
- Раскрываем Тайны Текста: Наш Путь в Мире NLP с Python
- Начало Пути: Подготовка Текста к Анализу
- Токенизация, Стемминг и Лемматизация: Основы Очистки
- Представление Текста: Как Компьютер "Видит" Слова
- От Частоты Слов к Смысловым Векторам
- Извлечение Смысла: Ключевые Задачи NLP
- Распознавание Сущностей, Анализ Тональности и Тематическое Моделирование
- Классификация, Извлечение Ключевых Фраз и Суммаризация
- На Вершине Технологий: Трансформеры и Глубокое Обучение
- Мощь Трансформеров (Hugging Face) и Контекстные Встраивания
- Разработка Систем Вопросно-Ответных и Машинного Перевода
- Практическое Применение и Специализированные Задачи
- Работа с Неструктурированными Данными и Веб-Скрейпинг
- Мультиязычность, Анализ Стиля и Поведенческих Паттернов
- Инфраструктура и Инструменты: Наш Арсенал
- Библиотеки Python для NLP: Обзор и Сравнение
- Визуализация и Оценка Моделей
- Будущее NLP и Наши Перспективы
Раскрываем Тайны Текста: Наш Путь в Мире NLP с Python
Привет, дорогие читатели и коллеги-энтузиасты! Сегодня мы хотим пригласить вас в увлекательное путешествие по миру обработки естественного языка (NLP) с использованием одного из самых мощных и гибких инструментов — языка Python. Мы, как команда опытных исследователей и практиков, годами погружались в эти глубины, и теперь готовы поделиться нашим бесценным опытом, нашими открытиями и, конечно же, нашими любимыми инструментами. Приготовьтесь, ведь мы собираемся не просто рассказать о NLP, а показать вам, как мы сами применяем эти технологии, чтобы заставить машины понимать человеческий язык.
В современном мире, где объемы текстовых данных растут экспоненциально, способность автоматизировать их анализ становится не просто преимуществом, а необходимостью. От понимания отзывов клиентов до выявления скрытых тенденций в новостных лентах, от автоматизации ответов до создания интеллектуальных систем – NLP открывает перед нами безграничные возможности. Мы уверены, что каждый, кто работает с данными, найдет для себя что-то ценное в нашем обзоре, ведь мы постарались охватить максимально широкий спектр задач и решений, с которыми мы сталкивались на практике.
Начало Пути: Подготовка Текста к Анализу
Прежде чем мы сможем извлечь какую-либо полезную информацию из текста, его необходимо тщательно подготовить. Представьте, что вы хотите испечь пирог: сначала нужно просеять муку, помыть фрукты, подготовить все ингредиенты. Точно так же и с текстом. Этот этап, известный как предобработка, является фундаментом любого NLP-проекта, и от его качества во многом зависит успех дальнейшего анализа. Мы обнаружили, что пренебрежение этим шагом часто приводит к искаженным результатам и пустой трате времени.
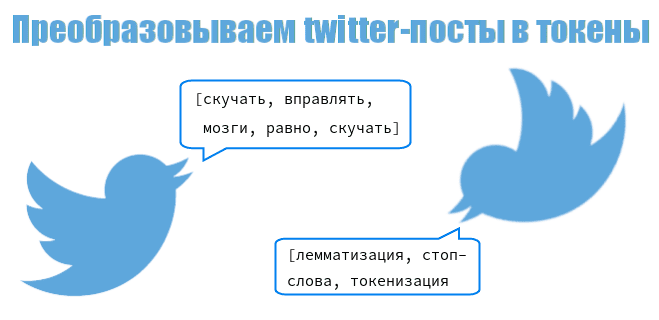
Наш опыт показывает, что существует несколько ключевых этапов предобработки, каждый из которых играет свою роль. Мы всегда начинаем с токенизации – процесса разбиения текста на более мелкие единицы, называемые токенами. Это могут быть слова, предложения или даже символы. Классическая библиотека NLTK предлагает простые и эффективные токенизаторы, такие как `word_tokenize` и `sent_tokenize`, которые мы часто используем для базовых задач. Однако, когда мы сталкиваемся с более сложными языками или специфическими задачами, мы обращаемся к более продвинутым инструментам.
