
- От Хаоса к Смыслу: Наш Путь в Мире Обработки Естественного Языка (NLP) на Python
- Первые Шаги: Разбираем Текст на Элементы
- Токенизация: От Строки к Словам
- Стемминг и Лемматизация: Приводим Слова к Нормальной Форме
- Очистка Текста: Избавляемся от Шума
- Превращаем Слова в Числа: Векторизация
- Классические Методы: CountVectorizer и TF-IDF
- Word Embeddings: Слово имеет Контекст
- Сравнение методов векторизации:
- Основные Задачи NLP: От Сущностей до Настроений
- Распознавание Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis)
- Тематическое Моделирование (Topic Modeling)
- Классификация Текстов
- Продвинутые Технологии: Эпоха Трансформеров
- Hugging Face и Предварительно Обученные Модели
- Генерация Текста и Чат-боты
- Прикладные Аспекты и Нишевые Задачи
- Работа с Различными Типами Текстов
- Извлечение Информации и Знаний
- Мультиязычный NLP и Сложности
- Качество Текста и Анализ Стиля
- Визуализация и Большие Данные
От Хаоса к Смыслу: Наш Путь в Мире Обработки Естественного Языка (NLP) на Python
Приветствуем вас‚ дорогие читатели и коллеги-энтузиасты! Сегодня мы хотим поделиться с вами нашим глубоким погружением в одну из самых захватывающих и быстро развивающихся областей современного программирования – обработку естественного языка‚ или NLP․ Мы‚ как команда опытных блогеров‚ всегда стремимся не просто рассказывать о технологиях‚ но и показывать их на реальных примерах‚ через призму собственного опыта․ И поверьте‚ наш путь в NLP был полон открытий‚ вызовов и невероятных достижений‚ которыми мы с радостью поделимся․
В мире‚ где информация является ключевым ресурсом‚ способность машин понимать‚ интерпретировать и генерировать человеческий язык становится не просто полезной‚ а абсолютно необходимой․ От голосовых помощников до систем анализа настроений в социальных сетях‚ от автоматического перевода до интеллектуальных поисковых систем – NLP проникает во все сферы нашей жизни․ Мы видим‚ как Python‚ благодаря своей гибкости и богатой экосистеме библиотек‚ стал де-факто стандартом для разработки NLP-решений․ Давайте вместе исследуем этот удивительный мир‚ начиная с самых основ и доходя до передовых моделей‚ меняющих наше представление о взаимодействии человека и машины․
Первые Шаги: Разбираем Текст на Элементы
Прежде чем машина сможет "понять" текст‚ его нужно подготовить․ Это похоже на то‚ как мы‚ люди‚ сначала учимся различать буквы‚ затем слова‚ а потом уже предложения․ В NLP этот этап называется предобработкой‚ и он является краеугольным камнем любой успешной системы․ Без качественно предобработанных данных дальнейшие алгоритмы будут работать неэффективно‚ а их результаты могут быть совершенно бесполезными․
Наш опыт показывает‚ что пренебрежение этим этапом – одна из самых распространённых ошибок новичков․ Мы всегда уделяем особое внимание тщательной подготовке текстовых данных‚ потому что именно здесь закладывается фундамент для всех последующих сложных операций․ Давайте рассмотрим основные инструменты‚ которые мы используем для этого․
Токенизация: От Строки к Словам
Начать работу с текстом всегда приходится с его разбиения на более мелкие‚ осмысленные единицы – токены․ Это могут быть слова‚ пунктуационные знаки‚ или даже целые предложения․ Процесс называется токенизацией․ Мы активно используем для этого библиотеку NLTK (Natural Language Toolkit)‚ которая предоставляет целый арсенал токенизаторов‚ подходящих для разных задач и языков․
Например‚ для большинства западных языков мы часто применяем word_tokenize для разделения на слова и sent_tokenize для разделения на предложения․ Однако‚ когда мы сталкиваемся с более сложными случаями‚ такими как слитные слова в немецком или иероглифы в китайском‚ мы понимаем‚ что универсального решения не существует‚ и иногда приходится разрабатывать собственные‚ более специализированные токенизаторы или использовать модели‚ обученные на конкретных языках․ Сравнение эффективности различных токенизаторов стало для нас отдельной увлекательной задачей․
