
- Разгадывая Язык Цифрового Мира: Наш Глубокий Погружение в NLP с Python
- Часть 1: Первые Шаги в Мир Текста – От Сырых Данных к Понятным Структурам
- Основы NLTK: Токенизация и Стемминг
- Продвинутая Лемматизация и Стемминг
- Использование spaCy для Анализа Зависимостей и Синтаксического Парсинга
- Часть 2: Как Компьютеры "Понимают" Слова – Векторизация и Встраивания
- Разработка Собственных Векторизаторов Текста (CountVectorizer, TfidfVectorizer)
- Word Embeddings: Word2Vec и GloVe с Использованием Gensim
- Векторизация Предложений и Документов (Doc2Vec, Sentence Transformers)
- Сравнение Методов Векторизации
- Часть 3: Распознавание Смысла – От Сущностей до Эмоций
- Использование spaCy и Flair для Распознавания Именованных Сущностей (NER)
- Анализ Тональности (Sentiment Analysis) с VADER и Продвинутые Подходы
- Анализ Лексического Богатства и Сложности Текстов
- Часть 4: Погружение в Глубины Текста – Темы, Классификация и Суммаризация
- Библиотека Gensim для Тематического Моделирования (LDA, LSI, NMF)
- Применение Scikit-learn для Классификации Текстов
- Разработка Системы Суммаризации Текста
- Часть 5: Новая Эра NLP – Трансформеры и Глубокое Обучение
- Трансформеры (Hugging Face) для Сложных Задач NLP
- Применение PyTorch/TensorFlow для Создания Нейросетей NLP
- Часть 6: NLP на Грани – Сложные Задачи и Реальные Применения
- Обработка Многоязычных Текстовых Корпусов и Машинный Перевод
- Разработка Чат-ботов и Систем Вопросно-Ответных Систем (QA)
- Анализ Специализированных Текстов: От Юридических до Медицинских
- Работа с Большими Текстовыми Массивами и Веб-Скрейпинг
- Дополнительные Приложения и Инструменты
- Часть 7: Инструменты и Оценка – Что Выбрать и Как Измерить Успех
- Сравнение Библиотек и Инструментов
- Инструменты для Визуализации и Анализа Данных
- Оценка Качества NLP-Моделей
Разгадывая Язык Цифрового Мира: Наш Глубокий Погружение в NLP с Python
Приветствуем вас, дорогие читатели, в нашем увлекательном путешествии по миру обработки естественного языка (NLP) с использованием мощи Python! Мы, как опытные блогеры и энтузиасты технологий, не перестаем удивляться, насколько глубоко машины научились понимать, анализировать и даже генерировать человеческую речь․ Это не просто набор алгоритмов и библиотек; это целая вселенная возможностей, которая открывает перед нами двери в новые измерения взаимодействия человека и компьютера․
В этой статье мы не просто расскажем о концепциях – мы поделимся нашим личным опытом, подводными камнями и триумфами, которые сопровождали нас на пути освоения NLP․ Мы уверены, что после прочтения вы не только получите фундаментальные знания, но и вдохновитесь на собственные эксперименты․ Ведь наш мир ежедневно генерирует колоссальные объемы текстовых данных – от твитов и сообщений в мессенджерах до научных статей и юридических документов․ И задача NLP – помочь нам извлечь из этого потока ценные инсайты, автоматизировать рутину и создать по-настоящему умные системы․
Часть 1: Первые Шаги в Мир Текста – От Сырых Данных к Понятным Структурам
Прежде чем мы сможем научить машину "читать" и "понимать" текст, нам необходимо этот текст подготовить․ Сырые данные редко бывают идеальными: они содержат шум, лишние символы, ошибки и нерегулярности․ Этот этап, известный как предобработка текста, является краеугольным камнем любого успешного NLP-проекта․ Мы всегда подходим к нему с особой тщательностью, ведь качество исходных данных напрямую влияет на итоговую производительность наших моделей․
Наш опыт показывает, что грамотная очистка данных может сэкономить часы отладки и значительно улучшить результаты․ Мы часто сталкиваемся с HTML-тегами в веб-страницах, пунктуацией, которая не несет смысловой нагрузки, или же с необходимостью привести все слова к единому регистру․ Для этих целей мы активно используем регулярные выражения, которые позволяют нам эффективно находить и заменять нужные паттерны в тексте․
Основы NLTK: Токенизация и Стемминг
