
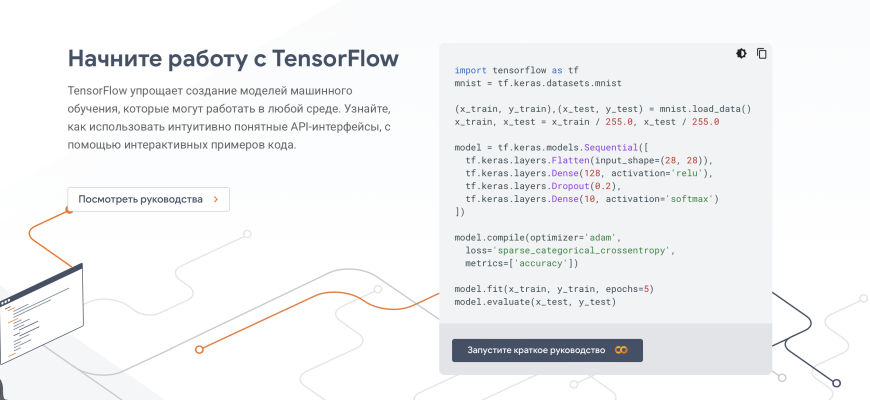
- Разгадываем Язык Цифровой Эпохи: Наш Увлекательный Путь в Мир NLP с Python
- Фундамент: Подготовка Текста к Анализу
- Токенизация и Стемминг: Первые Шаги с NLTK
- Продвинутая Лемматизация и spaCy
- Регулярные Выражения: Ваш Швейцарский Нож для Текста
- Понимание Смысла: Векторизация и Представление Текста
- Разработка Собственных Векторизаторов: CountVectorizer и TfidfVectorizer
- Word Embeddings: Word2Vec и GloVe с Gensim
- Контекстуальные Встраивания: Революция Трансформеров
- Ключевые Задачи NLP: От Слов к Смыслам
- Распознавание Именованных Сущностей (NER) с spaCy и Flair
- Тематическое Моделирование: Генсим и Открытие Скрытых Смыслов
- Анализ Тональности (Sentiment Analysis) с VADER и TextBlob
- Классификация Текстов со Scikit-learn и Нейросетями
- Продвинутые Приложения и Инструменты
- Суммаризация Текста: От Длинных Статей к Ключевым Мыслям
- Разработка Чат-ботов и Вопросно-ответных Систем
- Машинный Перевод и Работа с Многоязычными Данными
- Веб-скрейпинг и Извлечение Текста из Различных Источников
- Оценка, Оптимизация и Будущее NLP
- Оценка Качества Моделей: Метрики и Сравнения
- Работа с Большими Данными и GPU-Ускорением
- Разработка Собственных Инструментов и Перспективы
Разгадываем Язык Цифровой Эпохи: Наш Увлекательный Путь в Мир NLP с Python
Привет, дорогие читатели и коллеги-энтузиасты цифрового мира! Сегодня мы хотим поделиться с вами нашим глубоким погружением в одну из самых захватывающих областей современной информатики – обработку естественного языка, или, как ее называют в кругах специалистов, NLP (Natural Language Processing). Мы, как блогеры, ежедневно сталкиваемся с огромными объемами текста: пишем сами, читаем комментарии, анализируем тренды, и каждый раз понимаем, насколько важно уметь не просто читать, но и понимать, что скрывается за словами. Именно здесь на помощь приходит NLP, открывая для нас совершенно новые горизонты взаимодействия с информацией.
Мы прошли долгий путь от первых экспериментов с простейшими скриптами до создания сложных систем, способных анализировать огромные массивы данных. В этой статье мы хотим провести вас по этому пути, поделиться нашим опытом и показать, как Python, с его богатейшим арсеналом библиотек, становится незаменимым инструментом в мире NLP. Приготовьтесь, ведь мы отправляемся в путешествие, где слова оживают, а машины начинают "понимать" человеческий язык!
