
- Разгадываем Язык Цифрового Мира: Наш Путь в Захватывающий Мир Обработки Естественного Языка (NLP)
- Первые Шаги: Строим Фундамент Понимания Текста
- Быстрый Старт с TextBlob
- От Слов к Числам: Векторизация и Встраивания
- Традиционные Векторизаторы: CountVectorizer и TfidfVectorizer
- Word Embeddings: Отдельные Слова в Контексте
- Трансформеры: Революция в Понимании Контекста
- Ключевые Задачи NLP: От Сентимента до Генерации
- Распознавание Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis)
- Тематическое Моделирование и Извлечение Информации
- Суммаризация и Генерация Текста
- Машинный Перевод и Вопросно-Ответные Системы
- Продвинутые Приложения и Инструменты
- Работа с Большими Данными и Неструктурированным Текстом
- Создание Интеллектуальных Систем
- Специализированные Приложения
- Визуализация и Оценка
Разгадываем Язык Цифрового Мира: Наш Путь в Захватывающий Мир Обработки Естественного Языка (NLP)
Приветствуем вас, дорогие читатели, в нашем блоге, где мы делимся самыми интересными открытиями из мира технологий и личного опыта. Сегодня мы хотим погрузиться в одну из самых увлекательных и быстро развивающихся областей искусственного интеллекта – Обработку Естественного Языка, или NLP. Это не просто модное слово; это мост, который позволяет компьютерам понимать, интерпретировать и даже генерировать человеческий язык. Представьте себе мир, где машины не просто выполняют команды, а действительно понимают, что мы хотим сказать. Звучит как научная фантастика? Мы покажем вам, что это уже реальность, и как каждый из нас может стать частью этого удивительного процесса.
Наш путь в NLP начался не с чистого листа, а с любопытства и желания разобраться, как же на самом деле работают те умные системы, которые ежедневно нас окружают – от голосовых помощников до систем рекомендаций. Мы быстро поняли, что за кажущейся простотой диалога с ИИ скрывается целый мир сложных алгоритмов, математических моделей и, конечно же, магии программирования. В этой статье мы хотим поделиться нашим обширным опытом и проверенными методами, которые помогают нам превращать хаотичный поток слов в ценные данные и проницательные выводы. Приготовьтесь к увлекательному путешествию, ведь мы собираемся раскрыть перед вами все грани NLP – от самых основ до продвинутых трансформерных моделей.
Первые Шаги: Строим Фундамент Понимания Текста
Прежде чем компьютер сможет "понять" текст, его нужно подготовить. Это похоже на то, как мы учим ребенка читать: сначала буквы, потом слова, затем предложения. В мире NLP этот процесс называется предварительной обработкой, и он является краеугольным камнем любой успешной системы. Мы обнаружили, что без тщательной подготовки данных, даже самые продвинутые модели будут давать неточные результаты. Именно здесь в игру вступают такие фундаментальные концепции, как токенизация, стемминг, лемматизация и работа с регулярными выражениями.
Наш опыт показывает, что начинать следует с библиотеки NLTK (Natural Language Toolkit). Это швейцарский армейский нож для новичков и опытных разработчиков в NLP. NLTK предоставляет нам мощные инструменты для разбиения текста на отдельные слова или предложения – процесс, известный как токенизация. Это кажется простым, но попробуйте правильно разделить "Нью-Йорк" или "И.И. Иванов" без ошибок! Затем мы переходим к упрощению слов. Стемминг обрезает окончания слов, приводя их к общей основе (например, "бежал", "бегущий", "бегать" становятся "бег"). Это грубый, но часто эффективный метод для уменьшения словаря и улучшения производительности модели. Однако, для более точного лингвистического анализа мы предпочитаем лемматизацию, которая приводит слово к его словарной форме (например, "мыши" к "мышь", "лучше" к "хороший"). Это требует более глубокого понимания морфологии языка, и здесь NLTK также приходит на помощь.
