
- Разгадываем Язык Вселенной: Наш Путь в Мире Обработки Естественного Языка на Python
- Первые Шаги в Мир Текста: Основы NLP и Подготовка Данных
- Токенизация, Стемминг и Лемматизация: Разбираем Слова по Косточкам
- Регулярные Выражения (re) и Очистка Данных: Наводим Порядок
- TextBlob для Простого NLP: Быстрый Старт
- Извлечение Смысла: Сущности, Темы и Ключевые Фразы
- Распознавание Именованных Сущностей (NER) с spaCy и Flair
- Тематическое Моделирование (LDA, LSI) с Gensim
- Извлечение Ключевых Фраз: Суть в Нескольких Словах
- Векторы Слов и Контекста: Глубокое Понимание Текста
- Word Embeddings: Word2Vec, GloVe и Doc2Vec
- Разработка Собственных Векторизаторов Текста: CountVectorizer и TfidfVectorizer
- Контекстное Встраивание и Sentence Transformers: Новый Уровень Понимания
- Анализ Эмоций и Стилистики: За Гранью Слов
- Анализ Тональности (Sentiment Analysis) с VADER и TextBlob
- Работа с Эмодзи и Сленгом в Современных Текстах
- Определение Авторства и Стилистики Текстов
- Современный NLP: Трансформеры и Нейросети
- Архитектуры Трансформеров (Hugging Face, BERT, GPT)
- Применение PyTorch/TensorFlow для Создания Нейросетей NLP
- Тонкая Настройка (Fine-tuning) Предварительно Обученных Моделей
- Прикладные Задачи NLP: От Чат-ботов до Перевода
- Разработка Чат-ботов и Вопросно-ответных Систем (QA)
- Суммаризация Текста: Извлечение Сути
- Машинный Перевод и Работа с Многоязычными Корпусами
- Анализ Юридических, Медицинских и Финансовых Документов
- Работа с Данными: Очистка, Разметка и Визуализация
- Веб-скрейпинг и Извлечение Текста из Различных Форматов
- Обработка Неполных и Ошибочных Данных, Автоматическая Разметка
- Инструменты для Визуализации Текстовых Данных
Разгадываем Язык Вселенной: Наш Путь в Мире Обработки Естественного Языка на Python
Приветствуем, дорогие читатели и коллеги-энтузиасты больших данных! Сегодня мы отправляемся в увлекательное путешествие по миру, где машины учатся понимать наш человеческий язык․ Это не просто набор алгоритмов и библиотек; это целая философия, позволяющая раскрыть скрытые смыслы в огромных массивах текста, будь то твиты, научные статьи, юридические контракты или отзывы клиентов․ Мы, как блогеры, которые не понаслышке знакомы с мощью Python в этой сфере, готовы поделиться нашим опытом и показать, как можно превратить беспорядочный текст в ценные инсайты․
Наш мир переполнен текстом․ С каждым днем генерируются терабайты новой информации: электронные письма, сообщения в чатах, публикации в социальных сетях, новостные ленты, научные доклады․ Представьте, сколько всего мы могли бы узнать, если бы могли быстро и эффективно анализировать все эти данные! Именно здесь на сцену выходит Обработка Естественного Языка (NLP) — область искусственного интеллекта, которая дает компьютерам возможность читать, понимать и интерпретировать человеческий язык․ В этой статье мы шаг за шагом проведем вас по основным концепциям и самым мощным инструментам Python, которые мы используем в нашей повседневной работе, чтобы вы тоже могли начать разгадывать "язык вселенной"․
Первые Шаги в Мир Текста: Основы NLP и Подготовка Данных
Прежде чем мы сможем научить машину "читать", нам нужно подготовить текст․ Представьте, что вы учите ребенка читать: сначала он должен выучить буквы, затем слова, и только потом предложения․ В NLP процесс похож: мы разбиваем текст на более мелкие, осмысленные единицы и приводим их к стандартной форме․ Это критически важный этап, который определяет качество всего последующего анализа․ Без правильной предобработки даже самые продвинутые модели могут дать неверные результаты․
Мы начинаем с самых азов, которые, несмотря на свою простоту, формируют фундамент для всех более сложных задач․ На этом этапе мы учимся "разбирать" текст, очищать его от шума и приводить к виду, удобному для машинной обработки․ Это как подготовка ингредиентов перед приготовлением сложного блюда: каждый шаг важен для конечного результата․
Токенизация, Стемминг и Лемматизация: Разбираем Слова по Косточкам