Стемминг и Лемматизация: Приводим Слова к Нормальной Форме
После токенизации мы часто сталкиваемся с проблемой‚ что одно и то же слово может иметь множество форм: "бегать"‚ "бегал"‚ "бегущий"‚ "бегающие"․ Для компьютера это разные слова‚ хотя для нас они связаны одним корнем․ Здесь на помощь приходят стемминг и лемматизация․ Стемминг отсекает окончания‚ пытаясь найти "корень" слова (например‚ "бег" от всех форм "бегать")․ Это быстрый‚ но иногда грубый метод‚ который может привести к "несуществующим" словам․
Лемматизация же более умна: она приводит слово к его словарной или базовой форме (лемме) с учетом его части речи․ Например‚ "бегающие" станет "бегать"․ Мы предпочитаем лемматизацию‚ особенно для задач‚ где важна точность‚ и часто используем для этого spaCy или продвинутую лемматизацию из Stanza‚ особенно для языков с богатой морфологией‚ таких как русский․ NLTK также предлагает свои лемматизаторы‚ но мы заметили‚ что spaCy и Stanza часто показывают лучшие результаты в комплексных сценариях‚ особенно когда дело касается контекста․
| Метод | Описание | Преимущества | Недостатки | Примеры библиотек |
|---|---|---|---|---|
| Стемминг | Отсечение суффиксов и префиксов для получения основы слова․ | Быстрый‚ простой в реализации․ | Может создавать несуществующие слова‚ теряет часть информации․ | NLTK (Porter‚ Snowball) |
| Лемматизация | Приведение слова к его словарной (базовой) форме с учетом контекста и части речи․ | Точнее‚ сохраняет смысл слова‚ создает реальные слова․ | Медленнее‚ требует больше ресурсов (модели)‚ сложнее․ | SpaCy‚ NLTK (WordNetLemmatizer)‚ Stanza |
Очистка Текста: Избавляемся от Шума
Помимо токенизации и нормализации‚ мы постоянно сталкиваемся с необходимостью очистки данных․ Это включает удаление стоп-слов (артикли‚ предлоги‚ союзы‚ которые не несут смысловой нагрузки)‚ пунктуации‚ чисел‚ HTML-тегов (если текст был получен из веб-страниц с помощью Beautiful Soup)‚ а также работу с эмодзи и сленгом в современных текстах‚ особенно из социальных сетей․ Мы используем регулярные выражения (модуль re в Python) для эффективной и гибкой обработки этих задач․
Например‚ для анализа отзывов клиентов или сообщений в социальных сетях (Twitter/Reddit)‚ где много сленга‚ аббревиатур и эмодзи‚ мы часто разрабатываем собственные словари и инструменты для нормализации сленга․ Проблемы обработки неполных и ошибочных данных – это наша ежедневная реальность‚ и мы учимся создавать надежные конвейеры предобработки‚ которые могут справиться с любым "грязным" текстом․
Превращаем Слова в Числа: Векторизация
Компьютеры не могут напрямую работать со словами․ Им нужны числа․ Поэтому следующий важнейший этап – это преобразование текстовых данных в числовые векторы․ Этот процесс называется векторизацией․
Классические Методы: CountVectorizer и TF-IDF
Мы начинали с простых‚ но эффективных методов‚ таких как CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn․ CountVectorizer просто подсчитывает частоту каждого слова в документе‚ создавая вектор․ TF-IDF (Term Frequency-Inverse Document Frequency) идет дальше‚ взвешивая частоту слова в документе с его редкостью во всем корпусе․ Это позволяет нам выделять слова‚ которые действительно важны для конкретного документа‚ а не просто часто встречаются везде․
Эти методы отлично работают для многих задач классификации текстов и анализа частотности слов и n-грамм․ Мы используем их для создания собственных векторизаторов текста и для анализа больших текстовых массивов‚ когда производительность имеет значение․
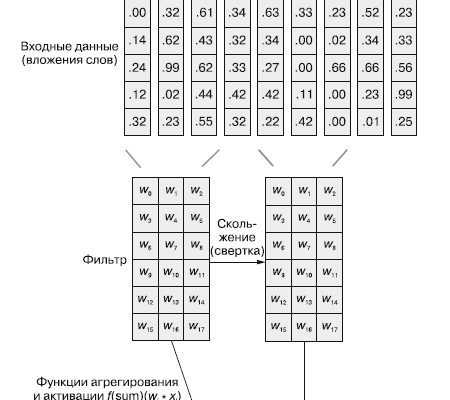