| Процесс | Описание | Пример (рус.) | Основная цель |
|---|---|---|---|
| Токенизация | Разбиение текста на минимальные смысловые единицы (токены: слова, предложения). | "Привет, мир!" -> ["Привет", ",", "мир", "!"] | Подготовка текста к анализу. |
| Стемминг | Удаление окончаний и суффиксов для получения основы слова. | "красивый", "красота" -> "красив" | Сокращение словарного запаса, упрощение. |
| Лемматизация | Приведение слова к его словарной (нормальной) форме. | "были", "есть" -> "быть" | Более точное морфологическое упрощение. |
Кроме NLTK, мы активно используем регулярные выражения (библиотека `re`) для точечной предобработки текста. Они позволяют нам находить и заменять специфические паттерны: удалять HTML-теги, пунктуацию, числа или, наоборот, извлекать email-адреса и телефонные номера. Это незаменимый инструмент, когда дело доходит до очистки "грязных" данных, которые мы часто получаем из реальных источников. А для быстрого и простого NLP-анализа, особенно когда нам нужна высокая производительность и готовые модели, мы обращаемся к библиотеке spaCy. Она выделяется своей скоростью и предлагает готовые пайплайны для токенизации, POS-теггинга (определение части речи) и, что особенно ценно, NER (Распознавание Именованных Сущностей), о котором мы поговорим чуть позже. spaCy также отлично справляется с продвинутой лемматизацией, предоставляя более качественные результаты по сравнению со стандартным стеммингом NLTK, особенно для языков с богатой морфологией, как русский.
Быстрый Старт с TextBlob
Иногда нам нужен очень быстрый и интуитивно понятный инструмент для базовых NLP-задач, не требующий глубокого погружения в лингвистические дебри. Здесь на помощь приходит TextBlob. Мы ценим его за простоту API, которая позволяет выполнять токенизацию, POS-теггинг, извлечение фраз и даже анализ тональности всего в несколько строк кода. Это идеальный выбор для прототипирования или небольших проектов, где скорость разработки важнее максимальной точности. Конечно, у TextBlob есть свои ограничения, особенно для сложных задач и многоязычного текста, но для быстрой оценки он незаменим. Для более серьезных задач мы рассматриваем альтернативы, такие как spaCy или NLTK, которые предлагают большую гибкость и производительность.
От Слов к Числам: Векторизация и Встраивания
После того как текст очищен и приведен к удобной форме, возникает следующая задача: как "скормить" его компьютеру? Компьютеры понимают только числа, поэтому нам нужно преобразовать слова и предложения в числовые векторы. Этот процесс называется векторизацией текста, и он является мостом между человеческим языком и математическими моделями. Мы прошли долгий путь от простых методов до сложных нейросетевых встраиваний, и каждый из них имеет свое место в нашем арсенале.
Традиционные Векторизаторы: CountVectorizer и TfidfVectorizer
Наш опыт показывает, что разработка собственных векторизаторов текста начинается с двух классических методов из библиотеки Scikit-learn: CountVectorizer и TfidfVectorizer.
- CountVectorizer: Он просто подсчитывает, сколько раз каждое слово встречается в документе. Это дает нам вектор, где каждая позиция соответствует слову из всего корпуса, а значение – его частоте в текущем документе. Это интуитивно понятно, но может привести к очень большим разреженным векторам и не учитывает важность слов.
- TfidfVectorizer (Term Frequency-Inverse Document Frequency): Этот векторизатор более продвинутый. Он не только учитывает частоту слова в документе (TF), но и его редкость во всем корпусе документов (IDF). Идея проста: чем реже слово встречается в других документах, тем важнее оно для текущего документа. Мы используем TF-IDF, когда нам нужно выделить уникальные и значимые термины для каждого документа, например, при извлечении ключевых фраз или категоризации.
Мы активно используем эти векторизаторы для задач классификации текстов с помощью алгоритмов машинного обучения из Scikit-learn, таких как SVM (Метод опорных векторов) или Наивный Байесовский классификатор. Они являются отличной отправной точкой и часто дают весьма достойные результаты.
Word Embeddings: Отдельные Слова в Контексте
Однако традиционные векторизаторы имеют существенный недостаток: они не улавливают семантические связи между словами. Слова "король" и "королева" могут быть очень далеки друг от друга в пространстве CountVectorizer, хотя семантически они близки. Здесь на сцену выходят Word Embeddings (Векторные Представления Слов). Это плотные векторы, где слова с похожим значением расположены близко друг к другу в многомерном пространстве. Мы активно используем модели Word2Vec и GloVe с использованием Gensim.
- Word2Vec: Эта нейросетевая модель, разработанная Google, учится предсказывать контекст слова или слово по контексту. Мы используем две основные архитектуры: Skip-gram (предсказывает контекст по слову) и CBOW (Continuous Bag of Words) (предсказывает слово по контексту). Gensim делает обучение собственных Word2Vec моделей удивительно простым;
- GloVe (Global Vectors for Word Representation): В отличие от Word2Vec, который основан на локальном контексте, GloVe использует глобальную статистику со-встречаемости слов. Мы находим, что GloVe часто дает хорошие результаты, особенно когда у нас достаточно большой корпус для обучения.
