
- Расшифровка Языка Цифрового Мира: Ваш Путеводитель по NLP в Python
- Первые Шаги: Основы Предобработки Текста
- От Стемминга к Лемматизации: Приводим Слова к Порядку
- Удаление Стоп-Слов и Регулярные Выражения
- Представление Текста: От Слов к Числам
- Простые Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: Смысл в Векторах
- Ключевые Задачи NLP: Разбираем Смысл
- Распознавание Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis)
- Тематическое Моделирование (Topic Modeling)
- Классификация Текстов
- Мир Трансформеров: Революция в NLP
- BERT и Hugging Face Transformers
- Продвинутое Применение и Инструменты
- Извлечение Информации и Вопросно-Ответные Системы
- Работа с Многоязычными Данными и Специфическими Форматами
- Разработка Чат-ботов и Генерация Текста
- Анализ Стилистики и Обнаружение Плагиата
- Визуализация и Оценка Моделей
- Вызовы и Будущее NLP
Расшифровка Языка Цифрового Мира: Ваш Путеводитель по NLP в Python
Привет, друзья! Мы, как заядлые исследователи цифровых глубин, прекрасно понимаем, как важно сегодня не просто потреблять информацию, но и уметь извлекать из нее смысл, структурировать, анализировать и даже генерировать новые данные. В эпоху, когда тексты окружают нас повсюду – от электронных писем и социальных сетей до научных статей и юридических документов – способность машин понимать человеческий язык становится не просто полезным навыком, а настоящей суперсилой. Именно об этом мы сегодня и хотим поговорить: о Natural Language Processing (NLP), или обработке естественного языка, и о том, как Python стал нашим незаменимым союзником в этом увлекательном путешествии.
Мы помним времена, когда работа с текстом для компьютера казалась чем-то из области фантастики. Но благодаря постоянному развитию алгоритмов и появлению мощных библиотек, таких как NLTK, spaCy, Gensim и Hugging Face Transformers, мы смогли превратить эту фантастику в повседневную реальность. В этой статье мы с вами пройдем путь от самых азов до продвинутых концепций NLP, делясь нашим собственным опытом, практическими советами и, конечно же, примерами того, как эти инструменты помогают нам раскрывать тайны текстовых данных. Приготовьтесь, будет интересно!
Первые Шаги: Основы Предобработки Текста
Прежде чем мы сможем заставить компьютер "понять" текст, нам необходимо его подготовить. Человеческий язык полон нюансов, опечаток, сленга и множества форм одного и того же слова. Для машины всё это – просто набор символов. Поэтому предобработка текста является краеугольным камнем любого NLP-проекта. Мы начинаем с приведения текста к унифицированному виду, что значительно упрощает дальнейший анализ.
Одним из первых и самых важных этапов является токенизация. Это процесс разбиения текста на более мелкие, осмысленные единицы – токены. Токенами могут быть слова, пунктуация, числа и даже эмодзи. Без правильной токенизации мы не сможем эффективно работать ни с частотностью слов, ни с их смыслом. Мы часто используем библиотеку NLTK для этого, поскольку она предлагает различные токенизаторы, адаптированные под разные языки и задачи. Например, NLTK может разделять "don’t" на "do" и "n’t", что важно для анализа.
От Стемминга к Лемматизации: Приводим Слова к Порядку
После токенизации мы сталкиваемся с проблемой: одно и то же слово может иметь множество форм ("бежать", "бежит", "бежал", "бегущий"). Чтобы компьютер воспринимал их как одно и то же понятие, нам нужны процессы стемминга и лемматизации.
Стемминг – это грубый, но быстрый процесс удаления окончаний и суффиксов, чтобы получить "корень" слова. Например, слова "работать", "работал", "рабочий" могут быть сведены к корню "работ". Мы используем стеммеры из NLTK, такие как PorterStemmer или SnowballStemmer, которые хорошо справляются с английским языком и имеют версии для некоторых других языков, включая русский. Однако у стемминга есть недостаток: полученные "корни" часто не являются настоящими словами и могут быть бессмысленными.