Фундамент: Подготовка Текста к Анализу
Прежде чем мы сможем заставить компьютер "читать" и "понимать" текст, нам нужно его как следует подготовить. Представьте, что вы учите маленького ребенка читать: сначала он учится различать буквы, потом складывать их в слова, а затем уже понимать смысл предложений. В NLP процесс очень похож, и начинается он с ряда базовых, но крайне важных шагов. Без них любая, даже самая продвинутая модель, будет работать некорректно.
Токенизация и Стемминг: Первые Шаги с NLTK
Наш первый шаг в подготовке текста – это токенизация. Мы берем большой кусок текста и разбиваем его на более мелкие, осмысленные единицы, которые называются токенами. Чаще всего токенами являются слова или знаки препинания. Например, предложение "Мы любим NLP!" превратится в токены ["Мы", "любим", "NLP", "!"]. Для этой задачи мы часто используем библиотеку NLTK (Natural Language Toolkit), которая предлагает множество эффективных токенизаторов, подходящих для разных языков и сценариев.
После токенизации мы переходим к стеммингу. Его цель – привести слова к их базовой, "корневой" форме, отбросив окончания и суффиксы. Например, слова "бежать", "бежит", "бегущий" могут быть сведены к "беж". Это помогает нам уменьшить размер словаря и рассматривать разные словоформы как одно и то же слово, что упрощает дальнейший анализ. NLTK также предлагает несколько алгоритмов стемминга, таких как PorterStemmer и SnowballStemmer, каждый из которых имеет свои особенности и лучше подходит для определенных языков. Мы обнаружили, что для русского языка часто требуются более продвинутые методы, но для начала стемминг – отличный способ познакомиться с концепцией нормализации текста.
Продвинутая Лемматизация и spaCy
Несмотря на свою полезность, стемминг имеет один существенный недостаток: он часто создает несуществующие слова (например, "красив" из "красивый"). Здесь на помощь приходит лемматизация. В отличие от стемминга, лемматизация приводит слово к его словарной форме (лемме), которая всегда является реальным словом. "Бежать", "бежит", "бегущий" превратятся в "бежать". Для качественной лемматизации нам нужна информация о части речи слова, и здесь мы активно используем библиотеку spaCy.
spaCy – это мощная библиотека для продвинутой обработки естественного языка, которая не только великолепно справляется с лемматизацией, но и предлагает множество других инструментов, о которых мы расскажем позже. Она работает значительно быстрее NLTK для многих задач и имеет готовые предобученные модели для разных языков, включая русский, что делает ее нашим выбором для серьезных проектов. Мы ценим ее за высокую производительность и точность, особенно когда речь идет о сложных задачах, требующих глубокого понимания грамматики.
Регулярные Выражения: Ваш Швейцарский Нож для Текста
Когда мы говорим о предобработке текста, невозможно обойти стороной регулярные выражения (RegEx). Это невероятно мощный инструмент для поиска, замены и извлечения паттернов в тексте. Нужно удалить HTML-теги? Извлечь все email-адреса? Убрать лишние пробелы или знаки препинания? Регулярные выражения справятся с этим в два счета. В Python мы используем встроенный модуль `re`, который предоставляет все необходимые функции.
Вот несколько примеров задач, где мы регулярно применяем RegEx:
- Очистка текста от HTML-тегов: Мы часто парсим веб-страницы, и сырой текст содержит много разметки. RegEx позволяет нам быстро избавиться от всего лишнего.
- Удаление пунктуации и специальных символов: Для многих задач NLP знаки препинания не несут смысловой нагрузки и только мешают.
- Извлечение конкретных сущностей: Если нам нужно найти все даты, номера телефонов или ссылки в тексте, RegEx – наш лучший друг.
- Нормализация текста: Замена нескольких пробелов одним, приведение текста к нижнему регистру – все это легко реализуется с помощью регулярных выражений.
Мы всегда советуем освоить RegEx, поскольку это навык, который пригодится не только в NLP, но и в любом другом проекте, связанном с текстовыми данными. Это как владение магическим заклинанием для управления строками.
