
- Раскрываем Тайны Текста: Путешествие в Мир NLP на Python, о котором вы мечтали!
- Основы, Без Которых Никуда: Токенизация, Стемминг и Лемматизация
- Регулярные Выражения: Ваш Швейцарский Нож для Предобработки
- Основные Инструменты Python для NLP: NLTK, spaCy и TextBlob
- NLTK: Университетская Основа
- spaCy: Скорость и Производительность в Продакшене
- TextBlob: Простота для Быстрых Задач
- Представление Текста: Как Компьютер "Видит" Слова
- Векторизаторы Старой Школы: CountVectorizer и TfidfVectorizer
- Эпоха Word Embeddings: Word2Vec, GloVe и FastText
- Doc2Vec и Sentence Transformers: От Слов к Предложениям и Документам
- Продвинутые Задачи NLP: Извлечение Смысла и Структуры
- Распознавание Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis)
- Тематическое Моделирование (Topic Modeling): LDA и NMF
- Классификация Текстов: Автоматическая Категоризация
- Суммаризация Текста: Извлекаем Суть
- Эпоха Трансформеров: Революция в NLP
- Hugging Face: Ваш Проводник в Мир Трансформеров
- Специализированные Приложения и Продвинутые Техники
- Работа с Разнообразными Источниками и Форматами
- Построение Интеллектуальных Систем
- Глубокий Анализ и Извлечение Информации
- Визуализация и Оценка
- Работа со Сложностями Реального Мира
Раскрываем Тайны Текста: Путешествие в Мир NLP на Python, о котором вы мечтали!
Привет, дорогие любители данных и языка! Мы, как опытные исследователи цифровых джунглей, постоянно ищем новые способы понять окружающий нас мир․ И одним из самых захватывающих и плодотворных направлений, без сомнения, является обработка естественного языка, или NLP (Natural Language Processing)․ Сегодня мы хотим пригласить вас в увлекательное путешествие по безграничным возможностям NLP с использованием нашего любимого языка — Python․ Это будет не просто обзор, а глубокое погружение, основанное на нашем многолетнем опыте и тысячах строк кода, написанных в погоне за смыслом, скрытым в словах․ Приготовьтесь, будет интересно!
Мы часто сталкиваемся с огромными объемами текстовых данных: от отзывов клиентов и постов в социальных сетях до юридических документов и медицинских записей․ Представьте, сколько ценной информации скрыто в этих массивах! Человеку физически невозможно проанализировать всё это вручную․ Именно здесь на помощь приходит NLP — мощный инструмент, который позволяет компьютерам понимать, интерпретировать и даже генерировать человеческий язык․ Наше путешествие покажет, как Python, с его богатой экосистемой библиотек, становится идеальным проводником в этом мире․ Мы будем говорить о том, как извлекать смысл, находить закономерности и принимать обоснованные решения, опираясь на глубинный анализ текста․
Основы, Без Которых Никуда: Токенизация, Стемминг и Лемматизация
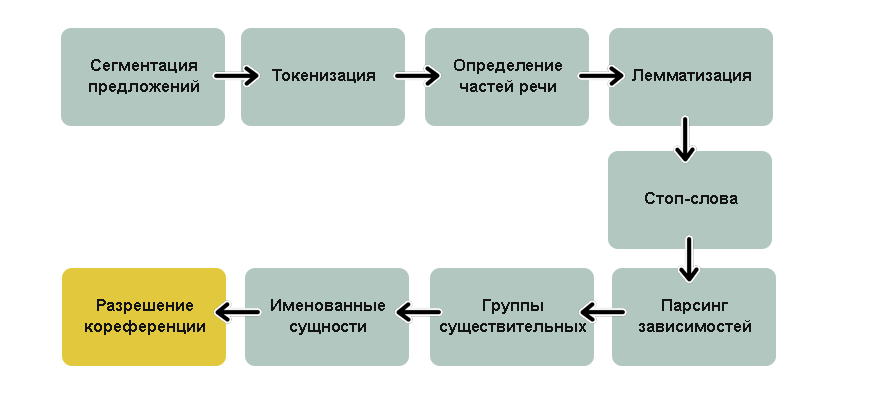
Прежде чем мы начнем строить сложные модели и извлекать глубокие смыслы, нам нужно научиться "готовить" текст для анализа․ Представьте, что вы хотите испечь пирог: сначала нужно подготовить ингредиенты, измерить их, возможно, что-то нарезать․ То же самое и с текстом․ Сырые текстовые данные полны шума, разных форм слов и пунктуации, которые могут помешать нашим алгоритмам․ Мы начинаем с основ, которые составляют фундамент любой задачи NLP․
Первым шагом в этом процессе является токенизация․ Это процесс разбиения текста на мельчайшие значимые единицы, называемые токенами․ Чаще всего токенами являются слова или знаки препинания․ Например, предложение "Мы любим NLP!" будет разбито на токены ["Мы", "любим", "NLP", "!"]․ Мы используем такие библиотеки, как NLTK (Natural Language Toolkit) и spaCy, которые предоставляют мощные и гибкие токенизаторы․ NLTK, например, предлагает несколько типов токенизаторов, включая WordPunctTokenizer, который разбивает слова и пунктуацию отдельно, что очень полезно для детального анализа․
После токенизации мы часто сталкиваемся с проблемой различных форм одного и того же слова․ Например, "бежать", "бежит", "бегал" — все они относятся к одному и тому же корню действия․ Здесь в игру вступают стемминг и лемматизация․ Стемминг, это процесс усечения слова до его основы (стеммы), которая может не быть корректным словом языка․ Например, "running" может стать "runn"․ Это быстрый, но иногда грубый метод․ Лемматизация, с другой стороны, более сложный процесс, который приводит слово к его базовой словарной форме (лемме), используя морфологический анализ․ Так, "running" станет "run", а "better" — "good"․ Для лемматизации мы предпочитаем использовать spaCy или продвинутые возможности NLTK, так как они обеспечивают более точные результаты, что критично для задач, где сохранение семантики слова имеет значение․