Начинать знакомство с NLP без NLTK (Natural Language Toolkit) — это как строить дом без фундамента․ Эта библиотека стала для нас первой отправной точкой, когда мы только начинали свой путь; Одни из самых базовых, но в то же время важнейших операций, которые мы осваивали с NLTK, это токенизация и стемминг․ Токенизация, это процесс разбиения текста на отдельные слова или предложения, так называемые "токены"․ Без этого шага дальнейший анализ текста просто невозможен, ведь мы не можем работать с текстом как с одной сплошной строкой․
Представьте себе, что вы получили огромный текстовый документ․ Первое, что мы делаем, это разбиваем его на предложения, а затем каждое предложение — на слова․ Для этого NLTK предоставляет удобные функции, такие как `word_tokenize` и `sent_tokenize`․ После токенизации часто возникает задача уменьшить количество уникальных слов, приведя их к их корневой форме․ Здесь на помощь приходит стемминг, процесс удаления суффиксов и префиксов, чтобы получить "корень" слова․ Например, слова "бегущий", "бегал", "бежать" могут быть приведены к одному "бег"․ Мы обнаружили, что стемминг, хотя и прост, иногда может создавать несуществующие слова, что является его основным недостатком․
Продвинутая Лемматизация и Стемминг
По мере того, как наши проекты становились сложнее, мы столкнулись с ограничениями стемминга․ Как мы уже упоминали, он часто отсекает окончания без учета морфологии языка, что может привести к потере смысла или созданию некорректных слов․ Именно тогда мы обратили внимание на лемматизацию – более интеллектуальный процесс, который приводит слова к их словарной форме (лемме), используя морфологический анализ․ "Бегущий", "бегал", "бежать" в процессе лемматизации будут приведены к "бежать", что является корректной словарной формой․
Для лемматизации мы часто используем spaCy, которая, на наш взгляд, предлагает более точные и быстрые решения по сравнению с NLTK, особенно для языков с богатой морфологией․ В нашей практике мы часто сравниваем результаты NLTK и spaCy для конкретных задач, и выбор всегда зависит от требуемой точности и производительности․ Для русского языка, например, Stanza также показывает отличные результаты в лемматизации․
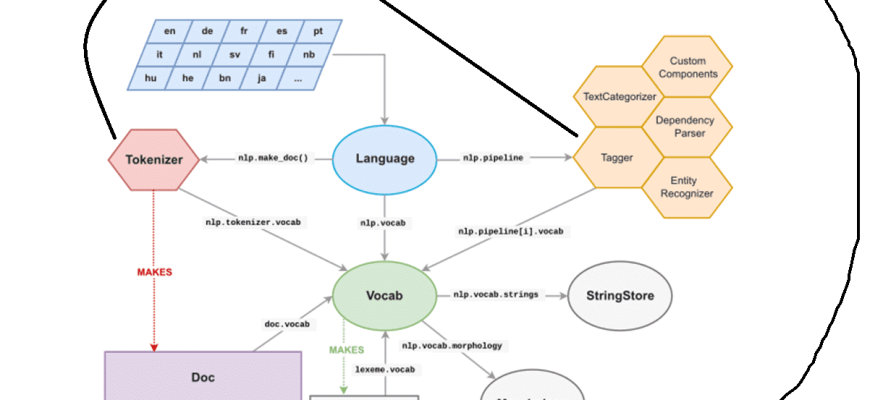
Использование spaCy для Анализа Зависимостей и Синтаксического Парсинга
Если NLTK – это наша стартовая площадка, то spaCy – это высокоскоростной шаттл, который позволил нам выйти на орбиту продвинутого NLP․ Мы быстро оценили его скорость и эффективность, особенно когда речь заходит о синтаксическом парсинге и анализе зависимостей․ Вместо того чтобы просто разбивать текст на слова, spaCy позволяет нам понять грамматическую структуру предложения: кто что делает, какой объект у глагола, какие слова относятся к каким другим словам․
Это очень похоже на то, как мы, люди, разбираем предложение, чтобы понять его смысл․ SpaCy строит дерево зависимостей, которое визуально показывает отношения между словами․ Это невероятно полезно для задач, где необходимо извлечь конкретную информацию, например, кто является субъектом действия, или какие атрибуты относятся к определенному объекту․ Мы часто используем эту функциональность для извлечения фактов и построения баз знаний․
Часть 2: Как Компьютеры "Понимают" Слова – Векторизация и Встраивания
Представьте, что вы пытаетесь объяснить компьютеру значение слова "кошка"․ Как вы это сделаете? Вы можете показать картинку, описать её характеристики, назвать синонимы․ Но для машины слова — это просто последовательности символов․ Чтобы компьютер мог работать с текстом математически, нам нужно преобразовать слова в числовые векторы․ Этот процесс называется векторизацией, и он является ключевым для большинства задач NLP․ Мы прошли долгий путь от простых методов до сложных нейросетевых встраиваний, и каждый шаг открывал новые горизонты․
Разработка Собственных Векторизаторов Текста (CountVectorizer, TfidfVectorizer)
Наши первые шаги в векторизации были довольно простыми․ Мы использовали такие классические методы, как CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn․ CountVectorizer создает вектор, где каждая позиция соответствует слову из всего словаря, а значение, частоте появления этого слова в документе․ Это интуитивно понятно, но имеет свои недостатки: длинные документы получают большие числа, а "общие" слова (вроде "и", "в", "на") могут доминировать, не неся много смысла․