Понимание Смысла: Векторизация и Представление Текста
После того как мы очистили и нормализовали текст, возникает следующая задача: как заставить компьютер "понять" его? Машины работают с числами, а не со словами. Поэтому нам нужно преобразовать текст в числовое представление – векторы. Это этап, на котором слова и предложения начинают приобретать математический смысл, позволяя алгоритмам машинного обучения работать с ними.
Разработка Собственных Векторизаторов: CountVectorizer и TfidfVectorizer
Начальные методы векторизации довольно просты, но эффективны. Один из них – CountVectorizer из библиотеки Scikit-learn. Он просто подсчитывает частоту вхождения каждого слова в документе. В результате каждый документ представляется вектором, где каждая позиция соответствует слову из всего корпуса текстов, а значение – его частоте. Это просто и интуитивно понятно, но имеет свои ограничения: слова, которые часто встречаются во всех документах (например, "и", "в", "на"), могут искажать результаты, так как они не несут уникальной информации.
Чтобы решить эту проблему, мы используем TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает частоту слова в документе (TF), но и его редкость во всем корпусе документов (IDF). Таким образом, словам, которые часто встречаются в одном документе, но редко в других, придается больший вес. Это позволяет нам выделить наиболее "значимые" слова для каждого документа, что значительно улучшает качество последующего анализа, будь то классификация или кластеризация.
Пример векторов слов:
| Слово | CountVectorizer (документ 1) | TF-IDF (документ 1) |
|---|---|---|
| NLP | 3 | 0.75 |
| статья | 1 | 0.23 |
| и | 5 | 0.01 |
Мы видим, как TF-IDF придает меньший вес частому, но малоинформативному слову "и".
Word Embeddings: Word2Vec и GloVe с Gensim
CountVectorizer и TF-IDF хороши, но они не учитывают семантическую связь между словами. То есть, слова "король" и "царь" для них так же далеки, как "король" и "банан". Здесь в игру вступают Word Embeddings – векторные представления слов, которые улавливают их смысловые отношения. Наиболее известные из них – Word2Vec и GloVe.
Мы используем библиотеку Gensim для работы с Word2Vec. Суть Word2Vec заключается в том, что слова, которые часто появляются в схожих контекстах, будут иметь схожие векторные представления. Это означает, что вектор "король" будет "ближе" к вектору "царь", чем к "банан". Более того, эти векторы позволяют выполнять интересные операции, например, "король" ― "мужчина" + "женщина" ≈ "королева". Это открывает огромные возможности для понимания нюансов языка. GloVe (Global Vectors for Word Representation) работает на схожих принципах, но использует немного другую статистическую модель для построения векторов. Мы часто экспериментируем с обоими, чтобы найти оптимальное решение для конкретной задачи.
Контекстуальные Встраивания: Революция Трансформеров
Word Embeddings были прорывом, но у них был один недостаток: одно и то же слово всегда имело один и тот же вектор, независимо от контекста. Но ведь слово "коса" может означать и прическу, и сельскохозяйственный инструмент! Здесь на сцену вышли Трансформеры и их контекстуальные встраивания (contextual embeddings), такие как BERT, GPT, RoBERTa.
Мы активно используем библиотеку Hugging Face Transformers, которая предоставляет доступ к огромному количеству предобученных моделей. Эти модели способны генерировать разные векторные представления для одного и того же слова в зависимости от окружающего его контекста. Это стало настоящей революцией в NLP, позволив достичь беспрецедентной точности в таких задачах, как распознавание именованных сущностей, вопросно-ответные системы и машинный перевод. Работа с трансформерами требует больше вычислительных ресурсов, но результаты того стоят. Мы видим, как они меняют наше представление о возможностях машинного понимания языка.
Ключевые Задачи NLP: От Слов к Смыслам
Теперь, когда мы научились готовить текст и представлять его в числовом виде, настало время перейти к решению конкретных задач. Именно здесь NLP показывает свою истинную силу, позволяя нам извлекать ценную информацию, классифицировать документы, понимать настроения и даже генерировать новые тексты.