Самый первый шаг в обработке текста — это токенизация․ Мы разбиваем непрерывный текст на отдельные слова или фразы, которые называются токенами․ Например, предложение "Мы любим NLP!" превращается в токены ["Мы", "любим", "NLP", "!"]․ Для этого мы часто используем мощную библиотеку NLTK (Natural Language Toolkit), которая предлагает множество токенизаторов для разных языков и задач․ NLTK — это наш верный спутник в мире базового NLP, предлагающий все от токенизаторов до средств для морфологического анализа․
Далее идет стемминг — процесс удаления окончаний слов, чтобы привести их к общей корневой форме, или "основе" (stem)․ Например, слова "бежать", "бегущий", "бегал" могут быть сведены к "беж"․ Это полезно для уменьшения словаря и анализа общих понятий․ Однако стемминг может быть довольно агрессивным и часто создает несуществующие слова․ Например, "красивый" и "красота" могут быть сведены к одному корню, но их значения немного разные․
Здесь на помощь приходит лемматизация, которая является более продвинутой и точной альтернативой стеммингу․ Лемматизация приводит слова к их словарной (базовой) форме, называемой леммой, с учетом контекста и части речи․ Так, "бегущий", "бегал", "бежать" все будут приведены к "бежать", а "красивый" и "красота" останутся разными леммами, поскольку это разные части речи и имеют разные словарные значения․ Для продвинутой лемматизации мы часто используем spaCy или Stanza, особенно когда работаем с языками, обладающими богатой морфологией, такими как русский․ Эти библиотеки не только лемматизируют, но и выполняют синтаксический парсинг, давая нам более глубокое понимание структуры предложения․
Регулярные Выражения (re) и Очистка Данных: Наводим Порядок
Реальный текст редко бывает чистым․ Он может содержать HTML-теги, специальные символы, ссылки, числа, эмодзи и опечатки․ Чтобы наши модели не "отвлекались" на этот шум, мы проводим тщательную очистку данных․ Здесь незаменимыми становятся регулярные выражения (re) в Python․ С их помощью мы можем:
- Удалять HTML-теги, ссылки и другие нетекстовые элементы․
- Приводить текст к нижнему регистру для унификации․
- Удалять пунктуацию или заменять ее пробелами․
- Обрабатывать эмодзи и сленг, которые встречаются в современных текстах, особенно в социальных сетях․
- Удалять стоп-слова (часто встречающиеся слова вроде "и", "в", "на", которые не несут смысловой нагрузки для многих задач)․
Мы также часто сталкиваемся с неполными и ошибочными данными․ Разработка инструментов для проверки грамматики и исправления орфографии становится важной частью предобработки, особенно когда мы работаем с пользовательским контентом․
TextBlob для Простого NLP: Быстрый Старт
Для более простых задач, когда нам нужен быстрый и легкий анализ, мы часто обращаемся к библиотеке TextBlob․ Она построена на основе NLTK, но предлагает более интуитивный API․ TextBlob позволяет нам:
- Выполнять токенизацию․
- Проводить POS-теггинг (определение частей речи)․
- Выполнять базовый анализ тональности․
- Определять язык текста․
- Исправлять орфографические ошибки․
TextBlob отлично подходит для прототипирования и небольших проектов, где нет необходимости в глубокой кастомизации или высокопроизводительных решениях․ Однако для более сложных задач и работы с большими объемами данных мы переходим к более мощным инструментам, о которых поговорим далее․
Извлечение Смысла: Сущности, Темы и Ключевые Фразы
После того как текст очищен и разбит на токены, мы можем начать извлекать из него более глубокий смысл․ Это как после изучения отдельных слов мы учимся понимать, о ком или о чем идет речь в предложении, и какую общую тему оно затрагивает․ На этом этапе мы переходим от "букв и слов" к "идеям и концепциям"․
Распознавание Именованных Сущностей (NER) с spaCy и Flair
Одной из самых мощных техник является Распознавание Именованных Сущностей (NER)․ NER позволяет нам автоматически находить и классифицировать именованные сущности в тексте, такие как имена людей, названия организаций, географические местоположения, даты и другие важные данные․ Представьте, насколько это полезно для анализа новостей, юридических документов или медицинских записей!