Регулярные Выражения: Ваш Швейцарский Нож для Предобработки
Помимо токенизации и стемминга/лемматизации, нам часто приходится выполнять более специфические операции по очистке текста․ Например, удалять HTML-теги, URL-адреса, числа или специальные символы․ Здесь на помощь приходят регулярные выражения (re), невероятно мощный инструмент для поиска и манипулирования текстовыми паттернами․ С их помощью мы можем создавать сложные правила для идентификации и удаления нежелательных элементов, приведения текста к нижнему регистру или замены аббревиатур․ Мы всегда начинаем с очистки данных, ведь "мусор на входе — мусор на выходе" — это золотое правило в машинном обучении и NLP․
Основные Инструменты Python для NLP: NLTK, spaCy и TextBlob
Когда дело доходит до выбора инструментов, Python предлагает целый арсенал библиотек, каждая из которых имеет свои сильные стороны․ Мы часто используем комбинацию этих библиотек, чтобы получить максимальную гибкость и производительность․
NLTK: Университетская Основа
NLTK (Natural Language Toolkit) — это, пожалуй, одна из старейших и наиболее полных библиотек для NLP в Python․ Мы рассматриваем её как своего рода "университетский курс" по NLP․ Она предоставляет широкий спектр алгоритмов для токенизации, стемминга, лемматизации, POS-теггинга (разметки частей речи), синтаксического анализа и даже базового тематического моделирования․ Её модульная структура позволяет нам глубоко понимать каждый шаг обработки текста․ NLTK отлично подходит для образовательных целей и для случаев, когда требуется тонкая настройка каждого компонента․ Например, для морфологического анализа русского языка NLTK предлагает различные словари и алгоритмы, которые можно настроить под конкретные задачи․
spaCy: Скорость и Производительность в Продакшене
Если NLTK — это учебник, то spaCy — это высокопроизводительный, готовый к продакшену фреймворк․ Мы часто обращаемся к spaCy, когда нам нужна скорость и эффективность․ Он предоставляет предварительно обученные модели для различных языков, включая русский, что позволяет нам выполнять такие задачи, как распознавание именованных сущностей (NER), синтаксический парсинг, лемматизация и POS-теггинг с высокой точностью и скоростью․ SpaCy разработан с учетом современных требований к NLP: он оптимизирован для больших объемов данных и обладает интуитивно понятным API․ Мы используем его для быстрого прототипирования и для развертывания NLP-моделей в реальных приложениях․
TextBlob: Простота для Быстрых Задач
Для быстрых и несложных задач NLP мы иногда обращаемся к TextBlob․ Это удобная библиотека, построенная поверх NLTK, которая предоставляет простой API для выполнения таких операций, как анализ тональности, извлечение ключевых фраз, перевод и проверка орфографии․ Мы ценим TextBlob за его простоту, когда нужно быстро получить общую картину или протестировать гипотезу без глубокого погружения в детали реализации․ Однако, важно помнить о её ограничениях: для более сложных или критически важных задач мы всегда предпочитаем более мощные и гибкие инструменты․
Представление Текста: Как Компьютер "Видит" Слова
Компьютеры не понимают слова так, как мы․ Им нужны числа․ Поэтому одним из ключевых аспектов NLP является преобразование текста в числовые векторы, которые могут быть обработаны алгоритмами машинного обучения․ Мы исследовали множество методов и убедились, что выбор правильного представления текста критически важен для успеха любой задачи․
Векторизаторы Старой Школы: CountVectorizer и TfidfVectorizer
Начнем с классики․ CountVectorizer, это простой, но эффективный способ преобразовать коллекцию текстовых документов в матрицу подсчета токенов․ Каждая строка матрицы представляет документ, а каждый столбец — уникальное слово из всего корпуса․ Значение в ячейке — это частота слова в документе․ Мы используем его, когда важна простая частотность слов․
Однако, просто частотность не всегда отражает важность слова․ Слово "и" или "в" может быть очень частым, но не нести много смысла․ Здесь на помощь приходит TfidfVectorizer (Term Frequency-Inverse Document Frequency)․ Этот векторизатор не только учитывает частоту слова в документе (TF), но и его редкость во всем корпусе документов (IDF)․ Чем реже слово встречается в других документах, тем выше его IDF, и, следовательно, выше его вес TF-IDF․ Мы часто используем TF-IDF для задач классификации текстов, так как он помогает выделить наиболее значимые слова․