Лемматизация, в отличие от стемминга, является более интеллектуальным процессом. Она приводит слово к его базовой словарной форме, или лемме, с учетом морфологического анализа и части речи. Например, "был", "есть", "будет" будут приведены к лемме "быть". Для лемматизации мы предпочитаем spaCy, поскольку она предлагает более точную и контекстно-зависимую лемматизацию для многих языков. Stanza также является отличным выбором, особенно для языков с богатой морфологией, таких как русский, где NLTK может быть менее эффективен. Это позволяет нам значительно улучшить качество анализа, особенно при работе со смыслом.
Вот как мы сравниваем эти подходы на практике:
| Метод | Принцип работы | Пример | Преимущества | Недостатки |
|---|---|---|---|---|
| Стемминг | Удаление окончаний по правилам | "running" -> "runn" | Быстрый, простой | Получаются нереальные слова, теряется смысл |
| Лемматизация | Приведение к словарной форме с учетом морфологии | "running" -> "run" | Точный, сохраняет смысл | Медленнее, требует больше ресурсов |
Удаление Стоп-Слов и Регулярные Выражения
Далее мы удаляем стоп-слова – это часто встречающиеся, но обычно малозначимые слова, такие как "и", "в", "на", "он", "она". Они не несут существенной смысловой нагрузки, но при этом занимают много места и могут искажать результаты анализа частотности. NLTK предлагает готовые списки стоп-слов для различных языков, которые мы можем легко расширять или модифицировать под конкретные нужды нашего проекта.
Наконец, регулярные выражения (re) становятся нашим швейцарским армейским ножом для очистки текста. С их помощью мы можем удалять HTML-теги, специальные символы, числа, ссылки, приводить текст к нижнему регистру, исправлять орфографию (хотя для сложных случаев существуют отдельные инструменты) и многое другое. Мы используем регулярные выражения для стандартизации текста, удаления шума и извлечения конкретных паттернов. Например, чтобы извлечь все даты или адреса электронной почты.
Представление Текста: От Слов к Числам
Компьютеры лучше всего работают с числами. Поэтому, чтобы применить к тексту методы машинного обучения, нам необходимо преобразовать слова и фразы в числовые векторы. Этот процесс называется векторизацией текста, и он является ключевым этапом в NLP.
Простые Векторизаторы: CountVectorizer и TF-IDF
Начнем с классики – CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn. CountVectorizer просто подсчитывает частоту вхождения каждого слова в документе. В результате мы получаем матрицу, где строки – это документы, а столбцы – уникальные слова, и на пересечении стоит количество вхождений слова в документ. Это простой, но часто эффективный метод.
Однако простое количество вхождений не всегда отражает важность слова. Слово "и" может встречаться часто, но не нести много смысла. Здесь на помощь приходит TfidfVectorizer, который использует метрику TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF учитывает не только частоту слова в конкретном документе (Term Frequency), но и его редкость во всем корпусе документов (Inverse Document Frequency). Чем реже слово встречается в корпусе, но чаще в конкретном документе, тем выше его вес. Это позволяет нам выделить наиболее "значимые" слова для каждого документа.
Мы часто используем эти векторизаторы для задач классификации текста, таких как спам-фильтрация или категоризация новостей. Они являются отправной точкой для многих проектов.
Word Embeddings: Смысл в Векторах
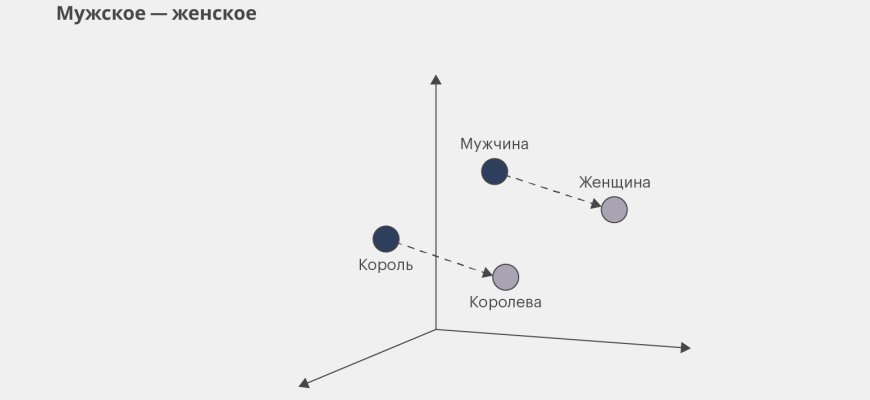
Простые векторизаторы имеют ограничение: они не улавливают семантические связи между словами. Слова "король" и "царь" будут для них совершенно разными, хотя они близки по смыслу. Здесь на сцену выходят Word Embeddings – векторные представления слов, которые кодируют их семантический смысл. Идея проста: слова, которые часто встречаются в похожих контекстах, имеют похожие векторные представления.