Токенизация, Стемминг и Лемматизация: Основы Очистки
После токенизации следуют процессы нормализации, которые помогают привести слова к их базовой форме, уменьшая тем самым количество уникальных токенов и упрощая анализ. Стемминг – это процесс удаления аффиксов (суффиксов, префиксов) от слова, чтобы получить его корень или основу. Например, слова "бежать", "бежит", "бежал" будут сведены к основе "беж". Мы часто используем стеммеры из NLTK, такие как PorterStemmer или SnowballStemmer, которые хорошо зарекомендовали себя для английского и некоторых других языков.
Однако стемминг имеет свои ограничения: он может создавать несуществующие слова (например, "красив" из "красивый"). Для более точной нормализации мы применяем лемматизацию. Лемматизация – это процесс приведения слова к его словарной (канонической) форме, или лемме, с учетом части речи и контекста. Так, "бежать", "бежит", "бежал" будут приведены к лемме "бежать". SpaCy является нашим фаворитом для продвинутой лемматизации, особенно когда речь идет о языках с богатой морфологией, таких как русский, благодаря его мощным лингвистическим моделям. Мы также экспериментировали со Stanza, особенно для языков, где spaCy может быть менее эффективным.
Помимо стемминга и лемматизации, мы обязательно удаляем стоп-слова – часто встречающиеся слова, которые не несут существенной смысловой нагрузки (например, "и", "в", "на", "он"). NLTK предоставляет списки стоп-слов для многих языков, но мы часто создаем и свои кастомные списки, адаптированные под конкретную предметную область. Еще одним важным шагом является использование регулярных выражений (модуль `re` в Python) для очистки текста от HTML-тегов, пунктуации, чисел, специальных символов и всего, что может мешать анализу. Это позволяет нам получить максимально "чистый" текстовый корпус.
Представление Текста: Как Компьютер "Видит" Слова
После тщательной предобработки текст готов к тому, чтобы быть преобразованным в формат, понятный для машины. Компьютеры не могут напрямую работать со словами; им нужны числа. Этот процесс называется векторизацией текста, и мы исследовали множество подходов к нему, каждый из которых имеет свои преимущества и недостатки в зависимости от задачи. Наш опыт показывает, что правильный выбор метода векторизации часто является ключом к высокой производительности модели.
От Частоты Слов к Смысловым Векторам
Самые простые, но все еще эффективные методы векторизации основаны на частотности слов. `CountVectorizer` из Scikit-learn позволяет нам создать вектор, где каждое измерение соответствует слову из нашего словаря, а значение – количеству его вхождений в документ. Это отличный старт, но он не учитывает важность слова. Здесь на помощь приходит `TfidfVectorizer` (Term Frequency-Inverse Document Frequency), который взвешивает частоту слова в документе обратно пропорционально частоте его появления во всем корпусе. Таким образом, редкие, но важные слова получают больший вес. Мы активно используем эти векторизаторы для задач классификации и кластеризации текстов.
Однако, эти методы не улавливают семантические отношения между словами. Например, "король" и "королева" будут рассматриваться как совершенно независимые сущности. Для решения этой проблемы мы обратились к так называемым Word Embeddings (векторным представлениям слов). `Word2Vec` и `GloVe`, которые мы реализуем с помощью библиотеки Gensim, позволяют нам представлять слова как плотные векторы в многомерном пространстве, где слова со схожим значением располагаются ближе друг к другу; Это открывает двери для гораздо более глубокого понимания текста.