Для быстрого и эффективного NER мы активно используем spaCy․ Эта библиотека известна своей скоростью и превосходными предварительно обученными моделями для различных языков․ Она не только находит сущности, но и позволяет нам легко получить доступ к их типам и позициям в тексте․
import spacy
nlp = spacy․load("en_core_web_sm")
text = "Apple купила стартап по ИИ за 200 миллионов долларов в Лондоне․"
doc = nlp(text)
for ent in doc․ents:
print(f"Сущность: {ent․text}, Тип: {ent․label_}")
Сущность: Apple, Тип: ORG
Сущность: 200 миллионов долларов, Тип: MONEY
Сущность: Лондоне, Тип: GPE
Для более сложных задач NER, особенно когда требуется высокая точность или работа с языками с богатой морфологией, мы обращаемся к библиотеке Flair․ Flair предлагает state-of-the-art модели для NER, построенные на основе контекстных встраиваний, что позволяет ей показывать выдающиеся результаты․ Она также отлично подходит для работы с многоязычными текстовыми корпусами․
Тематическое Моделирование (LDA, LSI) с Gensim
Когда у нас есть большой объем текста, например, тысячи отзывов или статей, ручной анализ тем становится невозможным․ Здесь на помощь приходит тематическое моделирование, набор алгоритмов, которые позволяют нам автоматически обнаруживать скрытые "темы" в коллекции документов․
Мы часто используем библиотеку Gensim для тематического моделирования․ Gensim — это высокоэффективная библиотека для обработки больших текстовых массивов, и она реализует несколько популярных алгоритмов:
- LDA (Latent Dirichlet Allocation): Один из самых популярных алгоритмов․ Он предполагает, что каждый документ представляет собой смесь нескольких тем, а каждая тема — это смесь слов․
- LSI (Latent Semantic Indexing): Использует сингулярное разложение для выявления скрытых семантических структур в тексте․
- NMF (Non-negative Matrix Factorization): Другой мощный метод для обнаружения скрытых тем, который хорошо работает с разреженными данными․
Выбор между LDA и NMF часто зависит от характера данных и конкретной задачи, но оба метода позволяют нам выявить основные идеи, циркулирующие в текстовом корпусе․ Мы часто сравниваем эти модели, чтобы выбрать ту, которая дает наиболее интерпретируемые и полезные результаты для нашего проекта․
| Характеристика | LDA (Latent Dirichlet Allocation) | NMF (Non-negative Matrix Factorization) |
|---|---|---|
| Математическая основа | Вероятностная модель, основанная на распределении Дирихле․ | Алгебраический метод разложения матриц․ |
| Интерпретируемость тем | Темы легко интерпретируются как наборы слов․ | Темы часто более "разреженные", но также хорошо интерпретируемы․ |
| Работа с короткими текстами | Может испытывать трудности с очень короткими текстами․ | Часто показывает хорошие результаты даже на коротких текстах․ |
| Предположения | Предполагает, что слова в документе генерируются из тем․ | Не имеет сильных предположений о процессе генерации данных․ |
Извлечение Ключевых Фраз: Суть в Нескольких Словах
Помимо общих тем, часто нам нужно извлечь наиболее важные слова или фразы, которые наилучшим образом описывают содержание документа․ Это называется извлечением ключевых фраз․
Мы используем несколько подходов:
- RAKE (Rapid Automatic Keyword Extraction): Простой, но эффективный алгоритм, который определяет ключевые фразы на основе частотности слов и их co-occurrence․
- TextRank: Алгоритм, основанный на PageRank (используется Google для ранжирования веб-страниц), который ранжирует слова или предложения в тексте на основе их связей, чтобы выявить наиболее важные․ TextRank отлично подходит как для извлечения ключевых фраз, так и для суммаризации текста․
- TF-IDF (Term Frequency-Inverse Document Frequency): Хотя это метод векторизации, о котором мы поговорим позже, он также может быть использован для выявления слов, которые являются важными для конкретного документа в рамках всего корпуса․
Эти методы позволяют нам быстро понять суть большого документа, что особенно ценно при анализе текстов из блогов и форумов, или для автоматического тегирования контента․
Векторы Слов и Контекста: Глубокое Понимание Текста