Word Embeddings: Слово имеет Контекст
Однако классические методы имеют один существенный недостаток: они не учитывают семантическую связь между словами․ "Кошка" и "кот" для них – это совершенно разные сущности․ Здесь на сцену выходят Word Embeddings (векторные представления слов)‚ такие как Word2Vec и GloVe․ Мы используем библиотеку Gensim для работы с ними․ Эти модели обучаются на огромных текстовых корпусах и создают плотные векторы‚ где слова со схожим значением располагаются близко друг к другу в многомерном пространстве․
Мы также активно применяем FastText‚ который особенно хорошо справляется с редкими словами и языками с богатой морфологией‚ так как он учитывает подслова․ Для представления целых документов или даже предложений мы используем Doc2Vec‚ который также доступен в Gensim․ Эти методы позволяют нам векторизовать текст с учетом контекста‚ что является огромным прорывом в NLP․
Сравнение методов векторизации:
- TF-IDF: Отлично для определения важности слова в документе относительно корпуса․ Прост‚ быстр․
- Word2Vec/GloVe: Улавливают семантические связи между словами‚ но могут испытывать трудности с редкими словами․
- FastText: Улучшенный вариант Word2Vec‚ хорошо работает с редкими словами и опечатками․
- Doc2Vec: Расширение Word2Vec для векторизации целых документов‚ сохраняя их смысл․
- Контекстное встраивание (BERT‚ ELMo): Самый продвинутый подход‚ где вектор слова меняется в зависимости от его контекста в предложении․
Основные Задачи NLP: От Сущностей до Настроений
После того как текст подготовлен и векторизован‚ мы можем приступать к решению конкретных задач․ NLP предлагает широкий спектр возможностей‚ и мы активно применяем их в наших проектах․
Распознавание Именованных Сущностей (NER)
Представьте‚ что вам нужно извлечь все имена людей‚ названия организаций‚ локации или даты из большого объема текста․ Это задача NER (Named Entity Recognition)․ Мы используем spaCy для быстрого и эффективного NER‚ а также Flair для современного NER‚ который часто показывает выдающиеся результаты благодаря контекстным встраиваниям․ Когда требуются более тонкие настройки или работа с небольшими‚ специфическими наборами данных‚ мы обращаемся к CRF (Conditional Random Fields)‚ что позволяет нам разрабатывать системы для автоматической разметки сущностей и извлечения дат и событий․
Анализ Тональности (Sentiment Analysis)
Понимание эмоциональной окраски текста – это мощный инструмент для бизнеса‚ маркетинга и даже политики․ Мы проводим анализ тональности для отзывов клиентов‚ сообщений в социальных сетях‚ финансовых новостей и даже постов о политике․ Для простых задач мы используем VADER (Valence Aware Dictionary and sEntiment Reasoner) и TextBlob‚ которые отлично подходят для английского языка и не требуют предварительного обучения․
Однако‚ когда речь заходит о более сложных случаях‚ таких как сарказм‚ ирония или нюансы русского языка‚ мы начинаем применять более продвинутые методы‚ включая тонкую настройку трансформерных моделей․ Анализ тональности сообщений в социальных сетях (Twitter/Reddit) с учетом сарказма – это отдельная большая и интересная задача‚ где мы постоянно ищем новые подходы․
"Язык – это не просто набор слов; это зеркало‚ отражающее мысли‚ чувства и культуру человечества․ Понять его – значит приоткрыть завесу над самим сознанием․"
— Стивен Пинкер (известный когнитивный психолог и лингвист)
Тематическое Моделирование (Topic Modeling)
Иногда нам нужно понять‚ о чем в целом говорится в большом корпусе документов‚ не читая каждый из них․ Здесь на помощь приходит тематическое моделирование․ Библиотека Gensim предоставляет отличные реализации для LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing)․ Мы также сравниваем эти модели с NMF (Non-negative Matrix Factorization)‚ чтобы выбрать наиболее подходящий подход для конкретной задачи‚ например‚ для анализа скрытых тем в отзывах о продуктах или для категоризации статей․
