
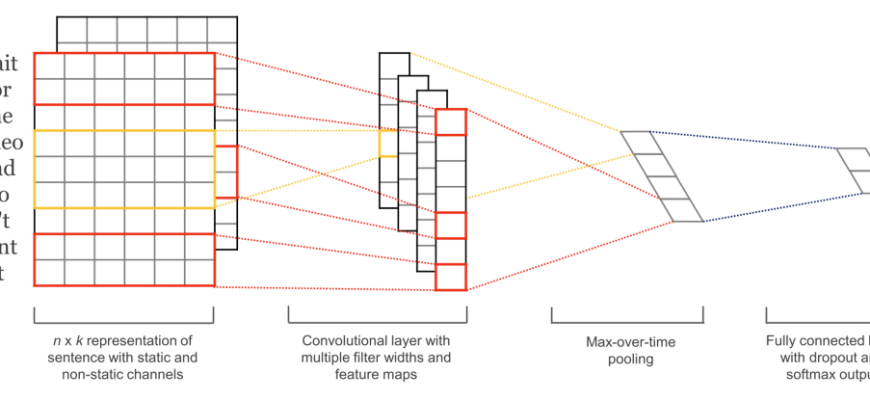
- От Слова к Смыслу: Наш Практический Путеводитель по Магии NLP в Python
- Первые Шаги: Строим Фундамент NLP с NLTK и Регулярными Выражениями
- spaCy: Скорость и Глубина Анализа
- Представление Текста: От Мешка Слов до Векторов Смысла
- Классические Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: Word2Vec, GloVe и FastText
- Основные Задачи NLP: Классификация, Тональность, Темы
- Классификация Текстов с Scikit-learn
- Анализ Тональности: От VADER до Трансформеров
- Тематическое Моделирование с Gensim: LDA и LSI
- Продвинутый NLP: Эпоха Трансформеров и Глубокого Обучения
- Hugging Face и Трансформеры: Новый Уровень Понимания
- Суммаризация Текста: От Извлечения до Абстракции
- Создание Чат-ботов и QA Систем
- Работа с Разнообразными Текстовыми Данными и Языками
- Веб-скрейпинг, PDF и Многоязычность
- Специфические Задачи и Инструменты
- Визуализация и Оценка: Делаем Результаты Понятными
От Слова к Смыслу: Наш Практический Путеводитель по Магии NLP в Python
Приветствуем вас, дорогие читатели и коллеги-энтузиасты! Сегодня мы хотим погрузиться в одну из самых увлекательных и быстро развивающихся областей современного программирования – обработку естественного языка, или NLP (Natural Language Processing). Наш путь в этом мире начался давно, и мы с радостью делимся накопленным опытом, который, надеемся, станет для вас вдохновением и полезным руководством. Мы убеждены, что за пониманием и генерацией человеческого языка компьютерами стоит будущее многих индустрий, от клиентского сервиса до научных исследований.
В этой статье мы не будем просто перечислять инструменты. Мы расскажем о том, как мы применяем их на практике, какие вызовы встают перед нами и как Python становится нашим незаменимым помощником. Мы поговорим о фундаментальных понятиях, продвинутых техниках и самых современных моделях, которые позволяют машинам не просто читать текст, но и по-нанастоящему его понимать, извлекать смысл и даже творить. Приготовьтесь к увлекательному путешествию, где каждая строка кода открывает новые горизонты для анализа и взаимодействия с текстовыми данными.
Первые Шаги: Строим Фундамент NLP с NLTK и Регулярными Выражениями
Любое большое путешествие начинается с первых шагов, и в мире NLP эти шаги – предобработка текста. Мы всегда начинаем с очистки и структурирования сырых данных, ведь "мусор на входе – мусор на выходе" – это не просто поговорка, а золотое правило в анализе текста. Нам приходится сталкиваться с самыми разнообразными форматами: от простых текстовых файлов до сложных веб-страниц и PDF-документов. И тут на помощь приходят наши верные спутники: библиотека NLTK и регулярные выражения.