Мы также используем `FastText` из Gensim, который является расширением `Word2Vec`, способным работать с редкими словами и даже словами, не встречавшимися в обучающем корпусе, за счет анализа их субсловных единиц (n-грам символов). Когда же нам нужно получить векторное представление не отдельного слова, а целого предложения или документа, мы обращаемся к `Doc2Vec` (также из Gensim) или к более современным `Sentence Transformers`. Последние особенно ценны, когда мы хотим сравнить сходство между документами или предложениями, поскольку они генерируют высококачественные, контекстуальные эмбеддинги.
Извлечение Смысла: Ключевые Задачи NLP
Когда текст подготовлен и векторизован, мы переходим к самому интересному – извлечению из него полезной информации и решению конкретных задач; Наш путь в NLP привел нас к освоению широкого спектра техник, каждая из которых решает свою уникальную проблему. Мы обнаружили, что понимание целей и ограничений каждой техники критически важно для выбора правильного инструмента.
Распознавание Сущностей, Анализ Тональности и Тематическое Моделирование
Одной из наиболее востребованных задач является Распознавание Именованных Сущностей (NER). Это процесс идентификации и классификации именованных сущностей в тексте, таких как имена людей, организации, местоположения, даты и т.д. SpaCy предоставляет нам быстрые и точные NER-модели, которые мы активно используем в наших проектах. Для более сложных сценариев, особенно для языков с богатой морфологией или специфических предметных областей, мы обращаемся к библиотеке Flair, которая предлагает современные NER-модели на основе рекуррентных нейронных сетей и трансформеров, а также к условным случайным полям (CRF).
Анализ тональности (Sentiment Analysis) – еще одна область, где мы активно применяем NLP. Это позволяет нам определить эмоциональную окраску текста – позитивную, негативную или нейтральную. Для простых и быстрых решений мы часто используем `VADER` (Valence Aware Dictionary and sEntiment Reasoner) из NLTK, который хорошо работает с англоязычными текстами, а также `TextBlob` для более легкого анализа. Однако, для более глубокого и точного анализа, особенно с учетом сарказма или контекста в социальных сетях, мы разрабатываем собственные модели на основе машинного обучения (например, с использованием `Scikit-learn` или `PyTorch`/`TensorFlow`) и трансформеров.
«Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут.»
, Рита Мэй Браун
Тематическое моделирование – это мощный инструмент для обнаружения скрытых тем в больших коллекциях документов. С помощью библиотеки Gensim мы активно используем модели LDA (Латентное размещение Дирихле) и LSI (Латентное семантическое индексирование). Эти методы позволяют нам понять, о чем идет речь в огромных массивах текста, выявить основные идеи и классифицировать документы по их содержанию. Мы также сравниваем их с NMF (Неотрицательная матричная факторизация), чтобы выбрать наиболее подходящую модель для конкретной задачи, будь то анализ отзывов клиентов или новостных статей.
Классификация, Извлечение Ключевых Фраз и Суммаризация
Классификация текстов является одной из фундаментальных задач NLP, которую мы решаем постоянно. От категоризации статей и сообщений до фильтрации спама – возможности безграничны. Мы применяем `Scikit-learn` с его обширным набором алгоритмов машинного обучения, таких как SVM, Наивный Байесовский классификатор, логистическая регрессия. Для более сложных задач, где требуется учитывать контекст и семантику, мы переходим к нейронным сетям, построенным на `PyTorch` или `TensorFlow`, используя LSTM-сети или трансформеры.
Извлечение ключевых фраз – это процесс автоматического определения наиболее важных слов или фраз в тексте. Для этой цели мы используем алгоритмы, такие как RAKE (Rapid Automatic Keyword Extraction) и TextRank. Эти методы помогают нам быстро понять суть документа, особенно когда нам нужно проанализировать большое количество текстов и получить их краткое описание. Например, мы применяем это для анализа метаданных текста или для автоматического тегирования контента.