Распознавание Именованных Сущностей (NER) с spaCy и Flair
Одна из самых полезных задач в NLP – это Распознавание Именованных Сущностей (Named Entity Recognition, NER). Нам часто нужно автоматически находить в тексте имена людей, названия организаций, географические объекты, даты и другие важные сущности. Представьте, как это упрощает анализ новостей или юридических документов!
Для быстрого и точного NER мы активно используем spaCy. Его предобученные модели отлично справляются с этой задачей, позволяя нам мгновенно извлекать нужную информацию. Мы также экспериментируем с библиотекой Flair, которая предлагает state-of-the-art модели, основанные на рекуррентных нейронных сетях и трансформерах, часто дающие еще более высокую точность, особенно для языков с богатой морфологией.
Тематическое Моделирование: Генсим и Открытие Скрытых Смыслов
Иногда нам нужно не просто извлечь факты, а понять, о чем в целом идет речь в большом корпусе документов. Здесь на помощь приходит тематическое моделирование. Это класс алгоритмов, которые позволяют автоматически обнаружить абстрактные "темы", присутствующие в коллекции документов. Каждый документ может быть представлен как смесь этих тем, а каждая тема – как набор наиболее часто встречающихся в ней слов.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
— Рита Мэй Браун
Для тематического моделирования мы часто используем библиотеку Gensim. Она предоставляет эффективные реализации алгоритмов, таких как LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing). С их помощью мы можем проанализировать тысячи отзывов клиентов, чтобы выявить основные проблемы или пожелания, или же просканировать новостные статьи, чтобы понять, какие темы доминируют в медиапространстве. Это мощный инструмент для работы с неструктурированным текстом и извлечения из него высокоуровневых инсайтов. Мы также сравниваем LDA с NMF (Non-negative Matrix Factorization), чтобы выбрать наиболее подходящий метод для конкретного датасета.
Анализ Тональности (Sentiment Analysis) с VADER и TextBlob
Понимание эмоциональной окраски текста – бесценный навык для блогера. Положительные или отрицательные отзывы? Разочарование или восторг? Анализ тональности позволяет нам это выяснить. Для быстрого и эффективного анализа тональности англоязычных текстов мы часто используем библиотеку VADER (Valence Aware Dictionary and sEntiment Reasoner). Она основана на словаре, учитывающем не только слова, но и их контекст (например, "очень хорошо" будет иметь более сильный положительный тон, чем просто "хорошо").
Для более простых случаев, а также для экспериментов с другими языками, мы обращаемся к TextBlob. Это удобная библиотека, которая предоставляет простой API для выполнения общих задач NLP, включая анализ тональности. Однако, для русского языка VADER не подходит, и мы либо создаем собственные словари тональности, либо используем предобученные модели машинного обучения или трансформеры, специально адаптированные для русского языка. Анализ тональности сообщений в социальных сетях, особенно с учетом сарказма и сленга, представляет собой отдельный вызов, и мы постоянно ищем новые подходы для его решения.
Классификация Текстов со Scikit-learn и Нейросетями
Классификация текстов – это задача отнесения документа к одной или нескольким предопределенным категориям. Например, определение того, является ли email спамом, или к какой категории относится новостная статья (спорт, политика, экономика). Мы регулярно используем Scikit-learn, библиотеку машинного обучения, для решения задач классификации. С ее помощью мы можем применять такие алгоритмы, как SVM (Support Vector Machines), Наивный Байесовский классификатор, Логистическая регрессия и другие, используя в качестве признаков наши TF-IDF векторы или Word Embeddings.
Для более сложных задач и достижения state-of-the-art результатов мы переходим к нейронным сетям, используя фреймворки PyTorch или TensorFlow. LSTM-сети (Long Short-Term Memory) и, конечно же, трансформерные архитектуры (например, BERT для задач классификации) позволяют нам улавливать более глубокие зависимости в тексте и получать более точные предсказания. Тонкая настройка (Fine-tuning) предварительно обученных трансформерных моделей стала нашим основным подходом для достижения наилучших результатов в классификации.