NLTK (Natural Language Toolkit) – это наша рабочая лошадка для базовых операций. Мы используем её для токенизации – процесса разделения текста на отдельные слова или предложения. Это кажется простым, но корректное разделение текста на значимые единицы – это уже половина успеха. Затем мы переходим к стеммингу и лемматизации. Стемминг, например, с использованием алгоритма Портера, обрезает окончания слов до их "корня" (например, "бегущий", "бежал", "бегать" становятся "бег"). Лемматизация (которую мы предпочитаем, когда нужна большая точность, часто с помощью spaCy или Stanza) идет дальше, приводя слово к его словарной форме (лемме), что гораздо точнее и сохраняет смысл. Например, "был", "есть", "будет" приведутся к "быть".
| Операция | Описание | Пример |
|---|---|---|
| Токенизация | Разделение текста на слова или предложения. | "Привет, мир!" -> ["Привет", ",", "мир", "!"] |
| Стемминг | Удаление окончаний для получения "корня" слова. | "бегущий" -> "бег" |
| Лемматизация | Приведение слова к его словарной форме (лемме). | "лучший" -> "хороший" |
Наряду с NLTK, мы активно используем регулярные выражения (библиотека re) для более тонкой очистки текста. Это позволяет нам удалять HTML-теги, пунктуацию, числа, ссылки, эмодзи или любые другие паттерны, которые могут мешать анализу. Например, мы часто сталкиваемся с необходимостью извлечения конкретных дат или имен из неструктурированного текста, и здесь регулярные выражения становятся нашим надежным инструментом. Без этой тщательной предобработки последующие этапы анализа были бы менее точными и эффективными.
spaCy: Скорость и Глубина Анализа
Когда речь заходит о скорости и продвинутом лингвистическом анализе, мы неизменно обращаемся к spaCy. Эта библиотека – настоящий швейцарский нож для NLP, предлагающая не только быстрые токенизацию и лемматизацию, но и мощные возможности для распознавания именованных сущностей (NER). Мы используем spaCy для автоматического обнаружения и классификации таких сущностей, как имена людей, названия организаций, географические объекты, даты и денежные суммы в тексте. Это критически важно для извлечения структурированной информации из неструктурированных данных.
Наш опыт показывает, что spaCy значительно превосходит NLTK по производительности на больших объемах данных, особенно когда мы работаем с современными предварительно обученными моделями. Мы также ценим её за возможность выполнять синтаксический парсинг, что позволяет нам строить деревья зависимостей и понимать грамматическую структуру предложений. Это открывает двери для более глубокого анализа, например, для извлечения отношений между сущностями или для создания систем вопросно-ответных систем (QA), где контекст и связи между словами играют ключевую роль.
Представление Текста: От Мешка Слов до Векторов Смысла
Как же машина "понимает" текст? Она не может работать напрямую со словами, ей нужны числа. Поэтому следующий важнейший этап в нашем NLP-путешествии – это векторизация текста, то есть преобразование слов и документов в числовые векторы. На этом пути мы используем целый арсенал методов, каждый из которых подходит для своих задач.
Классические Векторизаторы: CountVectorizer и TF-IDF
Мы начинаем с базовых, но очень эффективных подходов, таких как CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn. CountVectorizer просто подсчитывает частоту вхождения каждого слова в документе, создавая вектор, где каждое измерение соответствует слову из всего корпуса. Это концепция "мешка слов" (Bag of Words), которая игнорирует порядок слов, но хорошо работает для многих задач классификации.
Однако частота слова сама по себе не всегда отражает его важность. Именно здесь на сцену выходит TF-IDF (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает, как часто слово встречается в конкретном документе (TF), но и насколько оно редко встречается во всем корпусе документов (IDF). Таким образом, слова, которые часто встречаются только в одном документе, но редко в других (например, уникальные термины), получают высокий вес, в то время как общие слова ("и", "в", "на"), которые встречаются повсюду, получают низкий вес. Мы находим TF-IDF особенно полезным для извлечения ключевых фраз и для задач классификации, где нужно выделить наиболее информативные слова.
Word Embeddings: Word2Vec, GloVe и FastText
Хотя TF-IDF и эффективен, он не учитывает семантическую связь между словами. "Король" и "королева" могут иметь совершенно разные векторы, хотя они семантически близки. Здесь мы переходим к более продвинутым методам – Word Embeddings, которые позволяют представлять слова в виде плотных векторов в многомерном пространстве, где семантически близкие слова находятся рядом. Мы активно используем библиотеку Gensim для работы с такими моделями.