Эпоха Word Embeddings: Word2Vec, GloVe и FastText
Современные подходы к представлению текста гораздо более изощренные․ Word Embeddings — это плотные векторные представления слов, которые захватывают семантические и синтаксические отношения между словами․ Идея в том, что слова, имеющие схожее значение, будут расположены близко друг к другу в многомерном векторном пространстве․
Word2Vec (реализованный, например, в библиотеке Gensim) стал настоящим прорывом․ Он использует нейронные сети для обучения векторов слов, анализируя их контекст․ Мы работаем с двумя основными архитектурами Word2Vec: Skip-gram (предсказывает контекстные слова по центральному слову) и CBOW (Continuous Bag-of-Words, предсказывает центральное слово по контексту);
GloVe (Global Vectors for Word Representation), еще один популярный метод, который сочетает в себе глобальные статистические данные о частотности слов с локальными контекстами․ Мы используем GloVe, когда нам нужны предварительно обученные векторы, которые хорошо работают с широким спектром задач․
FastText, разработанный Facebook, является расширением Word2Vec․ Его ключевое преимущество в том, что он учитывает подсловные единицы (символьные n-граммы), что делает его особенно эффективным для работы с редкими словами (OOV ─ Out-Of-Vocabulary) и морфологически богатыми языками, такими как русский․ Мы часто обращаемся к FastText, когда имеем дело с текстами, содержащими много опечаток или новых, неологизмов․
"Язык — это дорожная карта культуры․ Он говорит вам, откуда пришли его люди и куда они направляются․"
— Рита Мэй Браун
Doc2Vec и Sentence Transformers: От Слов к Предложениям и Документам
Если Word Embeddings отлично подходят для слов, то что делать, если нам нужно получить векторное представление целого предложения или документа? Здесь на помощь приходят Doc2Vec (также известный как Paragraph2Vec, реализованный в Gensim) и Sentence Transformers․ Doc2Vec распространяет идею Word2Vec на документы, создавая вектор для каждого документа, который отражает его семантику․ Sentence Transformers, в свою очередь, позволяют нам генерировать высококачественные эмбеддинги для предложений и документов, которые могут быть использованы для поиска семантически похожих текстов, кластеризации или классификации․ Мы используем их для задач, где сравнение документов или предложений по смыслу является ключевым, например, для поиска дубликатов или построения вопросно-ответных систем․
Продвинутые Задачи NLP: Извлечение Смысла и Структуры
После того как мы подготовили текст и научились его векторизовать, мы можем перейти к решению более сложных и интересных задач․ Это то, где NLP по-настоящему раскрывает свой потенциал, позволяя нам извлекать неочевидные инсайты из больших объемов данных․
Распознавание Именованных Сущностей (NER)
NER — это задача идентификации и классификации именованных сущностей в тексте (например, имена людей, организации, местоположения, даты, денежные суммы)․ Мы используем NER для автоматического извлечения структурированной информации из неструктурированного текста․ Например, из новостной статьи мы можем извлечь имена всех упомянутых людей и организаций․ SpaCy и Flair предлагают отличные, предварительно обученные модели для NER, которые мы активно используем․ Для специализированных доменов (например, юридических или медицинских документов) мы часто обучаем свои собственные NER-модели, используя CRF (Conditional Random Fields) или современные трансформерные архитектуры․
Анализ Тональности (Sentiment Analysis)
Анализ тональности позволяет нам определить эмоциональную окраску текста — является ли он положительным, отрицательным или нейтральным․ Это чрезвычайно полезно для анализа отзывов клиентов, постов в социальных сетях, финансовых новостей или любых других текстов, где важно понять отношение автора․ Мы используем различные подходы:
VADER (Valence Aware Dictionary and sEntiment Reasoner) — для англоязычных текстов VADER является быстрым и эффективным правилом, основанным на словарях, который учитывает не только слова, но и их интенсивность, использование заглавных букв и пунктуацию․
Тематическое Моделирование (Topic Modeling): LDA и NMF
