – уникальным словам в корпусе, а значения – количеству вхождений слова в документ. Это отличная отправная точка, но у нее есть недостаток: она не учитывает важность слова. Слово, которое встречается часто во всех документах (например, "вода" в статьях о гидрологии), может иметь высокую частоту, но низкую информативность.
TfidfVectorizer (Term Frequency-Inverse Document Frequency): Мы часто используем TF-IDF, когда нам нужно учесть не только частоту слова в документе, но и его редкость во всем корпусе. TF-IDF присваивает более высокий вес словам, которые часто встречаются в одном документе, но редко – в других. Это помогает выделить слова, которые действительно характеризуют конкретный документ. Мы проводили сравнение различных методов векторизации, и для многих задач классификации текстов TF-IDF до сих пор остается сильным базовым методом.
Пример использования TF-IDF: Представьте, что мы анализируем отзывы клиентов. Слово "отлично" может встречаться часто. Но если оно встречается почти во всех отзывах, его TF-IDF вес будет ниже, чем у слова "аккумулятор", которое встречается только в отзывах о продукте с проблемами с батареей. Таким образом, "аккумулятор" будет более значимым для выявления проблемы.
Глубокое Понимание: Word Embeddings (Word2Vec, GloVe, FastText)
Современные методы векторизации пошли гораздо дальше, пытаясь уловить семантическую связь между словами; Это так называемые Word Embeddings (векторные представления слов). Мы активно используем Gensim – мощную библиотеку для тематического моделирования и работы с векторными представлениями.
Word2Vec: Это, пожалуй, самый известный метод. Он учит нейронную сеть предсказывать соседние слова (skip-gram) или предсказывать текущее слово по контексту (CBOW). Результатом являются плотные векторы (обычно 100-300 измерений) для каждого слова, где слова с похожим значением имеют близкие векторные представления в многомерном пространстве. Мы использовали Gensim для обучения собственных моделей Word2Vec на больших корпусах текстов и сравнивали Word2Vec (Skip-gram vs CBOW), обнаруживая, что Skip-gram часто лучше работает для редких слов.
GloVe (Global Vectors for Word Representation): Другой популярный метод, который основан на матрице ко-встречаемости слов. Он пытается объединить преимущества глобальных статистических методов (как в TF-IDF) и локальных контекстно-зависимых методов (как в Word2Vec).
FastText: Разработанный Facebook AI, FastText – это расширение Word2Vec, которое учитывает подсловные единицы (n-граммы символов). Это делает его особенно эффективным для работы с редкими словами и языками с богатой морфологией, а также позволяет получать векторные представления для слов, которых не было в обучающем корпусе. Мы часто обращаемся к FastText при работе с многоязычными текстовыми корпусами или когда сталкиваемся с большим количеством опечаток.
Эти методы позволяют нам не только сравнивать слова по их значению (например, "король" и "королева" будут близки, а "король" и "яблоко" – далеки), но и выполнять векторную арифметику, например, "король" ─ "мужчина" + "женщина" = "королева". Это открывает совершенно новые горизонты для анализа.
Векторизация Документов и Предложений: Doc2Vec и Sentence Transformers
Иногда нам нужно получить векторное представление не только для отдельных слов, но и для целых предложений или документов.
Doc2Vec (Paragraph Vector): Также разработанный Google и доступный в Gensim, Doc2Vec является расширением Word2Vec, которое может создавать векторные представления для целых документов. Мы применяем Doc2Vec для представления целых документов, что позволяет нам сравнивать их по смыслу, находить похожие статьи или кластеризовать их.
Sentence Transformers: Это более современные модели, основанные на архитектуре трансформеров, которые специализируются на получении высококачественных эмбеддингов для предложений. Они показывают отличные результаты в задачах измерения сходства предложений, семантического поиска и кластеризации текстов. Мы активно используем Sentence Transformers для контекстного встраивания, что позволяет учитывать не только значение слова, но и его контекст в предложении.
Извлечение Знаний из Текста: От Сущностей до Тональности
Когда у нас есть числовые представления текста, мы можем начать извлекать из него ценную информацию. Это сердцевина NLP – превращение хаотичных данных в структурированные знания. Мы использовали эти методы для самых разнообразных задач, от анализа отзывов до автоматической категоризации статей.
Распознавание Именованных Сущностей (NER)
NER – это задача по идентификации и классификации именованных сущностей в тексте, таких как имена людей, названия организаций, географические места, даты и т.д. Это крайне полезно для структурирования информации.
spaCy для быстрого NER: Мы считаем spaCy одним из лучших инструментов для NER благодаря его готовым, высокопроизводительным моделям. Он способен быстро и точно извлекать сущности из текста; Для русского языка Stanza также предоставляет мощные возможности для NER, особенно для языков с богатой морфологией.