- Word2Vec (Skip-gram и CBOW): Это одна из первых моделей, которая по-настоящему революционизировала представление слов. Мы обучаем Word2Vec на больших текстовых корпусах, и в результате получаем векторы, которые улавливают отношения между словами. Например, "король ⏤ мужчина + женщина = королева".
- GloVe (Global Vectors for Word Representation): GloVe представляет собой гибридный подход, сочетающий в себе идеи Word2Vec и методы матричной факторизации. Он строит векторы, основываясь на глобальной статистике со-встречаемости слов. Мы часто используем предварительно обученные модели GloVe для различных задач, когда у нас нет достаточного объема данных для обучения собственных векторов.
- FastText: Разработанный Facebook AI, FastText расширяет Word2Vec, представляя слова как "мешки символьных N-грамм". Это позволяет ему работать с редкими словами и даже словами, которых не было в обучающем корпусе (out-of-vocabulary words), путем агрегирования векторов его подслов. Мы находим FastText особенно полезным для языков с богатой морфологией и в задачах, где встречаются опечатки или сленг.
Для представления целых документов или предложений мы используем Doc2Vec (расширение Word2Vec) или, в более современных подходах, Sentence Transformers. Эти методы позволяют нам получать векторы для более крупных текстовых единиц, что особенно полезно для поиска похожих документов или суммаризации.
Основные Задачи NLP: Классификация, Тональность, Темы
С хорошо предобработанными и векторизованными данными мы можем переходить к решению реальных задач NLP. Здесь мы используем различные подходы, от классического машинного обучения до глубоких нейронных сетей.
Классификация Текстов с Scikit-learn
Классификация текстов – это одна из самых распространенных задач NLP. Мы используем её для автоматической категоризации статей, фильтрации спама, маршрутизации запросов клиентов или определения жанра документа. Для этих целей Scikit-learn является нашим основным инструментом. Мы применяем такие алгоритмы, как:
- Наивный Байесовский классификатор: Прост в реализации, но удивительно эффективен для многих текстовых задач, особенно когда данных не так много.
- Метод опорных векторов (SVM): Отлично работает с высокоразмерными данными, такими как TF-IDF векторы, и часто дает очень хорошие результаты.
- Логистическая регрессия: Надежный и интерпретируемый алгоритм, который также хорошо зарекомендовал себя в текстовой классификации.
Мы всегда тщательно выбираем модель, исходя из объема и характера данных, а также требований к интерпретируемости и производительности. Оценка качества моделей (F1-score, Precision, Recall) является неотъемлемой частью нашего рабочего процесса.
Анализ Тональности: От VADER до Трансформеров
Понимание эмоциональной окраски текста – это бесценный инструмент для анализа отзывов клиентов, мониторинга социальных сетей или отслеживания общественного мнения. Мы часто начинаем с простых, но эффективных решений, таких как VADER (Valence Aware Dictionary and sEntiment Reasoner). VADER – это лексический и основанный на правилах анализатор тональности, который специально обучен для работы с текстами из социальных сетей и хорошо справляется с сарказмом и сленгом. Мы находим его очень полезным для быстрой оценки тональности без необходимости обучать сложную модель.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
– Рита Мэй Браун
Для более сложных задач, требующих глубокого понимания контекста и нюансов языка, мы переходим к моделям на основе машинного обучения. Например, мы обучаем классификаторы на размеченных данных отзывов, используя те же методы, что и для классификации текстов. А в самых продвинутых случаях, особенно когда нужно учесть сарказм, иронию или специфический домен, мы обращаемся к трансформерным моделям, о которых расскажем чуть позже.
Тематическое Моделирование с Gensim: LDA и LSI
Когда у нас есть большой корпус документов, и мы хотим понять, о каких темах в них идет речь, мы используем тематическое моделирование. Библиотека Gensim является нашим главным инструментом для этого. Мы чаще всего применяем два основных алгоритма:
- LDA (Latent Dirichlet Allocation): LDA – это вероятностная модель, которая предполагает, что каждый документ представляет собой смесь нескольких тем, а каждая тема – это смесь слов. Мы используем LDA для выявления скрытых тем в коллекциях документов, таких как статьи новостей, научные публикации или отзывы клиентов. Это помогает нам структурировать информацию и получать инсайты из неструктурированных данных.