Продвинутые Приложения и Инструменты
Мир NLP не ограничивается только базовыми задачами. Существует множество более сложных и увлекательных приложений, которые позволяют автоматизировать рутинные процессы, создавать интеллектуальные системы и извлекать по-настоящему глубокие инсайты из текстовых данных.
Суммаризация Текста: От Длинных Статей к Ключевым Мыслям
Как блогеры, мы часто сталкиваемся с необходимостью быстро понять суть длинной статьи или отчета. Суммаризация текста – это процесс автоматического создания краткого изложения документа, сохраняющего его основные идеи. Существует два основных подхода:
- Экстрактивная суммаризация: Мы извлекаем наиболее важные предложения из исходного текста и объединяем их в краткое изложение. Здесь часто используются методы на основе графов, такие как TextRank, который оценивает важность предложений по их связи с другими предложениями.
- Абстрактивная суммаризация: Это более сложный подход, при котором система генерирует совершенно новые предложения, перефразируя исходный текст. Это требует глубокого понимания семантики и часто реализуется с помощью трансформерных моделей (например, BART, T5 из Hugging Face), которые способны генерировать связный и осмысленный текст.
Мы видим огромный потенциал в абстрактивной суммаризации для быстрого создания анонсов статей или кратких обзоров.
Разработка Чат-ботов и Вопросно-ответных Систем
Чат-боты и вопросно-ответные системы (QA) становятся неотъемлемой частью современного цифрового пространства. Мы экспериментировали с разработкой простых чат-ботов на Python, используя фреймворки вроде Rasa. Это позволяет нам создавать интерактивные диалоговые агенты, способные понимать намерения пользователя, извлекать сущности и генерировать адекватные ответы.
Для более сложных QA систем, которые могут отвечать на вопросы на основе большого набора документов, мы обращаемся к трансформерным моделям. Они способны находить точные ответы в тексте, даже если вопрос сформулирован иначе, чем информация в документе. Это открывает возможности для создания интеллектуальных помощников, способных быстро находить информацию в базах знаний или юридических документах.
Машинный Перевод и Работа с Многоязычными Данными
Интернет глобален, и часто нам приходится работать с текстами на разных языках. Машинный перевод, который еще недавно казался фантастикой, теперь стал реальностью благодаря достижениям в области NLP. Мы используем трансформерные модели из Hugging Face для создания систем машинного перевода, способных переводить тексты с высокой точностью.
Кроме того, для обработки многоязычных текстовых корпусов и анализа редких языков мы используем такие библиотеки, как Polyglot и Stanza. Polyglot предоставляет доступ к широкому спектру функций NLP для десятков языков, а Stanza, разработанная в Стэнфорде, особенно хороша для языков с богатой морфологией, предлагая высокоточные модели для токенизации, POS-теггинга и анализа зависимостей.
Веб-скрейпинг и Извлечение Текста из Различных Источников
Прежде чем мы сможем анализировать текст, нам нужно его откуда-то получить. Часто это означает извлечение данных с веб-сайтов – веб-скрейпинг. Для этой задачи мы активно используем библиотеку Beautiful Soup в Python. Она позволяет нам парсить HTML- и XML-документы, извлекать нужные блоки текста, заголовки, ссылки и другую информацию. Без Beautiful Soup наша работа по сбору данных для анализа была бы гораздо сложнее.
Помимо веб-страниц, текст может храниться в различных форматах, например, в PDF-файлах. Для извлечения текста из PDF-документов мы используем библиотеку PyMuPDF. Это особенно полезно при работе с отчетами, научными статьями или юридическими документами, которые часто распространяются именно в этом формате.
Оценка, Оптимизация и Будущее NLP
Как и в любой области машинного обучения, в NLP крайне важно уметь оценивать качество наших моделей и постоянно их улучшать. Мы сталкиваемся с проблемами обработки неполных и ошибочных данных, а также с необходимостью тонкой настройки алгоритмов для достижения оптимальных результатов.