Чтобы решить эту проблему, мы обратились к TfidfVectorizer․ TF-IDF (Term Frequency-Inverse Document Frequency) учитывает не только частоту слова в документе, но и его редкость во всем корпусе текстов․ Если слово часто встречается в одном документе, но редко в других, его вес будет выше․ Это позволило нам выделять более значимые слова, которые действительно характеризуют содержание документа․ Мы часто используем эти векторизаторы для задач классификации и кластеризации текстов, где простота и интерпретируемость играют важную роль․
Word Embeddings: Word2Vec и GloVe с Использованием Gensim
Однако, несмотря на свою полезность, CountVectorizer и TF-IDF имеют фундаментальный недостаток: они не учитывают семантическую близость слов․ Слова "кошка" и "котёнок" будут представлены как совершенно разные сущности, хотя для нас они очевидно связаны․ Это побудило нас исследовать Word Embeddings – векторные представления слов, которые захватывают их семантические и синтаксические отношения․ Мы были поражены, когда впервые увидели, как Word2Vec, разработанный Google, позволяет выполнять "математику слов", например, "король ― мужчина + женщина = королева"․
Мы активно используем библиотеку Gensim для работы с Word2Vec и GloVe․ Gensim предоставляет удобный интерфейс для обучения собственных моделей встраивания на больших корпусах текста․ Мы обнаружили, что хорошо обученные Word Embeddings значительно улучшают производительность наших моделей в задачах, требующих понимания смысла слов, таких как анализ тональности или классификация․ Применение FastText, который также поддерживается Gensim, позволило нам работать с редкими словами и даже морфемами, что было особенно ценно для языков с богатой морфологией․
Векторизация Предложений и Документов (Doc2Vec, Sentence Transformers)
После того как мы освоили векторизацию отдельных слов, следующим логичным шагом для нас стало представление целых предложений и документов в виде векторов․ Ведь часто нам нужно сравнивать не отдельные слова, а целые блоки текста․ Doc2Vec, логическое расширение Word2Vec, позволяет нам создавать векторные представления для документов произвольной длины․ Мы использовали его для поиска похожих статей или отзывов, и результаты были весьма обнадеживающими․
Однако настоящим прорывом стали Sentence Transformers, которые позволяют нам получать высококачественные векторные представления предложений, учитывающие контекст․ Эти модели, часто основанные на архитектурах трансформеров, превосходно справляются с задачей измерения семантического сходства между предложениями․ Мы применяем их для задач суммаризации, вопросно-ответных систем и даже для обнаружения плагиата, где необходимо точно определить, насколько близки по смыслу два текстовых фрагмента․
Сравнение Методов Векторизации
Наш опыт показывает, что не существует "лучшего" метода векторизации для всех задач․ Выбор всегда зависит от конкретных требований проекта․ Мы часто проводим сравнения, чтобы определить наиболее подходящий подход․
Часть 3: Распознавание Смысла – От Сущностей до Эмоций
После того как мы научились готовить текст и представлять его в числовом виде, перед нами открылись двери к более сложным задачам – извлечению конкретной информации и пониманию эмоциональной окраски․ Эти задачи составляют основу многих реальных приложений, от чат-ботов до систем мониторинга социальных сетей․ Мы всегда с особым интересом подходим к этой части, ведь именно здесь машины начинают по-настоящему "понимать" человеческую речь․
Использование spaCy и Flair для Распознавания Именованных Сущностей (NER)
Распознавание именованных сущностей (NER) – это фундаментальная задача в NLP, которая позволяет нам автоматически идентифицировать и классифицировать именованные сущности в тексте, такие как имена людей, организации, географические объекты, даты и т․д․․ Мы часто используем NER для автоматического заполнения баз данных, извлечения информации из юридических документов или новостных статей․ Наш опыт показывает, что spaCy является отличным инструментом для быстрого и эффективного NER "из коробки" для многих языков, включая русский․ Мы ценим его за скорость и хорошо предобученные модели․