- LSI (Latent Semantic Indexing): LSI использует сингулярное разложение (SVD) для выявления скрытых семантических структур в текстовых данных. Оно уменьшает размерность пространства слов, выявляя основные "факторы" или темы, которые связывают слова и документы.
Сравнение моделей тематического моделирования, таких как LDA и NMF (Non-negative Matrix Factorization), всегда является частью нашего процесса. Мы выбираем ту, которая лучше всего раскрывает структуру данных и дает более интерпретируемые темы для конкретной задачи.
Продвинутый NLP: Эпоха Трансформеров и Глубокого Обучения
Последние годы ознаменовались настоящей революцией в NLP благодаря появлению трансформерных архитектур. Эти модели значительно превосходят традиционные подходы во многих задачах, позволяя нам решать проблемы, которые раньше казались неразрешимыми.
Hugging Face и Трансформеры: Новый Уровень Понимания
Когда мы говорим о трансформерах, мы в первую очередь думаем о библиотеке Hugging Face Transformers. Это наша основная платформа для работы с такими моделями, как BERT, GPT, RoBERTa, T5 и многими другими. Эти модели, предварительно обученные на огромных текстовых корпусах, обладают невероятной способностью понимать контекст, генерировать связный текст и выполнять широкий спектр задач NLP.
Мы используем трансформеры для:
- Сложного NER: Для распознавания сущностей в текстах с высокой контекстной зависимостью, например, в медицинских записях или юридических документах.
- Анализа тональности с учетом нюансов: Модели, такие как RoBERTa, обученные на больших данных, способны улавливать сарказм и тонкие оттенки настроения.
- Классификации текстов: BERT и его производные показывают выдающиеся результаты в задачах категоризации, особенно когда данные для обучения ограничены (мы используем тонкую настройку, или Fine-tuning, предварительно обученных моделей).
- Генерации текста: Модели GPT позволяют нам создавать связные и осмысленные тексты, будь то ответы для чат-ботов, суммаризация или даже написание художественных произведений.
- Вопросно-ответных систем (QA): Мы строим системы, которые могут отвечать на вопросы по тексту, находя наиболее релевантные отрывки или генерируя ответы.
- Машинного перевода: Трансформеры являются основой современных систем машинного перевода, обеспечивая высокое качество.
Работа с PyTorch/TensorFlow позволяет нам не только использовать готовые модели, но и создавать собственные нейросетевые архитектуры, включая LSTM-сети для последовательной обработки текста, когда трансформеры могут быть избыточными или требовать слишком много ресурсов.
Суммаризация Текста: От Извлечения до Абстракции
В мире информационного перегруза способность быстро извлекать суть из длинных текстов становится критически важной. Мы разрабатываем системы суммаризации текста, которые делятся на два основных типа:
- Экстрактивная суммаризация: Мы используем такие методы, как TextRank, для извлечения наиболее важных предложений из оригинального текста и объединения их в краткий обзор. Это эффективно, когда нужно сохранить оригинальные формулировки.
- Абстрактивная суммаризация: Здесь в игру вступают трансформерные модели (например, BART, T5). Они не просто выбирают предложения, а генерируют новый, более короткий текст, который передает основную идею, используя новые формулировки. Это более сложная задача, но результаты часто более естественны и читабельны.
Создание Чат-ботов и QA Систем
Мы активно применяем наши знания в NLP для создания интерактивных систем. Разработка чат-ботов на Python, часто с использованием фреймворка Rasa, позволяет нам автоматизировать общение с пользователями, отвечать на их вопросы и выполнять задачи. Для более сложных сценариев мы интегрируем трансформерные модели, чтобы боты могли понимать намерения пользователя и генерировать более релевантные ответы.
Системы вопросно-ответных систем (QA) – это еще одна область, где NLP показывает свою мощь. Мы создаем такие системы, которые могут "читать" большой объем документов (например, базу знаний) и находить точные ответы на заданные вопросы. Это особенно актуально для корпоративных решений, где нужно быстро получать информацию из внутренних документов.
