
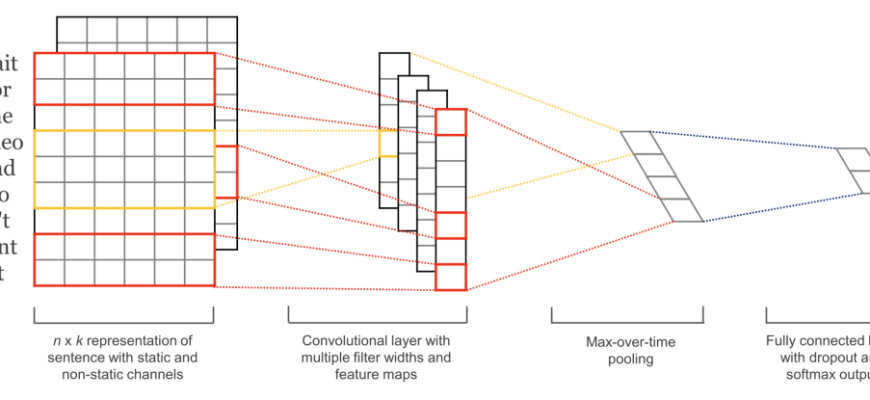
- Разгадывая Язык Цифрового Мира: Наш Путь в Мир Обработки Естественного Языка на Python
- Фундаментальные Блоки NLP: От Слова к Смыслу
- NLTK: Наш Первый Шаг в Мир Текста
- spaCy: Скорость и Точность в Лемматизации и Синтаксическом Парсинге
- Регулярные Выражения (re): Наш Хирургический Инструмент для Очистки Текста
- TextBlob: Простота для Быстрых Задач NLP
- Как Компьютер "Видит" Слова: Векторизация и Встраивания
- Традиционные Векторизаторы: CountVectorizer и TfidfVectorizer
- Word Embeddings: Word2Vec, GloVe и FastText с Использованием Gensim
- Векторизация Предложений и Документов: Sentence Transformers и Контекстные Встраивания (BERT, Трансформеры)
- Основные Задачи NLP: От Распознавания до Понимания
- Распознавание Именованных Сущностей (NER)
- Тематическое Моделирование: Поиск Скрытых Тем с Gensim
- Классификация Текстов: От Спама до Категоризации Статей
- Анализ Тональности (Sentiment Analysis): Понимание Эмоций
- Суммаризация Текста: Извлечение Сути
- Машинный Перевод и Вопросно-Ответные Системы
- Глубокое Погружение и Практические Приложения
- Сбор и Подготовка Текстовых Данных: Веб-скрейпинг и Извлечение из PDF
- Многоязычный NLP: Преодолевая Языковые Барьеры
- Разработка Чат-ботов и Генерация Текста
- Специализированный Анализ Текстов и Извлечение Информации
- Визуализация Текстовых Данных и Оценка Моделей
- Вызовы и Будущее NLP: Что Ждет Нас Впереди
- Проблемы Обработки Неполных и Ошибочных Данных
- Контекст, Сарказм и Глубокое Понимание
- Большие Данные и Производительность
- Этика и Предвзятость в NLP
- Будущее NLP: Мультимодальность и Искусственный Общий Интеллект
Разгадывая Язык Цифрового Мира: Наш Путь в Мир Обработки Естественного Языка на Python
Приветствуем, дорогие читатели и коллеги по цифровому цеху! Сегодня мы хотим пригласить вас в увлекательное путешествие по безграничным просторам Обработки Естественного Языка, более известной как NLP (Natural Language Processing). Это не просто набор алгоритмов; это целая вселенная, где компьютеры учатся понимать, интерпретировать и даже генерировать человеческую речь. И, конечно же, нашим верным спутником в этом путешествии станет Python – язык, который благодаря своей гибкости и огромному сообществу разработчиков, стал де-факто стандартом в области машинного обучения и NLP. Мы вместе разберемся, как, используя различные библиотеки и подходы, мы можем заставить машины "говорить" с нами на одном языке, открывая новые горизонты для бизнеса, науки и повседневной жизни.