Как машины могут "понимать" слова, если они работают только с числами? Ответ кроется в векторизации текста — процессе преобразования слов, фраз или даже целых документов в числовые векторы․ Эти векторы представляют собой математическое воплощение значения слова, где слова с похожим значением имеют похожие векторы․ Это открывает дверь к использованию мощных алгоритмов машинного обучения․
Word Embeddings: Word2Vec, GloVe и Doc2Vec
Настоящая революция в понимании семантики слов произошла с появлением Word Embeddings (векторных представлений слов)․ Это плотные векторы, которые улавливают контекстуальные и семантические отношения между словами․
- Word2Vec: Разработанный Google, Word2Vec позволяет нам обучать модели, которые предсказывают слово на основе его контекста (CBOW) или предсказывают контекст на основе слова (Skip-gram)․ Это позволяет словам "король" и "королева" быть похожими, а "король" ⎻ "мужчина" + "женщина" = "королева" становится возможным с помощью векторной арифметики․
- GloVe (Global Vectors for Word Representation): Другой популярный метод, который сочетает в себе преимущества глобальной матричной факторизации и локальных окон контекста․
- Doc2Vec: Расширение Word2Vec, которое позволяет создавать векторные представления не только для слов, но и для целых документов․ Это невероятно полезно для сравнения документов, поиска похожих статей или автоматической категоризации․
Мы активно используем библиотеку Gensim для работы с Word2Vec и Doc2Vec, так как она предоставляет эффективные реализации этих алгоритмов и позволяет легко обучать собственные модели на больших корпусах текста․
Разработка Собственных Векторизаторов Текста: CountVectorizer и TfidfVectorizer
Помимо предварительно обученных встраиваний, мы часто создаем собственные векторизаторы, особенно для задач, где важна частотность слов в конкретном корпусе:
- CountVectorizer: Создает матрицу, где каждая строка представляет документ, а каждый столбец — уникальное слово в корпусе․ Значение в ячейке — это количество раз, когда слово встречается в документе․ Простой, но эффективный для многих задач классификации․
- TfidfVectorizer (Term Frequency-Inverse Document Frequency): Более продвинутый векторизатор, который не просто считает частотность, но и взвешивает ее по "обратной частотности документа"․ То есть, слова, которые часто встречаются во многих документах (например, стоп-слова), получают меньший вес, а слова, которые уникальны для конкретного документа, получают больший вес․ Это помогает выделить действительно важные слова․
Эти векторизаторы из Scikit-learn являются основой для многих наших проектов по классификации текстов и тематическому моделированию․ Мы также исследуем применение FastText для работы с редкими словами, поскольку он способен создавать векторы для слов, не встречавшихся в обучающем корпусе, путем анализа их суб-словных единиц․
Контекстное Встраивание и Sentence Transformers: Новый Уровень Понимания
Современные достижения в NLP привели к появлению контекстного встраивания, где векторное представление слова зависит от его контекста в предложении․ Это значительно улучшило понимание нюансов языка․
Здесь на сцену выходят Sentence Transformers․ Они позволяют нам получать высококачественные векторные представления не только для отдельных слов, но и для целых предложений и даже документов, учитывая их контекст․ Это особенно полезно для задач, таких как:
- Поиск семантически похожих предложений․
- Кластеризация текстов․
- Оценка сходства документов (с использованием библиотеки Textdistance)․
Эти модели, часто построенные на архитектуре трансформеров, являются краеугольным камнем современного NLP и позволяют нам достигать невероятной точности в задачах, где раньше требовались сложные ручные правила․
"Язык — это лишь инструмент для формулирования идей, а не сама идея․ Он может быть ясен, может быть туманен, но главное — это мысль, которую он выражает․"
— Людвиг Витгенштейн
Анализ Эмоций и Стилистики: За Гранью Слов
Текст — это не просто набор слов; это отражение человеческих эмоций, мнений и даже личности автора․ Наша работа часто включает в себя попытки понять эти неявные аспекты, что открывает совершенно новые возможности для бизнеса и исследований․
Анализ Тональности (Sentiment Analysis) с VADER и TextBlob
Анализ тональности, или сентимент-анализ, — это процесс определения эмоциональной окраски текста: является ли он позитивным, негативным или нейтральным․ Это чрезвычайно ценно для анализа отзывов клиентов, сообщений в социальных сетях (Twitter, Reddit) и финансовых новостей․