Среди наиболее популярных моделей – Word2Vec и GloVe, которые мы часто используем с библиотекой Gensim; Word2Vec, разработанный Google, предлагает два архитектурных подхода: Skip-gram и CBOW (Continuous Bag of Words). Skip-gram предсказывает контекстные слова по центральному слову, а CBOW – наоборот. GloVe (Global Vectors for Word Representation) использует глобальную статистику совместной встречаемости слов. Эти модели позволяют нам выполнять такие операции, как "король ⏤ мужчина + женщина = королева" в векторном пространстве, что просто поразительно!
FastText, также от Facebook, является расширением Word2Vec, которое учитывает подсловные единицы (символьные n-граммы). Это делает его особенно эффективным для работы с редкими словами (OOV – Out-Of-Vocabulary) и морфологически богатыми языками, где Word2Vec может испытывать трудности. Мы применяем FastText, когда имеем дело с большим количеством опечаток или специфической терминологией;
Когда нам нужно представить не только слова, но и целые предложения или документы в виде векторов, мы обращаемся к Doc2Vec (расширение Word2Vec) или Sentence Transformers. Эти методы позволяют нам сравнивать документы по смыслу, находить похожие тексты или кластеризовать их.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
— Рита Мэй Браун
Ключевые Задачи NLP: Разбираем Смысл
После того как текст подготовлен и векторизован, мы можем приступить к решению конкретных задач NLP. Их спектр огромен, и каждая из них открывает новые возможности для анализа и взаимодействия с текстовыми данными.
Распознавание Именованных Сущностей (NER)
NER (Named Entity Recognition) – это задача идентификации и классификации именованных сущностей в тексте, таких как имена людей, названия организаций, географические объекты, даты, суммы денег и многое другое. Это невероятно полезно для извлечения структурированной информации из неструктурированного текста.
Для быстрого и эффективного NER мы чаще всего используем spaCy. Она поставляется с предварительно обученными моделями для различных языков, которые отлично справляются с этой задачей "из коробки". Например, мы можем легко извлечь все названия компаний из новостных статей или имена клиентов из отзывов. Для более сложных случаев, или когда нам нужна высокая точность на специфических данных, мы прибегаем к моделям на основе CRF (Conditional Random Fields) или Transformer-моделям (о них чуть позже), которые позволяют тонко настраивать распознавание сущностей.
Пример использования spaCy для NER:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Apple Inc. была основана Стивом Джобсом в Купертино 1 апреля 1976 года."
doc = nlp(text)
print("Распознанные сущности:")
for ent in doc.ents:
print(f" {ent.text} ({ent.label_})")
Apple Inc. (ORG)
Стивом Джобсом (PERSON)
Купертино (GPE)
1 апреля 1976 года (DATE)
Анализ Тональности (Sentiment Analysis)
Анализ тональности – это процесс определения эмоциональной окраски текста: позитивный, негативный или нейтральный. Это критически важно для анализа отзывов клиентов, мониторинга социальных сетей, понимания общественного мнения о продукте или событии. Мы используем его для оценки реакции на наши статьи и продукты.
Для простого и быстрого анализа тональности английского текста мы часто применяем библиотеку VADER (Valence Aware Dictionary and sEntiment Reasoner), которая входит в NLTK. VADER особенно хорошо работает с текстами из социальных сетей, так как учитывает сленг, эмодзи и пунктуацию. Для более сложных задач и мультиязычного анализа мы переходим к моделям машинного обучения, обученным на больших размеченных корпусах, или используем Transformer-модели, которые показывают выдающиеся результаты.
Библиотека TextBlob также предлагает простой API для анализа тональности и других NLP-задач. Она удобна для быстрого прототипирования, хотя для серьезных проектов мы часто ищем более мощные и гибкие альтернативы.