В мире, где объем текстовой информации растет экспоненциально каждую секунду, способность автоматически обрабатывать, анализировать и извлекать смысл из текстов становится не просто полезной, а критически важной. От чат-ботов, которые отвечают на наши вопросы, до систем анализа тональности, предсказывающих настроения рынка, и переводчиков, стирающих языковые барьеры – везде лежит невидимый труд NLP-алгоритмов. Мы будем делиться нашим опытом, показывать практические примеры и давать рекомендации, чтобы каждый из вас смог почувствовать себя уверенным исследователем в этой захватывающей области. Приготовьтесь, нас ждет глубокое погружение в мир слов, смыслов и кода!
Фундаментальные Блоки NLP: От Слова к Смыслу
Прежде чем компьютер сможет что-либо "понять" в тексте, нам необходимо преобразовать этот текст из обычной последовательности символов в нечто, что машина способна обрабатывать. Этот этап, известный как предобработка текста, является фундаментом любого NLP-проекта. Мы начинаем с самых азов, постепенно погружаясь в более сложные концепции, которые позволяют нам извлекать истинный смысл из потока слов. Именно здесь закладываются основы, на которых строится вся дальнейшая работа с текстом.
NLTK: Наш Первый Шаг в Мир Текста
Начнем мы с библиотеки NLTK (Natural Language Toolkit) – это своего рода швейцарский нож для начинающих и опытных NLP-специалистов. NLTK предоставляет нам мощные инструменты для базовой обработки текста. Первым делом мы сталкиваемся с токенизацией – процессом разбиения текста на отдельные слова или фразы, которые мы называем токенами. Представьте, что у нас есть предложение: "Мы любим изучать NLP". NLTK поможет нам превратить его в список: ["Мы", "любим", "изучать", "NLP"]. Это кажется простым, но это критически важный шаг, поскольку позволяет нам работать с отдельными смысловыми единицами.
Далее следуют стемминг и лемматизация. Обе эти техники направлены на приведение слов к их базовой форме, но делают это по-разному. Стемминг (например, с помощью алгоритма Портера) просто отсекает окончания, пытаясь получить корень слова. Так, слова "бежать", "бежит", "бежал" могут быть сведены к "беж". Это быстрый, но иногда грубый метод, который может привести к "несуществующим" словам. Лемматизация же (которую мы можем осуществить с помощью WordNetLemmatizer в NLTK) более интеллектуальна: она приводит слово к его словарной (канонической) форме, учитывая морфологию языка. Так, "бежать", "бежит", "бежал" будут сведены к "бежать". Мы часто выбираем лемматизацию, когда нам нужна большая точность.
Примеры использования NLTK для базовой предобработки:
- Токенизация предложений: Разбиение текста на отдельные предложения, что важно для анализа структуры.
- Токенизация слов: Как мы уже упоминали, это основа для дальнейшей работы.
- Удаление стоп-слов: Избавление от часто встречающихся, но малоинформативных слов, таких как "и", "в", "на", "он". Это помогает сосредоточиться на более значимых терминах.
- POS-теггинг (Part-of-Speech Tagging): Определение части речи для каждого слова (существительное, глагол, прилагательное и т.д.). Это обогащает наше понимание структуры предложения.
spaCy: Скорость и Точность в Лемматизации и Синтаксическом Парсинге
Хотя NLTK является отличным стартом, для более серьезных и производительных задач мы часто обращаемся к spaCy. Эта библиотека разработана с учетом скорости и эффективности, предлагая готовые предобученные модели для различных языков. Если NLTK требует от нас загрузки отдельных модулей для стемминга, лемматизации или POS-теггинга, то spaCy предоставляет комплексный "конвейер" обработки текста. Мы просто загружаем языковую модель (например, для русского языка), и она уже содержит в себе все необходимые компоненты.
Что особенно выделяет spaCy в нашем арсенале:
- Продвинутая лемматизация: spaCy использует контекст слова для более точной лемматизации, что особенно важно для языков с богатой морфологией, таких как русский.
- Синтаксический парсинг: Мы можем легко построить дерево зависимостей для каждого предложения, определяя отношения между словами. Это позволяет нам глубоко анализировать структуру предложения и извлекать сложный смысл.
- Распознавание именованных сущностей (NER): spaCy – один из наших основных инструментов для быстрого и точного извлечения именованных сущностей, таких как имена людей, организации, географические объекты, даты и т.д.. Это невероятно полезно для автоматического заполнения баз данных или категоризации информации.