Когда у нас есть большой корпус документов, и мы хотим понять, о чем они говорят, без предварительной разметки, мы обращаемся к тематическому моделированию․ Это метод машинного обучения без учителя, который позволяет обнаружить скрытые "темы" в коллекции документов․
LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing) — это классические алгоритмы, реализованные в библиотеке Gensim․ Они предполагают, что каждый документ состоит из смеси тем, а каждая тема характеризуется набором слов․ Мы используем LDA для извлечения ключевых тем из больших коллекций текстов, например, для анализа отзывов о продуктах по категориям или выявления скрытых тем в новостных статьях․
NMF (Non-Negative Matrix Factorization) — еще один мощный метод для тематического моделирования, часто используемый в Scikit-learn․ Мы сравниваем LDA и NMF, чтобы выбрать наиболее подходящий алгоритм для конкретной задачи, исходя из характеристик данных и желаемой интерпретируемости результатов․
Классификация Текстов: Автоматическая Категоризация
Классификация текстов, это одна из наиболее распространенных задач NLP, которая заключается в присвоении заранее определенных категорий текстовым документам․ Будь то спам-фильтрация, категоризация новостей или анализ отзывов, классификация текстов незаменима․ Мы используем Scikit-learn для реализации различных алгоритмов машинного обучения:
Мы также применяем PyTorch/TensorFlow для создания нейросетей, таких как LSTM (Long Short-Term Memory) или сверточные нейронные сети (CNN), когда требуется уловить более сложные паттерны и зависимости в тексте, особенно для больших объемов данных․
Суммаризация Текста: Извлекаем Суть
В современном мире, где информации становится все больше, способность быстро извлекать ключевую информацию из длинных текстов становится бесценной․ Суммаризация текста решает эту проблему, создавая краткое, но информативное изложение исходного документа․ Мы различаем два основных подхода:
Экстрактивная суммаризация: Мы выбираем наиболее важные предложения из оригинального текста и объединяем их․ Для этого мы часто используем такие алгоритмы, как TextRank, который строит граф предложений и ранжирует их по важности․
Абстрактивная суммаризация: Это более сложная задача, которая включает генерацию новых предложений, которые передают смысл исходного текста, но не обязательно присутствуют в нем․ Для этого мы обращаемся к трансформерным моделям (например, Hugging Face), которые способны генерировать связный и осмысленный текст․
Эпоха Трансформеров: Революция в NLP
Последние несколько лет стали свидетелями настоящей революции в NLP благодаря появлению архитектуры Трансформеров․ Эти модели, такие как BERT, GPT, RoBERTa и другие, изменили наше представление о том, что возможно в обработке языка․ Мы активно используем их для решения самых сложных задач․
Hugging Face: Ваш Проводник в Мир Трансформеров
Библиотека Hugging Face Transformers стала де-факто стандартом для работы с трансформерными моделями․ Она предоставляет удобный интерфейс для загрузки и использования сотен предварительно обученных моделей для различных языков и задач, таких как:
Классификация текста: Анализ тональности, категоризация документов, определение спама․
Распознавание именованных сущностей (NER): Извлечение персон, организаций, дат․
Вопросно-ответные системы (QA): Поиск ответов на вопросы в тексте․
Генерация текста: Создание связных и осмысленных текстов, например, для чат-ботов или автоматического создания контента․
Машинный перевод: Перевод текстов между языками․
Мы используем BERT (Bidirectional Encoder Representations from Transformers) для задач классификации и NER, поскольку он обеспечивает контекстное встраивание слов, что значительно повышает точность․ Для генерации текста и диалогов мы обращаемся к моделям семейства GPT (Generative Pre-trained Transformer), которые показывают удивительные результаты в создании связного и креативного контента․ Тонкая настройка (Fine-tuning) предварительно обученных моделей на наших специфических данных позволяет нам достигать впечатляющих результатов даже с ограниченным объемом размеченных данных․
Специализированные Приложения и Продвинутые Техники
Мир NLP гораздо шире, чем просто анализ тональности или NER․ Мы регулярно сталкиваемся с уникальными задачами, требующими нестандартных подходов и использования специализированных библиотек․
Работа с Разнообразными Источниками и Форматами