Мы также используем TextRank для выделения тем и извлечения ключевых предложений‚ что является эффективным методом для суммирования и поиска основных идей в тексте․ Анализ текста для выявления скрытых тем помогает нам глубже понять данные‚ с которыми мы работаем․
Классификация Текстов
Классификация – одна из самых распространённых задач в NLP: от спам-фильтров до автоматической категоризации новостей․ Мы применяем Scikit-learn для классификации текстов‚ используя различные алгоритмы машинного обучения‚ такие как SVM (Support Vector Machines) и наивный байесовский классификатор․ Когда данных много и требуется высокая точность‚ мы переходим к более мощным моделям‚ таким как BERT для задач классификации‚ а также к реализации классификации текста с использованием PyTorch/TensorFlow для создания нейросетей NLP‚ включая LSTM-сети․
Сравнение моделей машинного обучения для NLP (SVM‚ наивный байесовский классификатор) – это постоянный процесс оптимизации‚ который позволяет нам выбирать наилучшие подходы для каждого конкретного случая․
Продвинутые Технологии: Эпоха Трансформеров
Последние годы ознаменовались революцией в NLP благодаря появлению трансформерных архитектур․ Эти модели изменили всё‚ значительно превзойдя предыдущие подходы в большинстве задач․
Hugging Face и Предварительно Обученные Модели
Мы активно используем библиотеку Hugging Face Transformers‚ которая стала золотым стандартом для работы с моделями‚ такими как BERT‚ GPT‚ RoBERTa и многими другими․ Эти модели предварительно обучены на огромных объемах текста и способны понимать сложный контекст‚ что открывает невероятные возможности для решения самых сложных задач NLP․
Тонкая настройка (Fine-tuning) предварительно обученных моделей под наши специфические задачи позволяет нам достигать впечатляющих результатов даже с относительно небольшими наборами данных․ Это особенно актуально для задач‚ где нужны глубокие контекстные представления‚ таких как распознавание эмоций‚ анализ тональности с учетом сарказма‚ или разработка моделей для выявления связей между сущностями․
Генерация Текста и Чат-боты
С появлением трансформеров‚ таких как GPT‚ возможности генерации текста вышли на совершенно новый уровень․ Мы экспериментируем с использованием Transformer-моделей для генерации текста (например‚ для создания рекламных слоганов‚ описаний продуктов) и даже для генерации кода․ Это открывает путь к разработке более умных чат-ботов на Python (например‚ с использованием Rasa framework) и систем вопросно-ответных систем (QA)‚ которые могут понимать сложные вопросы и генерировать связные и релевантные ответы․
Использование Transformer-моделей для генерации диалогов позволяет нам создавать более естественные и интерактивные пользовательские интерфейсы․ Мы видим‚ как эти технологии меняют представление о взаимодействии человека с компьютером․
Прикладные Аспекты и Нишевые Задачи
NLP – это не только фундаментальные алгоритмы‚ но и бесчисленное множество практических приложений‚ которые решают реальные проблемы․
Работа с Различными Типами Текстов
Нам часто приходится работать с очень специфическими типами текстов․ Например‚ использование Python для анализа юридических документов требует особого внимания к деталям и точности‚ так как любая ошибка может иметь серьезные последствия․ Аналогично‚ анализ текста в медицинских записях или финансовой отчетности требует глубоких предметных знаний и специализированных инструментов․
Мы также используем PyMuPDF для извлечения текста из PDF‚ что является неотъемлемой частью работы с отсканированными документами или отчетами․ А анализ лог-файлов помогает нам выявлять аномалии и проблемы в работе систем․