- Скорость: spaCy значительно быстрее NLTK для многих задач, что делает его предпочтительным выбором для обработки больших текстовых массивов.
Регулярные Выражения (re): Наш Хирургический Инструмент для Очистки Текста
Предобработка текста не обходится без очистки. Часто наши данные содержат шум: HTML-теги, специальные символы, лишние пробелы, URL-адреса, эмодзи или сленг. Здесь на помощь приходят регулярные выражения (re) – мощный инструмент для поиска и замены текстовых шаблонов. Мы используем их для удаления всего ненужного, что может помешать нашим NLP-моделям. Например, если мы анализируем отзывы клиентов, нам нужно избавиться от всех HTML-тегов, которые могли попасть в текст из веб-страницы.
Типичные задачи очистки текста, решаемые с помощью `re`:
- Удаление HTML-тегов.
- Извлечение или удаление URL-адресов.
- Удаление пунктуации и специальных символов.
- Нормализация текста (например, приведение к нижнему регистру).
- Работа с эмодзи и сленгом, превращая их в анализируемые токены или удаляя.
TextBlob: Простота для Быстрых Задач NLP
Иногда нам не нужны сложные модели или высокопроизводительные решения. Для быстрых экспериментов или простых задач мы обращаемся к TextBlob. Это удобная библиотека, построенная на базе NLTK, которая предоставляет интуитивно понятный API для многих общих задач NLP: токенизация, POS-теггинг, извлечение фраз, анализ тональности и даже перевод. Мы ценим TextBlob за его простоту и возможность быстро получить результат, хотя для сложных проектов его ограничения становятся очевидными.
Сравнение некоторых базовых возможностей NLTK, spaCy и TextBlob:
| Функционал | NLTK | spaCy | TextBlob |
|---|---|---|---|
| Токенизация | Предоставляет различные токенизаторы | Встроенный быстрый токенизатор | Простой API для токенизации |
| Лемматизация | WordNetLemmatizer | Контекстно-зависимая, высокоточная | Базовая лемматизация |
| NER | Доступно, но менее производительно | Быстрое и точное | Отсутствует |
| Синтаксический парсинг | Требует дополнительных инструментов | Встроенный синтаксический анализатор | Отсутствует |
| Анализ тональности | VADER в отдельном модуле | Нет встроенного | Встроенный |
Как Компьютер "Видит" Слова: Векторизация и Встраивания
Представьте, что мы уже разбили наш текст на слова и очистили его от шума. Но как компьютер, который оперирует числами, может понять смысл этих слов? Ему нужен способ представить слова и целые тексты в числовом формате, сохраняя при этом их семантическое значение. Здесь на сцену выходят методы векторизации и встраивания слов (Word Embeddings) – одни из самых захватывающих и фундаментальных концепций в современном NLP. Мы покажем, как эти методы позволяют нам перевести абстрактные лингвистические единицы в математические векторы, с которыми уже можно работать с помощью алгоритмов машинного обучения.
Традиционные Векторизаторы: CountVectorizer и TfidfVectorizer
Начнем с классики, которая до сих пор активно используется во многих задачах. CountVectorizer из библиотеки Scikit-learn – это самый простой способ превратить текст в числовой вектор. Он создает словарь всех уникальных слов в нашем корпусе текстов и для каждого документа подсчитывает, сколько раз каждое слово встречается. Результатом является матрица, где строки соответствуют документам, а столбцы – словам, а значения – частоте их появления. Это позволяет нам сразу видеть, какие слова наиболее характерны для данного текста.
Однако у CountVectorizer есть недостаток: он не учитывает важность слова. Слово "и" или "в" будет иметь высокую частоту, но при этом не несет особой смысловой нагрузки. Здесь на помощь приходит TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не просто считает частоту слова в документе (TF), но и умножает ее на обратную частоту документа (IDF), которая показывает, насколько редко слово встречается во всем корпусе текстов. Таким образом, слова, которые часто встречаются в одном документе, но редко в других, получают более высокий вес, становясь более значимыми для классификации или поиска. Мы активно используем TF-IDF для задач классификации текстов и извлечения ключевых фраз, где важен не только сам факт наличия слова, но и его уникальность.
Преимущества и недостатки традиционных векторизаторов:
- CountVectorizer:
- Преимущества: Прост в понимании и реализации, хорошо работает для базовых задач.