CRF и Flair: Для более сложных или специфических задач NER, особенно когда нам нужна тонкая настройка под конкретный домен, мы можем использовать условные случайные поля (CRF) или библиотеку Flair, которая предоставляет state-of-the-art модели NER, основанные на глубоком обучении. Мы также применяем BERT для задачи NER, так как трансформеры демонстрируют выдающиеся результаты. Мы разработали системы для автоматической разметки сущностей, что значительно ускоряет процесс подготовки данных для обучения.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут." – Рита Мэй Браун.
Тематическое Моделирование: Обнаружение Скрытых Тем
Часто в больших коллекциях документов нам нужно понять, о каких основных темах идет речь. Тематическое моделирование позволяет нам автоматически обнаруживать скрытые "темы" в корпусе текстов, представляя каждый документ как смесь нескольких тем, а каждую тему – как распределение слов.
LDA и LSI с Gensim: Мы активно используем библиотеку Gensim для тематического моделирования, в частности, для алгоритмов LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing). LDA – это вероятностная модель, которая предполагает, что каждый документ состоит из смеси тем, а каждая тема – из смеси слов. LSI же использует сингулярное разложение для выявления латентных семантических структур. Мы проводили сравнение моделей тематического моделирования (LDA vs NMF) и обнаружили, что выбор модели сильно зависит от характеристик данных и целей анализа. Gensim отлично подходит для анализа больших данных и построения языковых моделей.
NMF (Non-negative Matrix Factorization): Еще один эффективный метод тематического моделирования, доступный в Scikit-learn, который мы также применяем. NMF хорошо интерпретируем и часто дает отличные результаты.
Мы используем тематическое моделирование для анализа отзывов клиентов по категориям, выявления скрытых тем в новостных статьях и даже для автоматической категоризации статей.
Анализ Тональности (Sentiment Analysis): Чувства в Тексте
Понимание эмоциональной окраски текста – это крайне востребованная задача, особенно для бизнеса. Отзывы о продуктах, посты в социальных сетях, новостные статьи – все это может нести позитивную, негативную или нейтральную тональность.
VADER для простого анализа: Для быстрого и эффективного анализа тональности англоязычных текстов мы часто используем VADER (Valence Aware Dictionary and sEntiment Reasoner). Это лексически-ориентированный анализатор, который учитывает не только слова, но и их интенсивность, использование заглавных букв, пунктуацию и смайлики.
TextBlob для простого NLP: TextBlob – это еще одна удобная библиотека для быстрого анализа тональности, а также других простых задач NLP, таких как POS-теггинг и извлечение n-грамм. Мы используем TextBlob для определения языка и анализа тональности сообщений в социальных сетях.
Сложности и Подходы: Анализ тональности не всегда прост. Сарказм, ирония, двойные отрицания – все это бросает вызов алгоритмам. Для более сложных задач, особенно для анализа тональности в социальных сетях с учетом сарказма или анализа финансовых новостей, мы применяем более продвинутые модели на основе машинного обучения (SVM, наивный байесовский классификатор) или даже трансформеров, которые могут улавливать тонкие нюансы контекста. Мы также разрабатываем системы для анализа тональности сообщений в социальных сетях (Twitter/Reddit), учитывая специфику этих платформ.
Продвинутые Методы и Глубокое Обучение в NLP
С развитием глубокого обучения, область NLP пережила настоящую революцию. Трансформеры, нейронные сети – все это открыло двери для решения задач, которые раньше казались невыполнимыми. Мы активно внедряем эти методы в нашу работу.
Трансформеры (Hugging Face) и Контекстные Встраивания
Трансформерные модели, такие как BERT, GPT, RoBERTa, стали настоящим прорывом. Они способны улавливать сложнейшие зависимости в языке благодаря своей архитектуре внимания (attention mechanism).
Hugging Face Transformers: Это де-факто стандарт для работы с трансформерными моделями. Библиотека предоставляет доступ к сотням предварительно обученных моделей для широкого спектра задач: классификация, NER, суммаризация, вопросно-ответные системы, генерация текста и многое другое. Мы используем трансформеры для сложных задач NLP, таких как генерация текста (GPT), машинный перевод, суммаризация и даже для анализа кода.
Fine-tuning: Одним из главных преимуществ этих моделей является возможность тонкой настройки (Fine-tuning) предварительно обученных моделей под конкретную задачу и набор данных. Это позволяет достигать выдающихся результатов даже с относительно небольшим объемом размеченных данных. Мы применяем BERT для задач классификации и NER, а также для выявления связей между сущностями.
Классификация Текстов и Нейросети
Классификация текста – это одна из самых распространенных задач NLP, будь то спам-фильтрация, категоризация новостей или анализ отзывов.