Извлечение Информации и Знаний
Извлечение ключевых фраз‚ ключевых слов (с помощью RAKE или TextRank)‚ а также фактов из новостей – это задачи‚ которые мы решаем ежедневно․ Библиотека Textacy предоставляет нам мощные инструменты для извлечения информации и работы с зависимостями в тексте‚ что позволяет нам строить более сложные системы анализа․
Мы также занимаемся разработкой систем для автоматического тегирования контента и категоризации новостей‚ что значительно упрощает навигацию и поиск информации в больших базах данных․ Создание словарей и тезаурусов – это ещё одна область‚ где мы активно работаем для улучшения качества извлечения информации․
Мультиязычный NLP и Сложности
Мир не ограничивается одним языком‚ и мы часто работаем с многоязычными текстовыми корпусами․ Библиотеки Polyglot и Stanza (особенно для языков с богатой морфологией‚ как русский) позволяют нам преодолевать языковые барьеры․ Обработка нелатинских алфавитов в Python NLP – это отдельная задача‚ требующая внимательного подхода․
Разработка систем машинного перевода на Python‚ особенно узкоспециализированных текстов‚ является одним из наших долгосрочных проектов․ Сравнение моделей суммирования: экстрактивная и абстрактная‚ также часто проводится нами для мультиязычных текстов․
Качество Текста и Анализ Стиля
Проверка грамматики‚ орфографии (используя Jellyfish для сравнения строк)‚ а также обнаружение плагиата – это задачи‚ которые важны для поддержания высокого качества текстового контента․ Мы разрабатываем инструменты для проверки фактов (Fact-Checking) и анализа стилистики текстов (авторский почерк)‚ что позволяет нам идентифицировать авторов и проверять подлинность документов․
Визуализация и Большие Данные
Для лучшего понимания текстовых данных мы используем инструменты для визуализации‚ такие как Word Clouds и Heatmaps․ Библиотека Sweetviz также помогает нам в анализе текстовых данных‚ предоставляя быстрые и информативные отчеты․
И‚ конечно‚ обработка больших текстовых массивов (Big Data NLP) – это то‚ с чем мы сталкиваемся постоянно․ Оптимизация производительности‚ использование GPU-ускорения для обработки текста и эффективное управление памятью становятся критически важными․
Мы прошли огромный путь‚ начиная с простых токенизаторов и заканчивая сложными трансформерными архитектурами․ Каждый этап этого путешествия был наполнен обучением‚ экспериментами и‚ конечно же‚ практическими применениями․ Мы увидели‚ как Python и его богатая экосистема библиотек (NLTK‚ spaCy‚ Gensim‚ Scikit-learn‚ Hugging Face и многие другие) предоставляют нам мощнейшие инструменты для работы с естественным языком․
Будь то анализ тональности отзывов о продуктах‚ извлечение информации из юридических контрактов или разработка умных чат-ботов‚ возможности NLP поистине безграничны․ Мы продолжаем исследовать новые горизонты‚ такие как Graph Embeddings для анализа взаимосвязей в тексте‚ Sentence Transformers для векторизации предложений и документов‚ и конечно же‚ постоянно совершенствуем наши навыки в тонкой настройке передовых моделей;
Надеемся‚ что наш опыт вдохновит вас на собственные исследования и открытия в мире обработки естественного языка․ Помните‚ что ключ к успеху в NLP – это постоянное обучение‚ эксперименты и глубокое понимание как лингвистических особенностей‚ так и технических аспектов․ Впереди нас ждут ещё более захватывающие задачи и революционные технологии‚ и мы с нетерпением ждём возможности поделиться ими с вами!
На этом статья заканчивается․
Подробнее
| NLP Python основы | Токенизация NLTK | Лемматизация SpaCy | Word2Vec Gensim | NER Hugging Face |
| Анализ тональности VADER | Тематическое моделирование LDA | Классификация текста Scikit-learn | Трансформеры BERT GPT | Разработка чат-ботов Python |