- Недостатки: Не учитывает семантику, может создавать очень разреженные матрицы, чувствителен к стоп-словам.
Word Embeddings: Word2Vec, GloVe и FastText с Использованием Gensim
Традиционные методы векторизации рассматривают слова как независимые единицы, не учитывая их семантические отношения. Но в реальном языке слова "король" и "королева" связаны, как и "мужчина" и "женщина". Здесь на помощь приходят Word Embeddings – плотные векторные представления слов, которые захватывают их семантические и синтаксические отношения. И библиотека Gensim – наш основной инструмент для работы с ними.
Мы активно используем Word2Vec, разработанный Google, который обучается на большом корпусе текстов и помещает слова с похожим значением близко друг к другу в многомерном векторном пространстве. Таким образом, вектор для "короля" будет похож на вектор для "королевы", а вектор разницы между "королем" и "мужчиной" будет примерно равен вектору разницы между "королевой" и "женщиной"; Это позволяет нам выполнять удивительные вещи, такие как аналогии слов.
GloVe (Global Vectors for Word Representation) – еще один популярный метод, который, в отличие от Word2Vec, учитывает глобальную статистику сопоставления слов. Мы часто экспериментируем с обоими, чтобы найти оптимальное представление для нашей конкретной задачи.
FastText, также разработанный Facebook, является расширением Word2Vec, которое учитывает подсловные единицы (символьные n-граммы). Это делает FastText особенно полезным для работы с редкими словами и языками с богатой морфологией, где многие слова могут быть образованы из общих корней. Он также хорошо справляется с опечатками и словами, которых не было в тренировочном корпусе.
Помимо отдельных слов, мы также работаем с Doc2Vec (расширение Word2Vec), которое позволяет нам получать векторные представления для целых предложений или документов. Это критически важно для задач, где нам нужно сравнивать схожесть документов или классифицировать их по смыслу.
"Язык – это не просто инструмент для общения, это глубокое отражение нашего мышления. И когда мы учим машины понимать этот язык, мы не просто автоматизируем процессы, мы открываем двери к новому уровню взаимодействия между человеком и машиной."
— Йошуа Бенжио, один из пионеров глубокого обучения и NLP.
Векторизация Предложений и Документов: Sentence Transformers и Контекстные Встраивания (BERT, Трансформеры)
Хотя Word Embeddings прекрасны для слов, они не всегда идеально подходят для понимания смысла целых предложений или документов, так как усреднение векторов слов может потерять важный контекст. Здесь в игру вступают более продвинутые методы, которые мы активно используем для сложных задач.
Sentence Transformers – это библиотека, которая позволяет нам легко получать высококачественные векторные представления для целых предложений. Она основана на предварительно обученных трансформерных моделях и оптимизирована для задач, где нужно сравнивать схожесть предложений, например, при поиске дубликатов или создании FAQ. Мы можем взять два предложения, получить их векторы и вычислить косинусное расстояние между ними, чтобы определить, насколько они схожи по смыслу.
Но настоящая революция в NLP произошла с появлением трансформерных архитектур и моделей, таких как BERT (Bidirectional Encoder Representations from Transformers) от Google, и всего семейства моделей, доступных через библиотеку Hugging Face Transformers. Эти модели генерируют контекстные встраивания, что означает, что векторное представление слова зависит от его окружения в предложении. Слово "банк" будет иметь разные векторы в предложениях "Я иду в банк" (финансовое учреждение) и "Я сижу на берегу реки, на банке" (песчаная отмель). Это позволяет нам улавливать тонкие нюансы смысла, что значительно улучшает производительность в широком спектре задач NLP, от распознавания именованных сущностей до машинного перевода и суммаризации.