Однако, когда нам требуется более высокая точность или работа с более специфичными типами сущностей, мы обращаемся к библиотеке Flair․ Flair предлагает современные модели на основе глубокого обучения, которые часто превосходят традиционные подходы в точности, особенно когда речь идет о сложных задачах и языках с богатой морфологией․ Применение условных случайных полей (CRF) в сочетании с глубокими нейросетями также дало нам отличные результаты в NER, позволяя учитывать контекст и зависимости между словами․
Анализ Тональности (Sentiment Analysis) с VADER и Продвинутые Подходы
Понимание эмоциональной окраски текста – это мощный инструмент для бизнеса, маркетинга и даже социологии․ Мы активно применяем анализ тональности для оценки отзывов клиентов, мониторинга упоминаний бренда в социальных сетях или анализа финансовых новостей․ Наш первый инструмент в этом арсенале – VADER (Valence Aware Dictionary and sEntiment Reasoner)․ Это правиловой, лексический подход, который не требует обучения на размеченных данных и отлично справляется с текстами из социальных сетей, понимая сленг, эмодзи и даже сарказм․ Мы были приятно удивлены его эффективностью в анализе коротких сообщений․
"Язык – это дорожная карта культуры․ Он говорит вам, откуда пришли его люди и куда они направляются․"
— Рита Мэй Браун
Однако для более сложных и нюансированных задач, таких как анализ длинных отзывов о продуктах или медицинских записей, мы переходим к моделям на основе машинного обучения и глубоких нейросетей․ Мы используем Scikit-learn для классификации тональности (например, SVM или наивный байесовский классификатор) или PyTorch/TensorFlow для создания более сложных моделей, способных улавливать контекст и тонкие оттенки настроения․ Анализ тональности с учетом сарказма и иронии, а также работа с эмодзи и сленгом в современных текстах, представляют собой отдельные вызовы, для решения которых мы часто используем предварительно обученные трансформерные модели․ Библиотека TextBlob также может быть использована для простого определения тональности, хотя для русского языка её возможности ограничены․
Анализ Лексического Богатства и Сложности Текстов
Помимо прямого смысла и эмоций, текст несет в себе информацию о стиле, сложности и уникальности․ Мы часто проводим анализ лексического богатства текстов, чтобы понять, насколько разнообразен словарный запас автора или группы текстов․ Это может быть полезно для определения авторского почерка, оценки качества контента или даже для анализа текстов отзывов клиентов, чтобы выявить, насколько детально они описывают свой опыт․
Мы используем различные метрики, такие как отношение уникальных слов к общему количеству слов, или более сложные индексы читаемости․ Библиотека Textacy, например, предоставляет удобные функции для такого рода анализа, позволяя нам глубоко погрузиться в стилистику текстов и выявить скрытые паттерны․ Это помогает нам не только оценить тексты, но и разрабатывать инструменты для проверки грамматики и стилистики․
Часть 4: Погружение в Глубины Текста – Темы, Классификация и Суммаризация
После того как мы научились извлекать сущности и анализировать тональность, следующим логичным шагом стало понимание общей структуры и основных тем больших текстовых корпусов․ Ведь часто нам нужно не просто найти факты, а понять, о чем идет речь в тысячах документов, или автоматически отнести их к определенным категориям․ Это задачи тематического моделирования, классификации и суммаризации – мощные инструменты для работы с информацией․
Библиотека Gensim для Тематического Моделирования (LDA, LSI, NMF)
Представьте, что у вас есть огромный архив документов, и вы хотите понять, какие основные темы в нем присутствуют, не читая каждый документ вручную․ Здесь на помощь приходит тематическое моделирование․ Мы активно используем библиотеку Gensim, которая предоставляет эффективные реализации таких алгоритмов, как Латентное Размещение Дирихле (LDA) и Латентно-Семантический Индекс (LSI), а также Неотрицательная Матричная Факторизация (NMF), часто используемая с Scikit-learn․