Тематическое Моделирование (Topic Modeling)
Представьте, что у вас есть огромный архив текстов, и вам нужно понять, о чем они вообще. Тематическое моделирование помогает нам автоматически обнаруживать скрытые "темы" в коллекции документов. Оно группирует слова, которые часто встречаются вместе, в кластеры, представляющие собой определенные темы.
Для тематического моделирования мы активно используем библиотеку Gensim. Наиболее популярные алгоритмы – это LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing). LDA предполагает, что каждый документ представляет собой смесь нескольких тем, а каждая тема – это смесь слов. LSI же использует сингулярное разложение для выявления латентных семантических связей между словами и документами.
Мы также сравниваем их с другими методами, такими как NMF (Non-negative Matrix Factorization) из Scikit-learn, который также хорошо работает для извлечения тем. Выбор метода зависит от характеристик данных и требуемой интерпретируемости результатов. Мы часто визуализируем результаты тематического моделирования, чтобы лучше понять, какие темы доминируют в наших данных.
Классификация Текстов
Классификация текстов – это одна из самых распространенных задач NLP, которая заключается в присвоении тексту одной или нескольких категорий. Примеры включают спам-фильтрацию, категоризацию новостей по рубрикам, определение авторства текста или анализ отзывов по категориям продуктов.
Для этой задачи мы широко применяем библиотеку Scikit-learn, которая предоставляет множество алгоритмов машинного обучения: SVM (Support Vector Machines), Наивный Байесовский классификатор, Логистическая регрессия и другие. Мы используем векторизаторы (TF-IDF) для преобразования текста в числовой формат, а затем обучаем классификаторы. Для более сложных сценариев, особенно когда объемы данных велики, мы переходим к использованию нейросетей на PyTorch/TensorFlow, включая LSTM-сети, которые способны улавливать долгосрочные зависимости в тексте.
Мир Трансформеров: Революция в NLP
Последние годы ознаменовались настоящей революцией в NLP благодаря появлению Transformer-моделей. Эти архитектуры, основанные на механизме внимания, изменили наше представление о том, что могут делать машины с языком. Они способны обрабатывать текст с учетом контекста, что привело к беспрецедентным результатам во многих задачах.
BERT и Hugging Face Transformers
Среди Transformer-моделей особое место занимает BERT (Bidirectional Encoder Representations from Transformers) от Google. BERT обучается на огромных объемах текста и способен понимать контекст слова, учитывая как предыдущие, так и последующие слова в предложении. Это делает его невероятно мощным для таких задач, как NER, классификация, вопросно-ответные системы и анализ тональности.
Мы активно используем библиотеку Hugging Face Transformers, которая предоставляет простой и унифицированный интерфейс для работы с сотнями предварительно обученных Transformer-моделей (BERT, GPT, RoBERTa, XLNet и многие другие). Мы можем легко загружать модели, выполнять тонкую настройку (Fine-tuning) на своих данных для конкретных задач, а также использовать их для генерации текста, машинного перевода или суммаризации. Это позволяет нам достигать состояния "state-of-the-art" даже с ограниченными ресурсами.
Например, для генерации текста мы можем использовать модели типа GPT, а для суммаризации – T5 или BART. Возможности практически безграничны. Мы даже используем их для анализа кода и выявления связей между сущностями в сложных документах.
Продвинутое Применение и Инструменты
Помимо основных задач, NLP открывает двери для множества специализированных и продвинутых приложений, которые мы активно исследуем и внедряем.
Извлечение Информации и Вопросно-Ответные Системы
Извлечение ключевых фраз и ключевых предложений – это задача, которая помогает быстро понять суть документа. Мы используем алгоритмы типа TextRank (на основе Google PageRank) или RAKE (Rapid Automatic Keyword Extraction) для автоматического выделения наиболее важных элементов текста. Это очень полезно для создания тегов, суммаризации или индексации контента.
Вопросно-ответные системы (QA) – это вершина NLP, позволяющая машине отвечать на вопросы, заданные на естественном языке, используя предоставленный ей текст или базу знаний. С появлением Transformer-моделей, таких как BERT, мы можем создавать системы, которые способны находить точные ответы в больших объемах текста. Это меняет подход к поиску информации и взаимодействию с базами знаний.