Сравнение различных подходов к векторизации:
| Метод | Уровень анализа | Основной принцип | Преимущества | Недостатки |
|---|---|---|---|---|
| CountVectorizer/TF-IDF | Слово/Документ | Частота слов | Простота, интерпретируемость | Нет семантики, разреженные векторы |
| Word2Vec/GloVe/FastText | Слово | Соседство слов, статистика | Семантические отношения, плотные векторы | Не учитывают контекст предложения, фиксированный вектор для слова |
| Doc2Vec | Документ | Расширение Word2Vec для документов | Представление смысла всего документа | Сложность обучения, менее точен, чем трансформеры для предложений |
| Sentence Transformers | Предложение | Трансформеры, обученные на парах предложений | Высококачественные векторы предложений, быстрая схожесть | Требуют предварительно обученной модели |
| BERT/Трансформеры | Слово/Предложение/Документ (контекстно) | Многослойные нейронные сети с механизмом внимания | Учитывают контекст, state-of-the-art результаты, универсальность | Высокие вычислительные требования, сложность понимания "черного ящика" |
Основные Задачи NLP: От Распознавания до Понимания
После того как мы научились превращать текст в числовые представления, открывается широчайший спектр задач, которые мы можем решать с помощью NLP. Это сердце нашей работы, где мы применяем различные алгоритмы и модели, чтобы извлекать информацию, классифицировать ее, определять настроения и даже генерировать новый текст. Каждая из этих задач имеет свои уникальные вызовы и требует особого подхода, но все они в конечном итоге направлены на то, чтобы сделать текстовые данные более доступными и понятными для нас и наших систем.
Распознавание Именованных Сущностей (NER)
Одной из наиболее фундаментальных и широко применяемых задач является Распознавание Именованных Сущностей (NER). Цель NER – идентифицировать и классифицировать именованные сущности в тексте по предопределенным категориям, таким как имена людей (PERSON), названия организаций (ORG), географические местоположения (LOC), даты (DATE) и т.д.. Мы используем NER для автоматического извлечения структурированной информации из неструктурированных текстов, будь то новости, юридические документы или медицинские записи.
Нашим основным инструментом для NER является spaCy, который предлагает быстрые и точные предобученные модели. Однако для более сложных или специфических задач, где стандартные модели могут быть недостаточно точны, мы обращаемся к другим подходам. Например, мы используем CRF (Conditional Random Fields) для распознавания сущностей, когда у нас есть размеченные данные и нам нужен более контролируемый подход. А с появлением библиотеки Flair, которая предоставляет state-of-the-art модели для NER, и конечно же трансформерных моделей (например, BERT), мы можем достигать невероятной точности даже в самых сложных сценариях.
Тематическое Моделирование: Поиск Скрытых Тем с Gensim
Представьте, что у вас есть огромная коллекция документов, и вы хотите понять, о чем они в основном говорят, без необходимости читать каждый из них. Здесь на помощь приходит тематическое моделирование – набор алгоритмов, которые позволяют нам обнаруживать абстрактные "темы" в коллекции текстовых документов. Каждая тема представлена набором связанных слов, и каждый документ может быть описан как смесь этих тем.
Мы активно используем библиотеку Gensim для реализации таких моделей, как LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing). LDA – это вероятностная модель, которая предполагает, что каждый документ состоит из смеси тем, а каждая тема – из смеси слов. LSI же использует сингулярное разложение (SVD) для выявления скрытых семантических связей. Мы также сравниваем эти модели с NMF (Non-negative Matrix Factorization) из Scikit-learn, который является не вероятностным, но часто дает сопоставимые результаты. Тематическое моделирование незаменимо для анализа больших корпусов текстов, таких как отзывы клиентов, новостные статьи или исследовательские публикации, помогая нам выявлять скрытые тенденции и интересы.
Классификация Текстов: От Спама до Категоризации Статей
Классификация текстов – одна из самых распространенных задач NLP, где мы присваиваем текстовому документу одну или несколько категорий из предопределенного набора. Это может быть классификация электронной почты как "спам" или "не спам", категоризация новостных статей по темам (спорт, политика, экономика) или определение тональности отзыва.
Мы используем различные подходы для классификации. Для простых задач мы начинаем с классических алгоритмов машинного обучения из Scikit-learn, таких как SVM (Support Vector Machines) или наивный байесовский классификатор, часто используя их в сочетании с TF-IDF векторизацией. Для более сложных и высокопроизводительных задач, особенно когда у нас есть большие объемы данных, мы переходим к нейронным сетям, созданным с помощью PyTorch или TensorFlow. Мы обучаем LSTM-сети или используем трансформерные модели (BERT), которые затем дообучаем (fine-tuning) на наших специфических данных для достижения максимальной точности.
Анализ Тональности (Sentiment Analysis): Понимание Эмоций
Анализ тональности, или Sentiment Analysis, позволяет нам определять эмоциональную окраску текста – является ли он позитивным, негативным или нейтральным. Это мощный инструмент для понимания общественного мнения, анализа отзывов клиентов, мониторинга социальных сетей и даже оценки финансовых новостей.