LDA и NMF позволяют нам обнаруживать скрытые "темы" в коллекции документов, представляя каждый документ как смесь этих тем, а каждую тему как распределение слов․ Мы применяем тематическое моделирование для анализа отзывов клиентов, выявления скрытых тем в больших текстовых массивах, категоризации статей и даже для анализа поведенческих паттернов в чатах или пользовательских запросах․ Сравнение моделей тематического моделирования, таких как LDA и NMF, является важным этапом, поскольку каждая из них имеет свои сильные стороны и лучше подходит для определенных типов данных․
Применение Scikit-learn для Классификации Текстов
Классификация текстов – это одна из самых распространенных и практически значимых задач в NLP․ Мы используем её для автоматического распределения электронных писем по папкам ("спам" или "не спам"), категоризации новостных статей по рубрикам, или определения жанра литературных произведений․ Scikit-learn – это наша рабочая лошадка для машинного обучения, и в частности для классификации текстов․
Мы обучили множество моделей, используя различные алгоритмы: от простого Наивного Байесовского классификатора до более сложных методов, таких как Метод Опорных Векторов (SVM) и логистическая регрессия․ Векторизаторы TF-IDF или Word Embeddings обычно используются в качестве входных данных для этих моделей․ Наш опыт показывает, что правильный выбор алгоритма и тщательная предобработка данных играют решающую роль в достижении высокой точности классификации․
Разработка Системы Суммаризации Текста
В мире, где информация поступает огромными потоками, способность быстро получать суть длинных текстов становится критически важной․ Именно здесь на помощь приходит суммаризация текста․ Мы разрабатываем системы, которые могут автоматически генерировать краткое содержание документов, статей или даже целых книг․ Существует два основных подхода: экстрактивная и абстрактивная суммаризация․
Сравнение моделей суммирования – экстрактивной и абстрактной – всегда показывает, что каждая из них имеет свою нишу․ Экстрактивная лучше подходит для сохранения оригинальной формулировки, в то время как абстрактивная обеспечивает более глубокое переосмысление и сжатие информации․
Часть 5: Новая Эра NLP – Трансформеры и Глубокое Обучение
Если предыдущие методы можно сравнить с классической механикой, то трансформеры и глубокое обучение – это квантовая физика в мире NLP․ Мы были свидетелями того, как эти архитектуры совершили революцию, позволив машинам достичь беспрецедентного уровня понимания и генерации человеческого языка․ Работа с ними стала для нас одним из самых захватывающих направлений․
Трансформеры (Hugging Face) для Сложных Задач NLP
Появление архитектуры Трансформеров в 2017 году и последующее развитие таких моделей, как BERT, GPT, T5, изменило всё․ Они решают проблему длинных зависимостей в тексте, позволяя моделям "видеть" весь контекст предложения или даже документа сразу․ Мы активно используем библиотеку Hugging Face Transformers, которая предоставляет тысячи предварительно обученных моделей и удобный API для их использования․ Это позволило нам решать задачи, которые ранее казались невозможными или требовали огромных усилий:
Генерация текста: Мы используем GPT-подобные модели для создания связных и креативных текстов, от коротких описаний до целых статей․
Машинный перевод: Трансформерные модели значительно улучшили качество автоматического перевода, приблизив его к человеческому․
Вопросно-ответные системы (QA): Мы разрабатываем QA-системы, которые могут находить точные ответы на вопросы из заданного текста или даже генерировать их․
Распознавание эмоций: Трансформеры позволяют более тонко улавливать эмоциональную окраску, включая сарказм и иронию․
Применение PyTorch/TensorFlow для Создания Нейросетей NLP
Хотя Hugging Face предоставляет готовые решения, для более глубокой настройки и создания уникальных архитектур мы обращаемся к фреймворкам глубокого обучения, таким как PyTorch и TensorFlow (включая Keras)․ Мы создаем собственные нейронные сети, включая рекуррентные сети (LSTM) для задач, где важна последовательность, и, конечно, работаем с архитектурами на основе трансформеров․
Тонкая настройка (Fine-tuning) предварительно обученных моделей – это мощная техника, которую мы часто применяем․ Вместо того чтобы обучать модель с нуля, мы берем уже обученную на огромном корпусе текста трансформерную модель (например, BERT) и дообучаем её на наших специфических данных для конкретной задачи (например, классификации юридических документов или анализа тональности финансовых новостей)․ Это позволяет нам достигать высокой производительности с относительно небольшим объемом размеченных данных․