Работа с Разнообразными Текстовыми Данными и Языками
Наш опыт показывает, что реальный мир редко предоставляет идеально чистые и однородные данные. Мы постоянно сталкиваемся с необходимостью обрабатывать тексты из самых разных источников и на разных языках.
Веб-скрейпинг, PDF и Многоязычность
Для извлечения текстовых данных из веба мы полагаемся на библиотеку Beautiful Soup. Она позволяет нам парсить HTML-страницы и извлекать нужный контент, который затем подвергается предобработке. Когда текст заперт в PDF-файлах, мы используем PyMuPDF для его эффективного извлечения.
Обработка многоязычных текстовых корпусов – это отдельная, но очень важная задача. Мы применяем такие библиотеки, как Polyglot и Stanza. Polyglot отлично подходит для определения языка, токенизации и распознавания сущностей для множества языков. Stanza (от Stanford NLP Group) предлагает глубокий лингвистический анализ, включая POS-теггинг и синтаксический парсинг, для языков с богатой морфологией, таких как русский.
Специфические Задачи и Инструменты
Мы также занимаемся более специализированными задачами, которые требуют особого подхода:
- Анализ стилистики текстов (авторский почерк): Мы разрабатываем инструменты для определения авторства текста, анализа лексического богатства и использования специфических паттернов.
- Работа с эмодзи и сленгом: Современные тексты, особенно в социальных сетях, полны эмодзи и сленга. Мы разрабатываем методы для их нормализации и включения в анализ тональности.
- Анализ юридических документов и лог-файлов: Эти тексты часто имеют специфическую структуру и терминологию, требующую тонкой настройки моделей и специализированной предобработки.
- Обнаружение плагиата: Мы используем различные методы сравнения строк (например, с библиотекой Jellyfish) и векторизации документов (Doc2Vec, Sentence Transformers) для выявления сходства между текстами.
- Разработка инструментов для проверки грамматики и орфографии: Для повышения качества генерируемого или обрабатываемого текста мы создаем или интегрируем модули проверки.
Визуализация и Оценка: Делаем Результаты Понятными
После того как мы провели весь этот сложный анализ, крайне важно представить результаты в понятной и наглядной форме. Инструменты для визуализации текстовых данных играют здесь ключевую роль.
Мы часто используем:
- Облака слов (Word Clouds): Для быстрого выявления наиболее часто встречающихся слов в корпусе.
- Тепловые карты (Heatmaps): Для визуализации матриц сходства между документами или темами.
- Графики распределения частотности слов и N-грамм: Чтобы показать, какие слова или последовательности слов наиболее характерны для текста.
- Визуализации эмбеддингов (t-SNE, UMAP): Чтобы увидеть, как слова или документы группируются в многомерном пространстве, что помогает понять семантические связи.
Оценка качества моделей NLP – это неотъемлемая часть нашего рабочего процесса. Мы используем метрики, такие как Precision, Recall, F1-score для задач классификации и NER, а также более специфичные метрики для суммаризации или машинного перевода. Без строгой оценки невозможно понять, насколько хорошо наша система справляется со своей задачей и что можно улучшить.
Мы прошли долгий путь от базовой токенизации до продвинутых трансформерных моделей, способных генерировать осмысленный текст и отвечать на сложные вопросы. Наш опыт показывает, что мир NLP в Python постоянно развивается, предлагая все новые и новые инструменты и подходы. Каждый день мы узнаем что-то новое, сталкиваемся с новыми вызовами и находим инновационные решения.
Python с его богатой экосистемой библиотек – NLTK, spaCy, Gensim, Scikit-learn, Hugging Face, PyTorch/TensorFlow – является поистине идеальной платформой для работы с естественным языком. Мы надеемся, что наш путеводитель вдохновил вас на собственные эксперименты и открытия в этой захватывающей области. Возможности NLP поистине безграничны, и мы с нетерпением ждем, какие удивительные проекты вы сможете реализовать, используя эти мощные инструменты. Точка.
Подробнее
| Основы NLTK | NER с spaCy | LDA и LSI Gensim | Классификация текстов Scikit-learn | Word Embeddings |
| Анализ тональности VADER | Трансформеры Hugging Face | Разработка чат-ботов на Python | Суммаризация текста | Обработка многоязычных корпусов |