Мы используем различные подходы:
- VADER (Valence Aware Dictionary and sEntiment Reasoner): Специально разработан для анализа тональности в социальных сетях, так как хорошо обрабатывает сленг, эмодзи и акронимы․ Он выдает не только общую полярность, но и степень позитивности/негативности/нейтральности․
- TextBlob: Как мы уже упоминали, TextBlob предоставляет простой метод для быстрого анализа тональности, который подходит для многих базовых задач․
- Машинное обучение: Для более сложных и специфичных задач мы обучаем собственные модели классификации текстов (например, с использованием Scikit-learn, PyTorch или TensorFlow), которые могут учитывать специфику нашей предметной области․ Это особенно важно для анализа тональности с учетом сарказма или контекста․
Анализ тональности отзывов о продуктах по категориям или сообщений в социальных сетях помогает нам понять общественное мнение и выявить тенденции․
Работа с Эмодзи и Сленгом в Современных Текстах
Современные тексты, особенно в интернете, изобилуют эмодзи, сленгом, сокращениями и специфической лексикой․ Простое удаление этих элементов может привести к потере важной информации․ Мы разработали инструменты для нормализации сленга и учитываем эмодзи как дополнительные маркеры тональности или эмоций․ Это требует более тонкого подхода к предобработке и часто использования специализированных словарей․
Определение Авторства и Стилистики Текстов
Иногда нам нужно пойти дальше простой семантики и понять уникальный "почерк" автора․ Анализ стилистики текстов и определение авторства — это задачи, которые позволяют нам идентифицировать автора на основе его лексического богатства, частотности использования определенных слов, длины предложений, пунктуации и других стилистических особенностей․ Это может быть полезно в криминалистике, литературоведении или для анализа поведенческих паттернов в чатах․ Мы используем статистические методы и методы машинного обучения для этих целей, анализируя такие метрики, как частотность n-грамм, уникальных слов и другие показатели․
Современный NLP: Трансформеры и Нейросети
Последние несколько лет стали свидетелями революции в NLP благодаря появлению архитектур трансформеров и глубоких нейронных сетей․ Эти модели перевернули наше представление о том, что возможно в обработке языка, достигнув беспрецедентной точности в самых разных задачах․
Архитектуры Трансформеров (Hugging Face, BERT, GPT)
Модели, основанные на архитектуре трансформеров, такие как BERT (Bidirectional Encoder Representations from Transformers) и GPT (Generative Pre-trained Transformer), стали стандартом де-факто в современном NLP․ Их ключевая особенность — механизм внимания (attention mechanism), который позволяет модели взвешивать важность различных частей входной последовательности при обработке каждого элемента․
Мы активно используем библиотеку Hugging Face Transformers, которая предоставляет доступ к сотням предварительно обученных моделей для различных языков и задач․ С ее помощью мы можем:
- Использовать BERT для задач классификации, NER и вопросно-ответных систем․
- Применять GPT-модели для генерации текста, диалогов и даже кода․
- Использовать Transformer-модели для суммаризации и машинного перевода․
Эти модели способны улавливать сложные контекстуальные зависимости и семантические нюансы, что делает их незаменимыми для сложных задач NLP․
Применение PyTorch/TensorFlow для Создания Нейросетей NLP
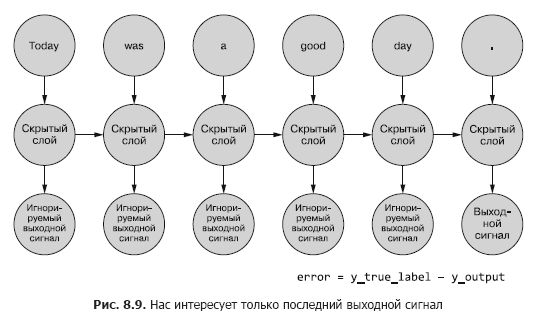
Хотя Hugging Face предоставляет высокоуровневый API, для более глубокой кастомизации и экспериментальных исследований мы часто обращаемся к фреймворкам глубокого обучения, таким как PyTorch и TensorFlow (с Keras)․ Мы используем их для создания собственных нейросетевых архитектур, включая LSTM-сети (Long Short-Term Memory), которые были популярны до трансформеров для задач, связанных с последовательностями․
Создание нейросетей позволяет нам:
- Реализовывать собственные архитектуры для специфических задач․
- Тонко настраивать предварительно обученные модели (fine-tuning) на наших данных, чтобы достичь максимальной производительности․