Часть 6: NLP на Грани – Сложные Задачи и Реальные Применения
После освоения фундаментальных и продвинутых методов, мы начали применять NLP для решения реальных, часто очень сложных задач․ Именно здесь теория превращается в практику, а алгоритмы – в ценные инструменты, способные трансформировать целые отрасли․ Наш опыт охватывает широкий спектр приложений, от обработки многоязычных данных до создания чат-ботов и анализа специализированных документов․
Обработка Многоязычных Текстовых Корпусов и Машинный Перевод
Мир не ограничивается одним языком, и наши проекты также․ Обработка многоязычных текстовых корпусов – это постоянный вызов․ Мы используем такие библиотеки, как Polyglot и Stanza, которые поддерживают множество языков и предоставляют инструменты для токенизации, лемматизации и POS-теггинга для языков с богатой морфологией, таких как русский, арабский или хинди․ Polyglot также очень полезен для определения языка текста․
Разработка систем машинного перевода на Python – это одна из вершин NLP․ Хотя создание собственной системы с нуля является огромной задачей, мы активно используем предварительно обученные трансформерные модели (например, MarianMT из Hugging Face) для создания систем автоматического перевода, в т․ч․ для узкоспециализированных текстов․ Это позволяет нам преодолевать языковые барьеры и работать с глобальными данными․
Разработка Чат-ботов и Систем Вопросно-Ответных Систем (QA)
Чат-боты и QA-системы – это, пожалуй, самые наглядные примеры применения NLP․ Мы разрабатывали чат-ботов на Python, используя фреймворк Rasa, который предоставляет мощные инструменты для создания диалоговых систем․ Это включает в себя понимание естественного языка (NLU), управление диалогом и генерацию ответов․ Мы научились обрабатывать пользовательские запросы, извлекать из них намерения и сущности, и генерировать адекватные ответы․
Разработка систем вопросно-ответных систем (QA) – это еще одна интересная область․ Мы создаем системы, которые могут отвечать на вопросы, основываясь на большом корпусе документов․ Это может быть извлечение ответа из существующего текста или генерация нового ответа․ Трансформерные модели, такие как BERT, отлично подходят для этой задачи, позволяя нам находить точные фрагменты текста, содержащие ответы․
Анализ Специализированных Текстов: От Юридических до Медицинских
NLP находит применение не только в общих задачах, но и в очень специфичных областях․ Мы работали с анализом юридических документов и контрактов, где точность и способность извлекать конкретные даты, имена, условия и обязательства имеют критическое значение․ Для этого мы часто используем комбинацию NER, синтаксического парсинга с spaCy и специализированных словарей․
Аналогично, анализ текста в медицинских записях требует высокой чувствительности и точности․ Извлечение симптомов, диагнозов, названий лекарств и процедур из неструктурированного текста может значительно ускорить работу врачей и исследователей․ Здесь мы сталкиваемся с проблемами обработки неполных и ошибочных данных, а также с необходимостью создания специализированных словарей и онтологий;
Работа с Большими Текстовыми Массивами и Веб-Скрейпинг
Современные данные часто приходят в огромных объемах․ Обработка больших текстовых массивов (Big Data NLP) требует эффективных алгоритмов и оптимизированных подходов․ Мы используем библиотеки, такие как Gensim, для тематического моделирования на больших данных, а также распределенные вычисления для ускорения процессов․
Прежде чем мы можем анализировать данные, их нужно получить․ Веб-скрейпинг текста – это наш первый шаг для сбора информации из интернета․ Библиотека Beautiful Soup для Python – это наш незаменимый инструмент для парсинга HTML и извлечения текста с веб-страниц․ А для работы с PDF-документами мы используем PyMuPDF, который позволяет эффективно извлекать текст, изображения и метаданные․
Дополнительные Приложения и Инструменты
Наш путь в NLP наполнен разнообразными задачами:
Анализ стилистики текстов: Мы разрабатываем системы для определения авторского почерка и стиля письма, что полезно для проверки подлинности или анализа текстов в блогосфере․
Разработка систем обнаружения плагиата: Используя метрики сходства строк из библиотеки Textdistance (например, Левенштейна или Джаккарда) и векторизацию документов (Doc2Vec, Sentence Transformers), мы создаем инструменты для выявления дубликатов и плагиата․
Обработка текста в режиме реального времени (Streaming NLP): Для анализа сообщений в социальных сетях или лог-файлов мы разрабатываем системы, способные обрабатывать текстовые данные "на лету"․
Создание словарей и тезаурусов: Для улучшения качества NLP-моделей в специфических областях мы разрабатываем собственные словари терминов и тезаурусы․
Работа с нелатинскими алфавитами: Мы активно работаем с текстами на различных языках, включая русский, китайский, арабский, используя специализированные библиотеки и модели․
Разработка инструментов для проверки фактов (Fact-Checking): Это сложная, но крайне важная задача, где NLP помогает сопоставлять утверждения в тексте с надежными источниками информации․
Часть 7: Инструменты и Оценка – Что Выбрать и Как Измерить Успех
После того как мы погрузились в мир алгоритмов и приложений, возникает закономерный вопрос: как выбрать правильные инструменты и, что не менее важно, как оценить эффективность наших решений? Наш опыт показывает, что без систематического подхода к выбору библиотек и строгого измерения результатов, любой проект рискует потерпеть неудачу․
Сравнение Библиотек и Инструментов
Рынок NLP-инструментов постоянно развивается, и выбор подходящей библиотеки может быть непростой задачей․ Мы постоянно сравниваем различные решения, чтобы найти оптимальный баланс между производительностью, точностью, простотой использования и поддержкой языка․
Например, при выборе между NLTK и spaCy для лемматизации или токенизации, мы всегда учитываем:
Для задач, требующих высокой скорости и готовых решений, мы выбираем spaCy․ Для исследовательских проектов или очень специфических задач — NLTK․
Мы также сравниваем алгоритмы кластеризации текстов, такие как K-Means и DBSCAN, для анализа отзывов о продуктах по категориям или выявления паттернов в пользовательских запросах․ Каждый метод имеет свои особенности, и выбор зависит от структуры данных и наших целей․
Инструменты для Визуализации и Анализа Данных
Текстовые данные часто бывают очень сложными, и визуализация может помочь нам получить ценные инсайты․ Мы используем инструменты для создания облаков слов (Word Clouds) для быстрого выявления наиболее частых терминов, или тепловых карт (Heatmaps) для визуализации матриц сходства между документами․ Sweetviz – это еще одна полезная библиотека для быстрого анализа данных, включая текстовые поля․
Оценка Качества NLP-Моделей
Без адекватной оценки невозможно понять, насколько хорошо работает наша модель․ Для задач классификации и NER мы используем стандартные метрики:
Мы тщательно отслеживаем эти метрики, чтобы не только сравнивать различные модели, но и выявлять области для улучшения․ Например, для NER-моделей мы оцениваем качество распознавания имен собственных, организаций и других сущностей, чтобы убедиться, что наша система работает надежно․
Мы прошли долгий и увлекательный путь по необъятным просторам обработки естественного языка с Python․ От базовой токенизации и стемминга до сложных трансформерных архитектур и систем искусственного интеллекта, способных генерировать текст и отвечать на вопросы, мы видели, как эта область развивается с головокружительной скоростью․ NLP – это не просто набор технологий; это мост между человеческим языком и миром компьютеров, который продолжает расширяться и укрепляться․
Наш опыт показал, что ключ к успеху в NLP лежит в глубоком понимании предметной области, умении выбирать правильные инструменты для каждой задачи и постоянном стремлении к экспериментам․ Мы верим, что потенциал NLP еще далек от исчерпания, и впереди нас ждут еще более удивительные открытия и прорывные приложения․ Продолжайте учиться, экспериментировать и творить – ведь язык, в конце концов, является одной из самых мощных сил, формирующих наш мир, и теперь у нас есть инструменты, чтобы по-настоящему его понять․