Сравнение методов векторизации (TF-IDF vs Word2Vec) показывает, что Word Embeddings превосходят TF-IDF в задачах, требующих семантического понимания, таких как поиск синонимов, анализ тональности или ответы на вопросы. Для представления целых документов мы используем Doc2Vec (расширение Word2Vec), который позволяет нам получать векторные представления для предложений и документов, что крайне полезно для кластеризации текстов или поиска похожих документов.
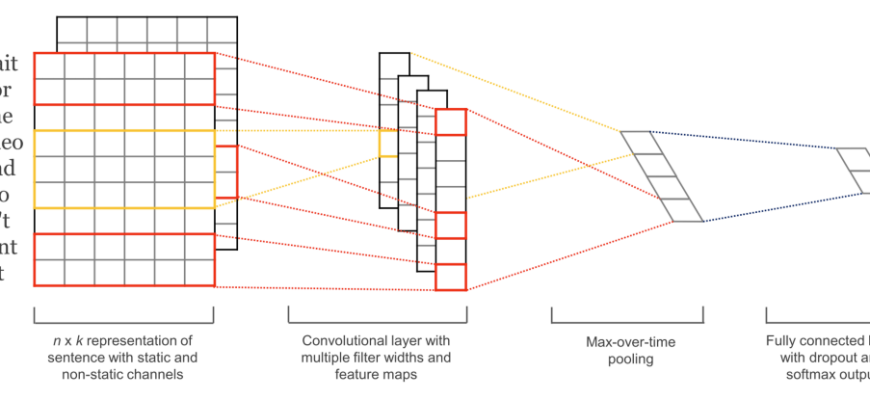
Трансформеры: Революция в Понимании Контекста
Если Word Embeddings стали прорывом, то Трансформеры произвели настоящую революцию в NLP. Это архитектуры нейронных сетей, основанные на механизме внимания, которые позволяют моделям учитывать контекст слова не только ближайших соседей, но и всего предложения, и даже всего документа. Мы активно работаем с библиотекой Hugging Face Transformers, которая стала де-факто стандартом для работы с этими моделями. Она предоставляет доступ к сотням предварительно обученных моделей, таких как BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer) и многим другим.
Мы используем BERT для задач классификации, NER и других задач, требующих глубокого контекстуального понимания. Возможность тонкой настройки (Fine-tuning) предварительно обученных моделей на наших собственных данных позволяет нам достигать беспрецедентной точности. А для векторизации предложений и документов с учётом контекста (контекстное встраивание) мы применяем Sentence Transformers, что дает значительно лучшие результаты по сравнению с простым усреднением Word2Vec векторов.
"Язык – это не просто набор символов; это живая структура, отражающая наши мысли, эмоции и культуру. Научить машину понимать его – значит приоткрыть завесу к разуму."
— Андрей Линде, известный физик-теоретик (хотя и не напрямую по NLP, но его слова о сложности и глубине понимания вполне применимы)
Ключевые Задачи NLP: От Сентимента до Генерации
Когда у нас есть способ представить текст в числовом виде, мы можем решать множество реальных задач. Наш опыт охватывает широкий спектр приложений, каждое из которых приносит свои уникальные вызовы и возможности. Мы видим, как NLP трансформирует отрасли, от маркетинга до медицины;
Распознавание Именованных Сущностей (NER)
NER (Named Entity Recognition) – это задача идентификации и классификации именованных сущностей в тексте, таких как имена людей, организации, местоположения, даты и т.д. Мы активно используем spaCy для быстрого NER, благодаря его высокопроизводительным моделям. Однако, для более сложных сценариев, особенно когда нам нужна высокая точность и возможность работы с редкими сущностями или специфическими доменами, мы обращаемся к библиотекам, таким как Flair, которая предлагает современные подходы к NER, включая использование контекстуальных встраиваний. Также мы исследуем применение CRF (Conditional Random Fields) для распознавания сущностей, особенно в условиях ограниченных данных. Оценка качества NER-моделей (F1-score, Precision, Recall) является для нас критически важной, чтобы убедиться в надежности наших систем.