- Экспериментировать с новыми идеями в области NLP, например, с графовыми встраиваниями (Graph Embeddings) для анализа взаимосвязей в тексте․
Работа с PyTorch и TensorFlow также позволяет нам использовать GPU-ускорение для обработки больших текстовых массивов, что значительно сокращает время обучения моделей․
Тонкая Настройка (Fine-tuning) Предварительно Обученных Моделей
Одним из самых мощных аспектов трансформерных моделей является возможность их тонкой настройки (fine-tuning)․ Мы берем предварительно обученную модель (например, BERT, обученную на огромном корпусе текста), а затем "дообучаем" ее на небольшом, специфичном для нашей задачи наборе данных․ Это позволяет модели адаптироваться к особенностям нашей предметной области и достигать высокой точности даже с относительно небольшим количеством размеченных данных․
| Характеристика | Традиционное ML (SVM, Наивный Байес) | Трансформеры (BERT, GPT) |
|---|---|---|
| Требования к данным | Требуют большого количества размеченных данных для обучения с нуля․ | Могут быть тонко настроены на небольшом объеме данных после предварительного обучения․ |
| Понимание контекста | Ограниченное понимание контекста, часто на уровне n-грамм․ | Глубокое, многослойное понимание контекста благодаря механизму внимания․ |
| Производительность | Хорошая для простых задач, но снижается на сложных․ | Лучшая в классе производительность для большинства задач NLP․ |
| Вычислительные ресурсы | Относительно низкие․ | Высокие для обучения с нуля, умеренные для тонкой настройки․ |
Прикладные Задачи NLP: От Чат-ботов до Перевода
Все эти теоретические основы и мощные инструменты находят свое применение в широком спектре практических задач, которые мы решаем в нашей работе․ От автоматизации рутинных операций до создания интеллектуальных систем, NLP меняет способ взаимодействия человека с информацией․
Разработка Чат-ботов и Вопросно-ответных Систем (QA)
Одна из самых видимых и востребованных областей применения NLP — это разработка чат-ботов и вопросно-ответных систем (QA)․ Мы используем фреймворки вроде Rasa для создания интеллектуальных диалоговых агентов, которые могут понимать намерения пользователя, извлекать сущности из запросов и предоставлять релевантные ответы․ QA-системы идут еще дальше, позволяя пользователям задавать вопросы на естественном языке и получать точные ответы, извлеченные непосредственно из большого корпуса документов․ Это незаменимо для клиентской поддержки, внутренних баз знаний и поиска информации в больших массивах данных․
Суммаризация Текста: Извлечение Сути
В мире информационной перегрузки способность быстро получить суть длинного документа бесценна․ Суммаризация текста, это задача создания краткого и информативного изложения исходного текста․ Мы различаем два основных подхода:
- Экстрактивная суммаризация: Идентифицирует и извлекает наиболее важные предложения из исходного текста, чтобы сформировать краткое изложение․ Для этого мы можем использовать алгоритмы вроде TextRank или другие методы ранжирования предложений․
- Абстрактивная суммаризация: Генерирует новые предложения, которые передают смысл исходного текста, но не обязательно являются его прямыми цитатами․ Это более сложная задача, которая часто требует использования Transformer-моделей (например, на основе GPT) и нейросетей․
Мы используем суммаризацию для анализа новостей, отчетов и длинных статей, чтобы быстро охватить основные моменты․
Машинный Перевод и Работа с Многоязычными Корпусами
Глобализация требует способности работать с текстами на разных языках․ Машинный перевод — это еще одна область, где NLP добился огромных успехов, особенно с появлением Transformer-моделей․ Мы используем как предварительно обученные модели для перевода (например, из Hugging Face), так и библиотеки вроде Polyglot для работы с мультиязычными текстовыми корпусами и анализа редких языков․ Разработка систем автоматического перевода узкоспециализированных текстов (например, технических или медицинских) также является одной из наших задач, где требуется тонкая настройка моделей․
Анализ Юридических, Медицинских и Финансовых Документов
Текст встречается во всех сферах жизни, и некоторые из них требуют особой точности и конфиденциальности․ Мы применяем NLP для:
- Анализа юридических документов и контрактов: Извлечение дат, сторон, обязательств, условий․