Мы часто начинаем с простых, но эффективных инструментов, таких как VADER (Valence Aware Dictionary and sEntiment Reasoner), который является правилосообразной моделью, специально разработанной для анализа тональности социальных медиа. Он хорошо справляется с эмодзи, сленгом и даже сарказмом в некоторых случаях. Для более общих задач мы используем встроенный анализ тональности в TextBlob. Однако для глубокого анализа и выявления тонких нюансов, особенно в специализированных областях, мы переходим к обучению собственных моделей на основе машинного обучения или глубоких нейронных сетей, используя трансформерные архитектуры, которые могут улавливать контекст и скрытые намерения.
Суммаризация Текста: Извлечение Сути
В мире избытка информации способность быстро получать суть длинного документа бесценна. Суммаризация текста – это задача создания краткого и связного изложения исходного текста. Мы различаем два основных подхода:
- Экстрактивная суммаризация: Мы извлекаем наиболее важные предложения или фразы из оригинального текста и объединяем их в краткое изложение. Методы вроде TextRank (из библиотеки TextRank) часто используются для этой цели, определяя наиболее "центральные" предложения.
- Абстрактивная суммаризация: Этот более сложный подход предполагает генерацию совершенно нового текста, который передает основную идею исходного документа, но не обязательно содержит его оригинальные фразы. Здесь мы полагаемся на трансформерные модели (например, из Hugging Face), которые могут генерировать связный и осмысленный текст.
Машинный Перевод и Вопросно-Ответные Системы
Эти две задачи являются вершиной сложности в NLP и требуют глубокого понимания языка. Машинный перевод, который мы все знаем по Google Translate, прошел долгий путь от статистических моделей до нейронных сетей. Сегодня трансформерные модели являются стандартом де-факто, позволяя нам строить системы, способные переводить тексты с высокой точностью, сохраняя при этом смысл и стилистику. Мы экспериментируем с точной настройкой предварительно обученных моделей для перевода узкоспециализированных текстов.
Вопросно-ответные системы (QA) – это системы, которые могут отвечать на вопросы, заданные на естественном языке, используя предоставленный текст или базу знаний. Это невероятно сложная задача, требующая не только понимания вопроса, но и способности извлекать правильный ответ из большого объема информации. И снова трансформерные архитектуры, такие как BERT и его производные, играют ключевую роль в разработке современных QA-систем, позволяя нам создавать умных помощников, способных находить нужную информацию в документах.
Глубокое Погружение и Практические Приложения
Теперь, когда мы освоили фундаментальные и основные задачи NLP, пришло время рассмотреть, как эти знания и инструменты применяются в реальном мире. NLP – это не только академическая дисциплина, это мощный инструментарий для решения практических задач, автоматизации процессов и извлечения ценных инсайтов из огромных объемов текстовых данных. Мы переходим к более специализированным и продвинутым темам, которые демонстрируют всю широту применения обработки естественного языка.
Сбор и Подготовка Текстовых Данных: Веб-скрейпинг и Извлечение из PDF
Прежде чем мы сможем анализировать текст, нам нужно его получить; Часто это означает извлечение данных из различных источников. Для веб-страниц нашим незаменимым помощником является библиотека Beautiful Soup. Она позволяет нам парсить HTML и XML документы, легко извлекая нужные текстовые блоки, заголовки, ссылки и другие элементы. Мы используем ее для сбора данных с сайтов, например, для анализа отзывов о продуктах или новостных статей.
Когда дело доходит до документов в формате PDF, задача становится сложнее. Для извлечения текста из PDF-файлов мы применяем библиотеку PyMuPDF. Она предоставляет эффективные инструменты для работы с PDF, позволяя нам не только извлекать текст, но и информацию о его расположении, шрифтах и даже изображениях. Это критически важно, когда мы работаем с юридическими документами, финансовыми отчетами или научными статьями, которые часто распространяются в формате PDF.