Анализ Тональности (Sentiment Analysis)
Понимание эмоций, скрытых в тексте, невероятно ценно. Анализ тональности (Sentiment Analysis) позволяет нам определить, является ли отзыв положительным, отрицательным или нейтральным. Мы начинали с простого, но эффективного инструмента – VADER (Valence Aware Dictionary and sEntiment Reasoner), который отлично подходит для анализа сообщений в социальных сетях, учитывая эмодзи и сленг. Мы применяем его для анализа тональности сообщений в социальных сетях (Twitter/Reddit) и анализа тональности отзывов клиентов. Для более сложных задач, таких как анализ тональности финансовых новостей или анализ тональности в социальных медиа с учетом сарказма, мы переходим к моделям, основанным на трансформерах, которые демонстрируют гораздо более глубокое понимание контекста.
Тематическое Моделирование и Извлечение Информации
Как понять, о чем говорят тысячи документов? Тематическое моделирование помогает нам обнаружить скрытые темы в больших коллекциях текстов. Мы активно используем библиотеку Gensim для тематического моделирования (LDA, LSI).
- LDA (Latent Dirichlet Allocation): Позволяет нам определить набор тем, к которым относится каждый документ, и какие слова наиболее характерны для каждой темы.
- LSI (Latent Semantic Indexing): Использует сингулярное разложение для обнаружения скрытых семантических связей между словами и документами.
Мы проводим сравнение моделей тематического моделирования (LDA vs NMF), чтобы выбрать наиболее подходящий подход для конкретной задачи. А для анализа текста для извлечения ключевых фраз мы используем такие алгоритмы, как RAKE (Rapid Automatic Keyword Extraction) и TextRank, которые помогают нам выделить наиболее значимые слова и предложения в тексте. Также мы применяем Topic Modeling для анализа отзывов, чтобы понять, какие аспекты продуктов или услуг чаще всего обсуждаются пользователями.
Суммаризация и Генерация Текста
Когда информации слишком много, нам нужна помощь в ее сжатии. Разработка системы суммаризации текста – это одна из самых востребованных задач. Мы различаем два основных подхода: экстрактивная суммаризация, которая выбирает наиболее важные предложения из исходного текста, и абстрактивная суммаризация, которая генерирует новый текст, передающий суть оригинала. Для экстрактивной суммаризации мы часто используем TextRank для извлечения ключевых предложений. Для абстрактивной же, особенно впечатляющие результаты мы получаем, используя Transformer-модели для суммаризации (например, T5, BART), которые способны создавать связные и грамматически корректные резюме.
В области генерации текста трансформерные модели, такие как GPT (Generative Pre-trained Transformer), открыли совершенно новые горизонты. Мы используем Transformer-модели для генерации текста для создания контента, ответов в чат-ботах и даже для генерации диалогов. Это невероятно мощные инструменты, но требуют тщательного контроля, чтобы избежать нерелевантного или предвзятого контента.
Машинный Перевод и Вопросно-Ответные Системы
Способность преодолевать языковые барьеры всегда была нашей мечтой. Разработка систем машинного перевода на Python с использованием Transformer-моделей для машинного перевода (например, на основе архитектур вроде MarianMT, T5) позволяет нам достигать высокого качества перевода, даже для узкоспециализированных текстов. Мы также экспериментируем с библиотекой Polyglot для мультиязычности и Stanza для языков с богатой морфологией, что особенно актуально для русского языка.
Разработка систем вопросно-ответных систем (QA) – это еще одна захватывающая область. Здесь мы используем предварительно обученные трансформерные модели (например, на основе BERT), которые могут "читать" текст и находить ответы на вопросы, или даже генерировать их. Это позволяет нам создавать интеллектуальные помощники, которые могут быстро извлекать информацию из больших массивов документов, например, для создания FAQ на основе документов.
Продвинутые Приложения и Инструменты
По мере того как мы глубже погружаемся в мир NLP, перед нами открываются все новые и новые горизонты. От анализа огромных объемов данных до создания интеллектуальных чат-ботов – возможности безграничны, и мы постоянно ищем способы расширить наш инструментарий и подходы.
Работа с Большими Данными и Неструктурированным Текстом
В современном мире мы сталкиваемся с огромными объемами текстовых данных, будь то логи, отзывы клиентов или научные статьи. Обработка больших текстовых массивов (Big Data NLP) требует эффективных подходов. Мы используем библиотеку Gensim для анализа больших данных, так как она оптимизирована для работы с крупными корпусами, особенно при обучении Word Embeddings и тематических моделей. Обработка неструктурированного текста: Очистка данных является здесь первостепенной задачей. Часто нам приходится иметь дело с проблемами обработки неполных и ошибочных данных, что требует тщательной предварительной обработки и использования робастных алгоритмов.