- Анализа медицинских записей: Извлечение диагнозов, симптомов, процедур, медикаментов․
- Анализа финансовой отчетности и новостей: Выявление ключевых показателей, анализ тональности финансовых новостей․
Эти задачи часто включают разработку моделей для выявления связей между сущностями и требуют высокой точности, что делает трансформерные модели и CRF (Conditional Random Fields) для распознавания сущностей особенно ценными․
Работа с Данными: Очистка, Разметка и Визуализация
Эффективная работа с NLP невозможна без качественных данных․ Это означает не только их очистку, но и правильное получение, разметку и, конечно же, наглядную визуализацию результатов․
Веб-скрейпинг и Извлечение Текста из Различных Форматов
Первый шаг к анализу данных — это их сбор․ Для этого мы используем:
Библиотеку Beautiful Soup для веб-скрейпинга текста с веб-страниц․ Она позволяет нам парсить HTML и XML, извлекая нужные нам текстовые блоки․
Библиотеку PyMuPDF для извлечения текста из PDF-документов, что является частой задачей при работе с отчетами, научными статьями и другими официальными бумагами․
Мы также сталкиваемся с необходимостью извлечения метаданных текста, таких как автор, дата публикации, источник, которые могут быть полезны для дальнейшего анализа․
Обработка Неполных и Ошибочных Данных, Автоматическая Разметка
Реальные данные редко бывают идеальными․ Мы постоянно сталкиваемся с проблемами обработки неполных и ошибочных данных, такими как опечатки, пропущенные слова, неформальный язык․ Для решения этих проблем мы разрабатываем инструменты для проверки грамматики и орфографии, нормализации пунктуации и очистки текста от "мусора"․
Особенно важной задачей является автоматическая разметка данных․ Качественные размеченные данные, это "топливо" для наших моделей машинного обучения․ Мы создаем инструменты, которые помогают нам быстро и эффективно размечать сущности, тональность или другие атрибуты текста, что значительно ускоряет процесс разработки․
Инструменты для Визуализации Текстовых Данных
После того как мы провели анализ, важно представить результаты в понятной и наглядной форме․ Для визуализации текстовых данных мы используем:
- Облака слов (Word Clouds): Для быстрого понимания наиболее часто встречающихся слов․
- Тепловые карты (Heatmaps): Для визуализации корреляций между словами или темами․
- Графики распределения частотности слов и n-грамм․
- Визуализации тематических моделей, показывающие связи между документами и темами․
Библиотеки, такие как Matplotlib, Seaborn, Plotly, а также специализированные для NLP инструменты, помогают нам создавать красивые и информативные визуализации․ Мы также используем Sweetviz для более глубокого анализа текстовых данных, который позволяет быстро получить сводные отчеты и визуализации․
Мы завершаем наше путешествие по миру обработки естественного языка, но на самом деле, это лишь начало․ Мы увидели, как Python и его богатая экосистема библиотек — от базовых NLTK и spaCy до мощных трансформеров Hugging Face — предоставляют нам беспрецедентные возможности для анализа, понимания и даже генерации человеческого языка․ От простых задач токенизации и стемминга до сложных систем вопросно-ответных систем и машинного перевода, NLP продолжает развиваться семимильными шагами, открывая новые горизонты в каждой области, где есть текст․
Мы, как блогеры, уверены, что каждый, кто работает с данными, сможет найти для себя что-то ценное в этом удивительном мире․ Способность извлекать инсайты из неструктурированного текста, автоматизировать рутинные задачи, создавать интеллектуальных помощников и даже "говорить" с машинами на их собственном языке, это навык, который будет только расти в цене․ Освоив эти инструменты, мы не просто анализируем слова; мы разгадываем мысли, чувства и идеи, стоящие за ними, тем самым приближаясь к полному пониманию языка вселенной․ И это только начало!
Подробнее
| Обработка естественного языка Python | Токенизация и стемминг NLTK | NER с spaCy и Flair | Тематическое моделирование Gensim LDA | Word Embeddings Word2Vec GloVe |
| Анализ тональности VADER TextBlob | Трансформеры Hugging Face NLP | Разработка чат-ботов Python Rasa | Суммаризация текста Abstractive Extractive | Векторизация предложений Sentence Transformers |