Работа с Многоязычными Данными и Специфическими Форматами
В нашем глобальном мире тексты редко бывают только на одном языке. Обработка многоязычных текстовых корпусов – это отдельный вызов. Библиотеки, такие как TextBlob и Polyglot, предоставляют базовые функции для определения языка и перевода, но для более глубокого анализа мы опять же обращаемся к Transformer-моделям, которые могут работать с разными языками или быть обучены на мультиязычных корпусах.
Кроме того, текст часто хранится не в чистом виде. Мы используем Beautiful Soup для веб-скрейпинга и извлечения текста из HTML-страниц, а PyMuPDF для извлечения текста из PDF-документов. Эти инструменты позволяют нам получить доступ к данным, которые иначе были бы недоступны для анализа.
Разработка Чат-ботов и Генерация Текста
Разработка чат-ботов – еще одна увлекательная область применения NLP. Мы экспериментируем с фреймворками вроде Rasa, который позволяет создавать диалоговые системы с пониманием естественного языка и способностью вести осмысленные беседы; Это требует глубокого понимания интентов пользователя и управления диалогом.
Генерация текста с использованием Transformer-моделей (например, GPT-2, GPT-3) открыла новые горизонты. Мы можем генерировать статьи, стихи, программный код, ответы на вопросы и даже целые диалоги. Это не просто "создание случайных слов", а генерация связного, грамматически корректного и, что самое главное, осмысленного текста, который часто трудно отличить от написанного человеком.
Анализ Стилистики и Обнаружение Плагиата
Мы также применяем NLP для более тонких задач, таких как анализ стилистики текстов, чтобы определить авторский почерк или выявить аномалии. Это может быть полезно в криминалистике или при анализе больших литературных корпусов. Разработка систем обнаружения плагиата – еще одна важная задача, где NLP играет ключевую роль, сравнивая тексты на предмет сходства и выявляя заимствования, часто используя метрики вроде TextDistance.
Визуализация и Оценка Моделей
Числа и векторы – это хорошо, но для человека гораздо понятнее визуальные представления. Мы используем различные инструменты для визуализации текстовых данных, такие как облака слов (Word Clouds) для быстрого понимания наиболее частых терминов, тепловые карты для визуализации матриц сходства или графики распределения тем.
Оценка качества NLP-моделей – это не менее важный этап. Для задач NER и классификации мы используем метрики, такие как F1-score, Precision и Recall, которые дают нам четкое представление о производительности модели. Для тематического моделирования или суммаризации оценка может быть более субъективной, но существуют и количественные метрики.
Вызовы и Будущее NLP
Несмотря на впечатляющие успехи, NLP все еще сталкивается с рядом вызовов. Проблемы обработки неполных и ошибочных данных, таких как опечатки, сленг, эмодзи, сарказм, требуют постоянного совершенствования алгоритмов и подходов. Работа с нелатинскими алфавитами и редкими языками также представляет собой отдельный вызов, требующий специализированных моделей и корпусов данных.
Мы постоянно ищем способы улучшить наши инструменты для проверки грамматики и орфографии, нормализации сленга и пунктуации. Анализ тональности с учетом сарказма – это одна из самых сложных задач, которая требует глубокого контекстного понимания.
Будущее NLP обещает быть еще более захватывающим. Мы видим все большее применение GPU-ускорения для обработки текста, что позволяет работать с огромными массивами данных (Big Data NLP) и обучать еще более сложные модели. Развитие систем для автоматической разметки данных и создания словарей и тезаурусов ускорит разработку новых решений. Мы на пороге создания систем, способных не просто понимать, но и активно взаимодействовать с миром через язык, делая его более доступным и понятным для всех.
Мы надеемся, что этот обзор помог вам сориентироваться в огромном и увлекательном мире NLP на Python; Наш путь в этой области продолжается, и мы с нетерпением ждем новых открытий и возможностей, которые ждут нас впереди. Присоединяйтесь к нам в этом путешествии!
Подробнее: Дополнительные запросы по теме
| Обучение NER с Flair | Векторизация предложений Sentence Transformers | Сравнение LDA и NMF | Тонкая настройка BERT для классификации | PyTorch/TensorFlow для NLP |
| Gensim для тематического моделирования | Анализ тональности VADER | Применение spaCy для синтаксического парсинга | TextRank для извлечения ключевых фраз | Регулярные выражения в предобработке текста |