Для веб-скрейпинга текста мы активно используем библиотеку Beautiful Soup, которая позволяет нам извлекать текст из HTML-страниц. Также, для извлечения текста из PDF, мы применяем PyMuPDF – мощный инструмент для работы с PDF-документами.
Создание Интеллектуальных Систем
Мы любим создавать интерактивные системы. Разработка чат-ботов на Python, особенно с использованием фреймворка Rasa, позволяет нам строить сложные диалоговые системы, которые могут понимать намерения пользователя и давать релевантные ответы. А для анализа поведенческих паттернов в чатах мы применяем различные методы кластеризации и анализа частотности n-грамм.
В области анализа стилистики текстов (авторский почерк) мы используем методы, которые позволяют нам определять уникальные характеристики написания, что может быть полезно для разработки систем для определения авторства текста или даже для анализа текста для выявления скрытых тем.
Специализированные Приложения
NLP находит применение во многих нишах. Мы работаем над анализом юридических документов, используя Python для извлечения ключевых положений, дат и сторон из контрактов. Это требует точной разметки сущностей и разработки специализированных моделей. Для анализа финансовых новостей мы используем комбинацию анализа тональности и извлечения сущностей, чтобы отслеживать настроения рынка.
Разработка систем обнаружения плагиата – еще одно интересное направление, где мы используем библиотеку Textdistance для измерения сходства строк и документов, а также Doc2Vec для сравнения семантического содержания. А для разработки инструментов для проверки грамматики и орфографии мы опираемся на комбинацию правил и моделей машинного обучения.
Визуализация и Оценка
Чтобы понять данные, их нужно увидеть. Инструменты для визуализации текстовых данных (Word Clouds, Heatmaps) помогают нам быстро оценить частотность слов и распределение тем. А для анализа частотности слов и n-грамм мы часто строим гистограммы и облака слов.
Оценка качества наших моделей – это то, без чего не обходится ни один проект. Мы сравниваем различные методы, будь то сравнение моделей тематического моделирования (LDA vs NMF), сравнение методов лемматизации (SpaCy vs NLTK) или сравнение моделей Word2Vec (Skip-gram vs CBOW). Это позволяет нам постоянно улучшать наши системы и выбирать наиболее эффективные подходы.
- Начните с основ: Освоить NLTK, регулярные выражения и базовую предобработку – это фундамент.
- Изучите векторизацию: Поймите разницу между TF-IDF и Word Embeddings, когда и что использовать.
- Освойте spaCy: Для быстрых и эффективных решений в NER, POS-теггинге и синтаксическом парсинге.
- Погрузитесь в трансформеры: Hugging Face – ваш главный инструмент для работы с самыми современными моделями.
- Практикуйтесь: Лучший способ учиться – это делать. Беритесь за реальные данные и решайте практические задачи.
Мы видим, что мир NLP постоянно эволюционирует, предлагая нам все более совершенные инструменты и подходы. От простых алгоритмов подсчета до сложных нейросетевых архитектур, способных генерировать связный и осмысленный текст, мы прошли огромный путь. Будущее NLP кажется еще более захватывающим, с акцентом на мультимодальные модели (объединяющие текст, изображение, звук), этичность ИИ и разработку систем, способных к настоящему здравому рассуждению.
Наш опыт показывает, что ключевым фактором успеха в этой области является не только знание алгоритмов, но и глубокое понимание лингвистики, а также постоянное обучение и адаптация к новым технологиям. Мы надеемся, что наш рассказ вдохновил вас на собственные эксперименты и открытия в этом удивительном мире. NLP – это не просто набор инструментов, это способ взглянуть на язык и коммуникацию совершенно по-новому, открывая двери для инноваций, которые еще вчера казались невозможными. Мы уверены, что каждый из вас найдет свою нишу в этом бескрайнем и увлекательном поле.
Подробнее
| Основы NLTK | spaCy NER | Gensim LDA | Word2Vec GloVe | Анализ тональности VADER |
| Трансформеры Hugging Face | Классификация текста Scikit-learn | Лемматизация стемминг | Векторизация текста | Разработка чат-ботов Python |