Scikit-learn для классификации: Для многих задач мы начинаем с классических методов машинного обучения, таких как SVM (Support Vector Machines) и наивный байесовский классификатор, доступных в Scikit-learn. Они просты в использовании и часто дают хорошие базовые результаты. Мы сравнивали различные методы машинного обучения для NLP и убедились, что для некоторых задач "старые" методы все еще очень актуальны.
PyTorch/TensorFlow для нейросетей: Для более сложных задач, где требуется улавливать глубокие паттерны, мы обращаемся к нейронным сетям. Мы используем PyTorch/TensorFlow для создания LSTM-сетей, которые отлично подходят для последовательных данных, таких как текст. С появлением трансформеров, мы все чаще применяем их для классификации текста, достигая state-of-the-art результатов.
Суммаризация Текста и Вопросно-Ответные Системы (QA)
Автоматическое создание кратких изложений текста или ответы на вопросы – это задачи, которые требуют глубокого понимания текста.
Суммаризация: Различают экстрактивную и абстрактивную суммаризацию.
Экстрактивная суммаризация: Выбирает наиболее важные предложения из оригинального текста. Мы используем TextRank (алгоритм, основанный на PageRank) для извлечения ключевых предложений или даже целых тем.
Абстрактивная суммаризация: Генерирует новые предложения, которые передают суть оригинального текста. Это гораздо сложнее и обычно требует трансформерных моделей (Hugging Face). Мы сравнивали модели суммаризации (экстрактивная и абстрактная) и применяем Transformer-модели для суммаризации.
Вопросно-ответные системы (QA): Эти системы способны отвечать на вопросы, основываясь на заданном тексте или корпусе документов. Разработка таких систем – одна из самых сложных и интересных задач в NLP, часто требующая использования продвинутых трансформерных архитектур. Мы разрабатываем системы вопросно-ответных систем, используя PyTorch/TensorFlow и Hugging Face.
Специализированные Задачи и Практические Инструменты
Мир NLP огромен, и помимо основных задач, существует множество специализированных приложений, которые мы активно исследуем и внедряем.
Работа с Разнообразными Источниками и Языками
Веб-скрейпинг текста (Beautiful Soup): Прежде чем мы сможем анализировать текст, его нужно откуда-то получить. Для извлечения текстовых данных с веб-сайтов мы активно используем библиотеку Beautiful Soup. Она позволяет нам парсить HTML и XML документы, выделяя нужные блоки текста.
Извлечение текста из PDF (PyMuPDF): Часто данные приходят в виде PDF-файлов. PyMuPDF – это мощная библиотека для работы с PDF, позволяющая нам эффективно извлекать текст из этих документов.
Многоязычный NLP (Polyglot, Stanza): Работа с текстами на разных языках – это отдельный вызов. Polyglot и Stanza предоставляют инструменты для обработки многоязычных текстовых корпусов, включая токенизацию, NER, POS-теггинг и лемматизацию для языков с богатой морфологией, таких как русский. Мы используем Polyglot для анализа редких языков и Stanza для русского языка.
Извлечение Ключевых Фраз и Анализ Частотности
RAKE и TextRank: Для быстрого извлечения ключевых фраз из текста мы используем алгоритмы RAKE (Rapid Automatic Keyword Extraction) и TextRank. RAKE основан на частоте слов и их ко-встречаемости, в то время как TextRank использует графовые модели для определения важности слов и предложений. Мы применяем RAKE для извлечения ключевых слов и TextRank для извлечения ключевых предложений и выделения тем.
Анализ частотности слов и n-грамм: Простой, но часто очень информативный метод – подсчет частоты слов и n-грамм (последовательностей из N слов). Это помогает выявить наиболее распространенные термины, типичные фразы и даже построить простые языковые модели на основе N-грамм. Мы также анализируем частотность редких слов и их значение.
| Метод | Описание | Библиотеки/Инструменты |
|---|---|---|
| Токенизация | Разбиение текста на слова или предложения. | NLTK, spaCy |
| Лемматизация | Приведение слов к их словарной форме. | spaCy, NLTK (WordNetLemmatizer) |
| Векторизация | Преобразование текста в числовые векторы. | Scikit-learn (TF-IDF), Gensim (Word2Vec, Doc2Vec), Hugging Face (Transformers) |
| NER | Распознавание именованных сущностей. | spaCy, Flair, Hugging Face |
| Анализ тональности | Определение эмоциональной окраски текста. | VADER, TextBlob, Scikit-learn, Hugging Face |
Дополнительные Инструменты и Сценарии Применения
TextBlob: ограничения и альтернативы: Хотя TextBlob удобен для простых задач, для более глубокого анализа мы часто ищем альтернативы, особенно когда речь идет о производительности или специфических требованиях языка.