Веб-скрейпинг текста (Beautiful Soup): Часто первичные данные находятся на веб-сайтах․ Beautiful Soup — наша основная библиотека для извлечения текстового контента из HTML-страниц․
Извлечение текста из PDF (PyMuPDF): Юридические документы, отчеты, научные статьи часто хранятся в формате PDF․ PyMuPDF позволяет нам эффективно извлекать текст из таких файлов для дальнейшего анализа․
Обработка многоязычных текстовых корпусов (Polyglot, Stanza): Мы работаем с текстами на разных языках․ Polyglot и Stanza (особенно полезна для языков с богатой морфологией, таких как русский) предоставляют инструменты для токенизации, POS-теггинга и NER для многих языков;
Построение Интеллектуальных Систем
Разработка чат-ботов (Rasa framework): Для создания интерактивных чат-ботов мы используем Rasa․ Она позволяет нам создавать диалоговые системы, которые понимают намерения пользователя и генерируют осмысленные ответы․
Вопросно-ответные системы (QA): На основе трансформерных моделей и Doc2Vec мы разрабатываем QA-системы, которые могут находить точные ответы на вопросы в больших базах знаний или документах․
Разработка систем машинного перевода: Хотя это сложная задача, с помощью трансформеров (например, из Hugging Face) мы можем создавать прототипы систем машинного перевода, а для узкоспециализированных текстов, разрабатывать собственные модели․
Глубокий Анализ и Извлечение Информации
Анализ частотности слов и n-грамм: Базовый, но мощный инструмент для понимания доминирующих тем и ключевых фраз․ Мы используем его для выявления сезонности в текстовых данных или анализа поведенческих паттернов в чатах․
Извлечение ключевых фраз (RAKE, TextRank): RAKE (Rapid Automatic Keyword Extraction) и TextRank помогают нам автоматически извлекать наиболее релевантные ключевые слова и фразы из текста․
Анализ стилистики текстов и определение авторства: Изучая лексическое богатство, частотность функциональных слов и другие стилистические характеристики, мы можем анализировать авторский почерк и даже определять авторство текста․
Извлечение фактов и связей между сущностями: Это продвинутая задача, которая позволяет нам не только идентифицировать сущности, но и определять отношения между ними (например, "Организация X расположена в Городе Y")․
Визуализация и Оценка
Инструменты для визуализации текстовых данных (Word Clouds, Heatmaps): Для наглядного представления результатов анализа мы используем Word Clouds (облака слов) для визуализации частотности слов и тепловые карты для отображения корреляций или распределений;
Оценка качества моделей (F1-score, Precision, Recall): Мы всегда тщательно оцениваем наши NLP-модели, используя стандартные метрики, такие как точность (Precision), полнота (Recall) и F1-мера, чтобы убедиться в их надежности и эффективности․
Работа со Сложностями Реального Мира
Обработка неструктурированного текста: Очистка данных: Мы сталкиваемся с грязными данными, опечатками, сленгом и эмодзи․ Разработка инструментов для проверки грамматики, исправления орфографии, нормализации сленга и очистки от пунктуации является неотъемлемой частью нашей работы․
Проблемы обработки неполных и ошибочных данных: Разработка надежных систем требует учета возможных ошибок и неполноты данных, что часто включает применение робастных алгоритмов и методов обработки исключений․
Обработка больших текстовых массивов (Big Data NLP): Для работы с терабайтами текстовых данных мы используем распределенные вычисления и оптимизированные библиотеки, такие как Gensim, способные эффективно обрабатывать большие корпусы․
Мы прошли долгий путь от простейшей токенизации до создания сложных трансформерных моделей, способных генерировать осмысленный текст и отвечать на вопросы․ Мир NLP постоянно развивается, и каждый день появляются новые, более совершенные алгоритмы и подходы․ Мы убеждены, что Python останется краеугольным камнем в этой области благодаря своей гибкости, обширному сообществу и постоянно растущей экосистеме библиотек․
Наш опыт показывает, что ключ к успеху в NLP заключается не только в знании алгоритмов, но и в глубоком понимании предметной области, умении правильно подготовить данные и критически оценивать результаты․ Мы продолжим экспериментировать, учиться и делиться своими открытиями, ведь каждый новый проект — это возможность раскрыть очередную тайну, скрытую в словах․ Помните, что каждый текст — это не просто набор символов, а окно в мысли, чувства и намерения людей․ И NLP дает нам инструменты, чтобы заглянуть в это окно․
На этом статья заканчивается․