Оценка Качества Моделей: Метрики и Сравнения
Для оценки качества наших моделей мы используем различные метрики. Например, для NER-моделей мы смотрим на F1-score, Precision и Recall. Precision показывает, какая доля найденных сущностей является корректной, Recall – какую долю всех сущностей модель смогла найти, а F1-score – это гармоническое среднее между Precision и Recall, дающее общую оценку.
Мы постоянно сравниваем различные подходы и библиотеки. Например, сравниваем эффективность различных токенизаторов, методов лемматизации (spaCy vs NLTK), моделей тематического моделирования (LDA vs NMF) или методов векторизации (TF-IDF vs Word2Vec). Это позволяет нам выбирать наиболее подходящие инструменты для конкретной задачи и достигать наилучших результатов.
Работа с Большими Данными и GPU-Ускорением
Объемы текстовых данных растут экспоненциально, и обработка больших текстовых массивов (Big Data NLP) становится все более актуальной. Для этого мы оптимизируем наши пайплайны, используем параллельные вычисления и, конечно же, активно применяем GPU-ускорение. Современные библиотеки, такие как PyTorch и TensorFlow, позволяют эффективно использовать графические процессоры для обучения сложных нейросетей и обработки огромных объемов данных, значительно сокращая время вычислений.
Мы также экспериментируем с анализом временных рядов в текстовых данных, например, чтобы выявлять сезонность в отзывах о продуктах или отслеживать динамику упоминаний определенных тем в новостях.
Разработка Собственных Инструментов и Перспективы
Иногда существующих библиотек недостаточно, и мы приступаем к разработке собственных инструментов. Это может быть инструмент для автоматической разметки данных, для проверки грамматики, для создания словарей терминов или тезаурусов, или даже для нормализации сленга в социальных сетях. Каждая новая задача – это новый вызов и возможность для творчества.
Будущее NLP выглядит невероятно захватывающим. С появлением все более мощных трансформерных моделей, способных генерировать связный и осмысленный текст (например, GPT), мы стоим на пороге новой эры взаимодействия человека с машиной. Мы видим, как NLP проникает во все сферы нашей жизни, от умных помощников и персональных рекомендаций до анализа финансовых рынков и юридических документов. И мы гордимся тем, что являемся частью этого удивительного процесса.
Итак, мы провели вас по нашему пути в мир обработки естественного языка с Python. Мы начали с основ – токенизации и стемминга, перешли к мощной лемматизации с spaCy и гибким регулярным выражениям. Затем мы погрузились в мир векторизации текста, от классических TF-IDF до семантически богатых Word Embeddings и революционных контекстуальных встраиваний от трансформеров.
Мы исследовали ключевые задачи NLP: распознавание сущностей, тематическое моделирование, анализ тональности и классификацию текстов, используя библиотеки вроде NLTK, spaCy, Gensim и Scikit-learn, а также мощь нейронных сетей и трансформеров. И, наконец, мы прикоснулись к продвинутым приложениям, таким как суммаризация текста, разработка чат-ботов, машинный перевод и веб-скрейпинг, обсудили вопросы оценки и оптимизации.
Наш опыт показывает, что Python – это не просто язык программирования, а целый космос возможностей для работы с текстом. Каждая библиотека, каждый алгоритм открывает новые двери, позволяя нам не просто обрабатывать информацию, но и по-настоящему "понимать" ее. Мы надеемся, что наш рассказ вдохновит вас на собственные эксперименты и открытия в этом удивительном и постоянно развивающемся мире. Удачи в ваших NLP-проектах, и помните: язык – это ключ ко всему! На этом статья заканчивается.
Подробнее: Полезные LSI Запросы
| Основы NLTK | NER с spaCy | Тематическое моделирование Gensim | Анализ тональности VADER | Word Embeddings |
| Трансформеры Hugging Face | Разработка чат-ботов | Обработка Big Data NLP | Суммаризация текста | Анализ юридических документов |