Textacy: Это более продвинутая библиотека для NLP, построенная на spaCy, которая предоставляет расширенные возможности для извлечения информации, анализа зависимостей и других сложных задач. Мы используем Textacy для извлечения информации и работы с зависимостями.
Визуализация текстовых данных: Чтобы сделать результаты анализа понятными, мы активно используем инструменты визуализации, такие как Word Clouds (облака слов) для отображения частотности слов и Heatmaps для визуализации матриц сходства.
Разработка чат-ботов (Rasa framework): Это одна из самых захватывающих областей применения NLP. Мы разрабатываем чат-ботов на Python, используя фреймворк Rasa, который позволяет создавать мощных и контекстно-осведомленных ассистентов.
Анализ стилистики текстов (авторский почерк): Это интересная задача, где NLP помогает определить авторство текста, анализируя уникальные лексические и синтаксические паттерны. Мы разрабатываем системы для определения авторства текста и стиля письма.
Обнаружение плагиата (Jellyfish, TextDistance): Сравнение строк и документов на предмет схожести – важная задача. Библиотеки Jellyfish и TextDistance предоставляют различные метрики для измерения сходства строк и документов, что мы используем для поиска дубликатов и обнаружения плагиата.
Обработка больших текстовых массивов (Big Data NLP): Когда речь идет о гигабайтах или терабайтах текста, нам приходится применять специализированные подходы и инструменты, которые могут масштабироваться. Gensim, с его оптимизированными алгоритмами, часто становится нашим выбором для таких задач.
Обработка неполных и ошибочных данных: В реальном мире данные редко бывают идеальными. Мы сталкиваемся с проблемами обработки неполных и ошибочных данных, и для этого разрабатываем инструменты для исправления орфографии и проверки грамматики.
Наш опыт показывает: Чем больше данных, тем важнее становится этап предобработки. Некачественные входные данные приведут к некачественным результатам, даже если вы используете самые продвинутые модели.
Будущее NLP: Генерация и Более Глубокое Понимание
Генерация текста (GPT, Transformer-модели): Возможности генерации текста с помощью трансформерных моделей, таких как GPT-3, GPT-4, поражают воображение. Мы используем Transformer-модели для генерации диалогов, кода, и даже целых статей.
Анализ текста в режиме реального времени (Streaming NLP): Для некоторых приложений требуется обрабатывать текст "на лету", например, для мониторинга социальных сетей или анализа лог-файлов. Это требует оптимизированных алгоритмов и архитектур.
GPU-ускорение: Для работы с большими моделями глубокого обучения и огромными объемами данных мы активно используем GPU-ускорение, что значительно сокращает время обучения и инференса.
Распознавание речи (Speech-to-Text): Хотя это не совсем текстовый NLP, преобразование речи в текст (например, с помощью библиотеки Gentle) является важным шагом для дальнейшего анализа устной речи методами NLP.
- Начните с основ: Освойте NLTK и spaCy для предобработки.
- Изучите векторизацию: Поймите разницу между TF-IDF и Word Embeddings.
- Экспериментируйте с задачами: Попробуйте NER, анализ тональности, тематическое моделирование.
- Примите трансформеры: Hugging Face – ваш лучший друг для современного NLP.
- Практикуйтесь: Только через решение реальных задач приходит истинное понимание.
Наш опыт показывает, что мир NLP на Python – это безграничное поле для экспериментов и открытий. От простых скриптов для подсчета слов до сложных нейронных сетей, способных генерировать человеческий текст, – каждый шаг в этой области приносит новые знания и возможности. Мы видим, как NLP проникает во все сферы жизни, автоматизируя рутинные задачи, помогая извлекать ценную информацию из огромных массивов данных и даже создавая новые формы взаимодействия.
Мы надеемся, что эта статья вдохновила вас на собственные исследования и помогла понять, насколько мощным и доступным стал NLP благодаря таким библиотекам, как NLTK, spaCy, Gensim, Scikit-learn и Hugging Face. Не бойтесь экспериментировать, ведь именно в процессе проб и ошибок рождаются самые интересные решения. Python предоставляет вам все необходимые инструменты, а наше сообщество всегда готово поддержать. Продолжайте учиться, продолжайте творить, и мы уверены, что вы сможете добиться впечатляющих результатов в этой захватывающей области. До новых встреч на страницах нашего блога!
Подробнее
| Основы токенизации NLTK | NER с использованием spaCy | Векторизация текста TF-IDF | Word2Vec в Gensim | Анализ тональности VADER |
| Тематическое моделирование LDA | Трансформеры Hugging Face | Классификация текстов Scikit-learn | Разработка чат-ботов Python | Лемматизация vs Стемминг |