Многоязычный NLP: Преодолевая Языковые Барьеры
Мир не ограничивается одним языком, и наши NLP-системы должны быть готовы к работе с многоязычными текстовыми корпусами. Это добавляет значительную сложность, поскольку каждый язык имеет свою уникальную морфологию, синтаксис и семантику. Мы используем несколько инструментов для решения этой задачи:
- Библиотека Polyglot: Она предоставляет широкий спектр функций для многоязычного NLP, включая определение языка, токенизацию, NER, анализ тональности и перевод для многих языков, в т.ч. и для менее распространенных.
- Библиотека Stanza: Разработанная Stanford NLP Group, Stanza предлагает унифицированный интерфейс для обработки более 70 языков. Она включает в себя предобученные нейронные сети для токенизации, POS-теггинга, лемматизации, синтаксического парсинга и NER, что делает ее особенно полезной для языков с богатой морфологией, таких как русский или арабский.
- Обработка нелатинских алфавитов: Работа с такими языками, как китайский, японский или арабский, требует специальных подходов к токенизации и нормализации, поскольку они не используют пробелы для разделения слов. Мы используем специализированные токенизаторы и модели, обученные на этих языках.
Разработка Чат-ботов и Генерация Текста
Создание интеллектуальных систем, способных вести диалог с человеком, является одной из самых захватывающих областей NLP. Мы активно занимаемся разработкой чат-ботов на Python, часто используя Rasa framework. Rasa позволяет нам создавать контекстно-ориентированных ботов, которые могут понимать намерения пользователя, извлекать сущности и генерировать осмысленные ответы. Это требует сочетания понимания естественного языка (NLU) и генерации естественного языка (NLG).
В области генерации текста произошел огромный прорыв с появлением Transformer-моделей, таких как GPT (Generative Pre-trained Transformer). Эти модели способны генерировать высококачественный, связный и креативный текст на основе заданного начального фрагмента. Мы используем их для автоматического создания статей, ответов в чат-ботах, суммаризации и даже для генерации кода. Возможности здесь поистине безграничны.
Специализированный Анализ Текстов и Извлечение Информации
NLP не ограничивается общими задачами; мы также применяем его для анализа очень специфических типов текстов, где требуется глубокое доменное знание:
- Анализ юридических документов: Извлечение ключевых условий, дат, имен сторон, пунктов договора. Мы разрабатываем системы для автоматической категоризации контрактов и обнаружения плагиата.
- Анализ финансовых новостей: Определение тональности финансовых новостей для прогнозирования движения рынка, извлечение названий компаний и экономических показателей.
- Анализ медицинских записей: Извлечение диагнозов, симптомов, названий лекарств, процедур из неструктурированного текста медицинских карт.
- Анализ лог-файлов: Выявление аномалий и паттернов в системных логах с использованием NLP-техник для мониторинга и безопасности.
- Анализ стилистики текстов и определение авторства: Изучение лексического богатства, частотности n-грамм, длины предложений для выявления уникального "почерка" автора.
Для извлечения ключевых фраз и предложений, помимо TextRank, мы также используем RAKE (Rapid Automatic Keyword Extraction), который является эффективным алгоритмом для быстрого извлечения ключевых слов из текста.
Визуализация Текстовых Данных и Оценка Моделей
Понимание текстовых данных и работы наших моделей часто улучшается благодаря визуализации. Мы используем такие инструменты, как Word Clouds для отображения наиболее часто встречающихся слов, Heatmaps для визуализации схожести документов или матриц внимания в трансформерных моделях.
Оценка качества наших NLP-моделей является критически важным этапом. Мы используем различные метрики, такие как F1-score, Precision и Recall для оценки моделей NER и классификации. Для задач суммаризации и машинного перевода используются более сложные метрики, такие как ROUGE и BLEU соответственно. Мы также разрабатываем инструменты для автоматической разметки данных и проверки фактов, чтобы улучшить качество наших обучающих выборок и конечных систем.
Вызовы и Будущее NLP: Что Ждет Нас Впереди
Наш путь в мир NLP полон открытий, но и вызовов. Несмотря на феноменальный прогресс, который мы наблюдаем в последние годы, особенно благодаря глубокому обучению и трансформерным моделям, существует еще множество нерешенных проблем и областей для дальнейшего исследования. Мы, как блогеры и практики, постоянно сталкиваемся с этими вызовами и видим в них новые возможности для инноваций и улучшений.