Суммаризация текста – это задача создания краткого, но информативного изложения более длинного документа. Мы различаем два основных подхода: экстрактивную и абстрактивную суммаризацию. Экстрактивная суммаризация (например, с использованием TextRank для извлечения ключевых предложений) выбирает наиболее важные предложения из исходного текста. Абстрактивная суммаризация, с другой стороны, генерирует новые предложения, которые могут не присутствовать в оригинале, но передают его смысл. Для абстрактивной суммаризации мы используем продвинутые трансформерные модели из Hugging Face, такие как BART или T5, которые показывают впечатляющие результаты.
На Вершине Технологий: Трансформеры и Глубокое Обучение
Последние годы ознаменовались революцией в области NLP благодаря появлению архитектур-трансформеров. Это изменило наш подход ко многим задачам, позволив достигать беспрецедентной точности и эффективности. Мы, как блогеры, стремящиеся быть на острие прогресса, не могли обойти стороной эту тему.
Мощь Трансформеров (Hugging Face) и Контекстные Встраивания
Библиотека Hugging Face Transformers стала нашим незаменимым инструментом для работы с самыми современными моделями NLP. Мы используем ее для широкого круга задач: от классификации текстов (применяя BERT для задач классификации) и NER до машинного перевода и генерации текста (например, с GPT-моделями для генерации диалогов или кода). Возможность тонкой настройки (Fine-tuning) предварительно обученных моделей на наших собственных данных позволяет нам достигать впечатляющих результатов даже с ограниченным объемом специфических данных.
Ключевой особенностью трансформеров являются контекстные встраивания. В отличие от традиционных Word2Vec или GloVe, где каждое слово имеет одно фиксированное векторное представление, трансформеры генерируют вектор слова, учитывая его контекст в предложении. Это означает, что слово "банк" будет иметь разное векторное представление в предложениях "я иду в банк" (финансовое учреждение) и "я сижу на берегу реки" (песчаная отмель). Это значительно улучшает понимание нюансов языка и позволяет нам разрабатывать более интеллектуальные системы.
Разработка Систем Вопросно-Ответных и Машинного Перевода
С помощью трансформеров мы активно работаем над разработкой систем вопросно-ответных систем (QA). Эти системы способны находить ответы на вопросы в заданном тексте или корпусе документов. Модели, такие как BERT и его модификации, обученные на больших QA-датасетах, позволяют нам создавать чат-ботов и интеллектуальных помощников, которые могут эффективно извлекать информацию. Это особенно полезно для автоматизации поддержки клиентов или создания внутренних корпоративных баз знаний.
Машинный перевод – еще одна область, где трансформеры произвели революцию. От простой замены слов мы перешли к генерации связного и грамматически корректного текста на целевом языке, учитывая контекст всего предложения. Мы используем предварительно обученные модели для машинного перевода, а также проводим тонкую настройку для создания систем автоматического перевода узкоспециализированных текстов или даже сленга, что являеться особенно сложной задачей.
Практическое Применение и Специализированные Задачи
Теория и инструменты – это прекрасно, но истинная ценность NLP раскрывается в его практическом применении. На протяжении многих лет мы сталкивались с самыми разнообразными задачами, требующими нестандартных подходов и глубокого понимания предметной области. Здесь мы поделимся некоторыми из наиболее интересных направлений, в которых мы работаем;
Работа с Неструктурированными Данными и Веб-Скрейпинг
Большая часть полезной текстовой информации в интернете находится в неструктурированном виде. Чтобы получить к ней доступ, мы активно используем библиотеку Beautiful Soup для веб-скрейпинга текста. Это позволяет нам извлекать данные с веб-страниц, очищать их от HTML-тегов и подготавливать для дальнейшего анализа. Мы также работаем с PyMuPDF для извлечения текста из PDF-документов, что является критически важным для анализа юридических, медицинских или финансовых документов.
Обработка неструктурированного текста часто начинается с его очистки. Помимо удаления HTML-тегов и пунктуации, мы также занимаемся нормализацией сленга, работой с эмодзи и сленгом в современных текстах, что особенно актуально для анализа социальных сетей. Мы разрабатываем собственные инструменты для проверки грамматики и орфографии, а также для нормализации пунктуации, чтобы обеспечить высокое качество входных данных.
Мультиязычность, Анализ Стиля и Поведенческих Паттернов
Мир не ограничивается одним языком, и наши проекты часто требуют работы с многоязычными текстовыми корпусами. Библиотеки Polyglot и Stanza стали нашими надежными помощниками в этой области, предоставляя инструменты для токенизации, POS-теггинга, NER и лемматизации для множества языков, включая те, что имеют богатую морфологию. Мы также разрабатываем системы для автоматического перевода узкоспециализированных текстов, что требует глубокого понимания лингвистических особенностей каждого языка.
Анализ стилистики текстов (авторский почерк) – это увлекательная задача, которая позволяет нам определять авторство текста, выявлять плагиат или просто понимать уникальные характеристики письма. Мы используем различные метрики лексического богатства, частотности слов и n-грамм, а также продвинутые методы векторизации для создания "отпечатков" авторского стиля. Сравнение строк с помощью библиотеки Jellyfish также помогает нам в поиске дубликатов и плагиата.
В мире социальных медиа и чатов мы активно анализируем поведенческие паттерны в чатах, отзывах и пользовательских запросах. Это позволяет нам выявлять скрытые темы, анализировать тональность сообщений в социальных сетях (Twitter/Reddit) с учетом сарказма, а также определять сезонность в текстовых данных. Мы используем `Sweetviz` для анализа текстовых данных, чтобы получить быстрый обзор и выявить аномалии.
Инфраструктура и Инструменты: Наш Арсенал
Для эффективной работы в области NLP недостаточно знать только алгоритмы; необходимо также уметь выбирать и использовать правильные инструменты. Наш арсенал постоянно пополняется, и мы всегда ищем наиболее оптимальные решения для наших задач.
Библиотеки Python для NLP: Обзор и Сравнение
Мы работаем с широким спектром библиотек, каждая из которых имеет свою специализацию:
- NLTK (Natural Language Toolkit): Основа для многих базовых задач – токенизация, стемминг, POS-теггинг, работа со стоп-словами. Мы часто используем его для быстрого прототипирования и обучения.
- spaCy: Наш выбор для высокопроизводительного и точного анализа. Он предлагает отличные предобученные модели для NER, синтаксического парсинга, лемматизации для многих языков, включая русский. Мы ценим его за скорость и простоту использования в продакшене.
- Gensim: Незаменим для тематического моделирования (LDA, LSI) и работы с Word Embeddings (Word2Vec, GloVe, Doc2Vec, FastText). Мы используем его для анализа больших текстовых массивов.
- Scikit-learn: Наш основной инструмент для классификации и кластеризации текстов. Предоставляет широкий выбор алгоритмов машинного обучения и векторизаторов (CountVectorizer, TfidfVectorizer).
- Hugging Face Transformers: Абсолютный лидер для работы с трансформерными моделями (BERT, GPT и др.), тонкой настройки и решения сложных задач, таких как QA и машинный перевод.
- TextBlob: Для простого и быстрого NLP, анализа тональности и определения языка. Мы используем его, когда не требуется высокая точность или глубокий анализ.
- Flair: Отличная библиотека для современного NER, особенно для языков с богатой морфологией.
- Stanza: Альтернатива spaCy для многоязычного и морфологического анализа, особенно полезна для языков, где другие библиотеки могут быть менее развиты.
- Textacy: Предлагает продвинутые функции для обработки текста, извлечения информации и анализа зависимостей.
- Beautiful Soup: Для веб-скрейпинга и извлечения текста из HTML.
- PyTorch/TensorFlow: Наши фреймворки для создания глубоких нейронных сетей для NLP, включая LSTM-сети и кастомные трансформерные архитектуры.