Проблемы Обработки Неполных и Ошибочных Данных
Реальный мир редко бывает идеальным. Тексты, с которыми мы работаем, часто содержат опечатки, грамматические ошибки, неполные предложения, сленг и специфические сокращения, особенно в социальных сетях или пользовательских отзывах. Модели, обученные на чистых данных, могут плохо справляться с таким "шумом". Мы активно разрабатываем и используем инструменты для проверки грамматики и исправления орфографии, а также для нормализации сленга и пунктуации, чтобы наши системы могли лучше понимать "живой" язык. Библиотеки, такие как Jellyfish, помогают нам сравнивать строки и находить похожие слова, что полезно для исправления ошибок.
Контекст, Сарказм и Глубокое Понимание
Хотя трансформерные модели значительно улучшили понимание контекста, уловить сарказм, иронию или скрытый смысл все еще остается сложной задачей для машин. Анализ тональности в социальных медиа, где люди часто выражают свои мысли в непрямой форме, требует более продвинутых моделей, способных распознавать эти тонкие лингвистические явления; Мы экспериментируем с обучением моделей на больших датасетах, содержащих размеченные примеры сарказма, чтобы улучшить их способность к анализу тональности с учетом сарказма.
Большие Данные и Производительность
Обработка больших текстовых массивов (Big Data NLP) требует значительных вычислительных ресурсов. Обучение сложных трансформерных моделей может занимать дни или даже недели на мощных GPU-кластерах. Мы постоянно ищем способы оптимизации, используя GPU-ускорение для обработки текста и распределенные вычисления. Также растет интерес к обработке текста в режиме реального времени (Streaming NLP), что критически важно для таких приложений, как мониторинг социальных сетей или чат-боты.
Этика и Предвзятость в NLP
Поскольку наши NLP-системы обучаются на огромных объемах человеческого текста, они могут непреднамеренно усвоить и воспроизвести предвзятости, существующие в этих данных. Это серьезная этическая проблема, особенно в таких областях, как анализ резюме, принятие решений в юридической сфере или генерация текста. Мы активно работаем над методами выявления и снижения предвзятости в моделях, чтобы обеспечить справедливость и объективность наших систем. Это включает в себя тщательную проверку данных, использование специализированных алгоритмов и постоянный мониторинг результатов.
Будущее NLP: Мультимодальность и Искусственный Общий Интеллект
Будущее NLP, как мы его видим, лежит в мультимодальности – способности систем понимать и генерировать информацию из различных источников, таких как текст, изображения, аудио и видео. Представьте себе систему, которая может не только читать описание изображения, но и генерировать его, или понимать разговор, одновременно анализируя выражение лица собеседника. Разработка систем распознавания речи (Speech-to-Text) с использованием библиотек вроде Gentle является важным шагом в этом направлении. Конечная цель – это создание искусственного общего интеллекта (AGI), который сможет понимать и взаимодействовать с миром так же, как человек, и NLP является одним из ключевых компонентов на этом пути.
Вот и подходит к концу наше обширное погружение в мир обработки естественного языка на Python. Мы вместе прошли путь от базовой предобработки текста с NLTK и spaCy до сложнейших задач, таких как машинный перевод, генерация текста и создание вопросно-ответных систем с использованием трансформерных архитектур. Мы увидели, как слова превращаются в числа, как скрытые темы выходят на поверхность, и как машины учатся понимать тончайшие оттенки человеческих эмоций.
Мир NLP постоянно развивается, предлагая нам новые инструменты, алгоритмы и вызовы. То, что сегодня кажется фантастикой, завтра становится обыденностью. Мы искренне надеемся, что этот обзор вдохновил вас на собственные эксперименты и исследования. Python с его богатой экосистемой библиотек – от Scikit-learn и Gensim до PyTorch, TensorFlow и Hugging Face – предоставляет нам все необходимое, чтобы стать активными участниками этой захватывающей трансформации. Не бойтесь экспериментировать, задавать вопросы и делиться своими открытиями. Ведь именно так, через совместное обучение и постоянное стремление к новому, мы продолжаем разгадывать язык цифрового мира и строить будущее, где человек и машина говорят на одном языке. На этом статья заканчивается.
Подробнее
| Основы NLTK | SpaCy NER | Word Embeddings | Анализ тональности Python | Трансформеры NLP |
| Тематическое моделирование LDA | Классификация текстов Scikit-learn | Генерация текста GPT | Разработка чат-ботов Rasa | Многоязычный NLP |