Мы часто сравниваем эффективность различных токенизаторов, методов лемматизации (SpaCy vs NLTK), моделей тематического моделирования (LDA vs NMF), а также методов векторизации (TF-IDF vs Word2Vec), чтобы выбрать наиболее подходящее решение для каждой конкретной задачи. Наш опыт показывает, что универсального решения не существует, и выбор инструмента всегда зависит от специфики данных и требований к производительности.
Визуализация и Оценка Моделей
Понимание результатов анализа так же важно, как и сам анализ. Для визуализации текстовых данных мы используем различные инструменты, такие как Word Clouds для быстрого отображения частотности слов или Heatmaps для визуализации матриц сходства. Это помогает нам быстро интерпретировать данные и находить закономерности.
Оценка качества NER-моделей, классификаторов и других систем NLP является неотъемлемой частью нашего рабочего процесса. Мы используем стандартные метрики, такие как F1-score, Precision и Recall, для измерения производительности наших моделей. Помимо этого, мы разрабатываем инструменты для автоматической разметки данных и создания словарей/тезаурусов, что значительно упрощает процесс обучения и улучшения моделей.
| Библиотека | Основные функции | Преимущества | Типичные задачи |
|---|---|---|---|
| NLTK | Токенизация, стемминг, POS-теггинг, стоп-слова | Широкий набор алгоритмов, образовательный ресурс, поддержка многих языков | Базовая предобработка, исследовательские проекты |
| spaCy | NER, синтаксический парсинг, лемматизация, токенизация | Высокая производительность, готовые модели, удобство для продакшена | Быстрый NER, анализ зависимостей, продуктовые решения |
| Gensim | Word Embeddings (Word2Vec, Doc2Vec), тематическое моделирование (LDA, LSI) | Эффективная работа с большими корпусами, фокус на семантике | Анализ тем, поиск сходства документов, работа с редкими словами |
| Scikit-learn | Классификация, кластеризация, векторизация текста (TF-IDF, CountVectorizer) | Множество алгоритмов ML, отличная документация, интеграция с другими библиотеками | Категоризация статей, анализ тональности, спам-фильтры |
| Hugging Face Transformers | Трансформерные модели (BERT, GPT), тонкая настройка, QA, генерация текста | Современные SOTA-модели, обширное сообщество, легкость использования | Продвинутый NER, машинный перевод, суммаризация, разработка чат-ботов |
Будущее NLP и Наши Перспективы
Мир NLP развивается с ошеломляющей скоростью, и мы постоянно адаптируемся к новым вызовам и возможностям. От разработки систем обнаружения плагиата до анализа юридических документов, от создания FAQ на основе документов до анализа финансовых новостей – спектр задач, которые мы можем решать, постоянно расширяется; Мы активно исследуем обработку текста в режиме реального времени (Streaming NLP) и использование GPU-ускорения для обработки больших текстовых массивов.
Наш путь в NLP – это непрерывное обучение и эксперименты. Мы видим огромный потенциал в дальнейшем развитии трансформерных моделей для генерации диалогов, анализа кода, выявления связей между сущностями и даже для проверки фактов. Мы стремимся создавать не просто инструменты, а интеллектуальные системы, которые действительно понимают и взаимодействуют с человеческим языком на глубоком уровне.
Надеемся, что наш обзор был для вас полезным и вдохновил на собственные исследования в этой захватывающей области. Мы приглашаем вас присоединиться к нам в этом путешествии, делиться своим опытом и вместе раскрывать новые тайны текста. Ведь чем больше мы узнаем, тем ближе мы к созданию по-настоящему интеллектуальных систем, способных изменить мир. Точка.
Подробнее: LSI Запросы
| Основы NLTK | Применение BERT для NER | Анализ тональности с VADER | Тематическое моделирование Gensim | Векторизация текста Word2Vec |
| Машинный перевод Hugging Face | Обработка неструктурированного текста | Разработка чат-ботов Python | Синтаксический парсинг spaCy | Тонкая настройка Transformer-моделей |





