
- Разгадывая Язык Машин: Наш Путеводитель по Магии NLP в Python
- Основы Основания: Первые Шаги в Мире Текста
- NLTK: Наш Надежный Спутник в Предобработке
- Регулярные Выражения: Наш Мастер-Ключ к Очистке Текста
- Превращая Слова в Числа: Векторизация Текста
- От Простого к Сложному: CountVectorizer и TfidfVectorizer
- Word Embeddings: Когда Слова Обретают Смысл
- Библиотека spaCy: Скорость и Точность в Одном Флаконе
- NER с spaCy: Идентификация Ключевых Сущностей
- Синтаксический Парсинг: Разбирая Структуру Предложений
- Глубокое Погружение: Тематическое Моделирование и Классификация
- Gensim: Открывая Скрытые Темы (LDA, LSI)
- Scikit-learn: Наш Выбор для Классификации Текстов
- Эмоции и Смысл: Анализ Тональности и Извлечение Ключевых Фраз
- Анализ Тональности: Понимая Настроение
- Извлечение Ключевых Фраз: Выделяя Главное
- Революция Трансформеров: Новый Уровень NLP
- BERT и Fine-tuning: Сверхточные Решения
- Генерация Текста и Диалоги: От GPT до Чат-ботов
- Практические Приложения и Расширенные Возможности
- Работа с Документами: От PDF до Юридических Текстов
- Многоязычность и Редкие Языки
- Качество Текста и Его Анализ
- Обработка Больших Массивов Данных и Потоков
Разгадывая Язык Машин: Наш Путеводитель по Магии NLP в Python
Привет, дорогие читатели и коллеги-энтузиасты больших данных! Сегодня мы с вами погрузимся в удивительный мир обработки естественного языка (NLP) с помощью Python. Это не просто набор инструментов, это целый арсенал возможностей, который позволяет нам, людям, общаться с машинами на одном языке, понимать их и учить их понимать нас; За многие годы работы с текстами и кодом, мы накопили немало опыта, который хотим передать вам, чтобы вы могли уверенно ориентироваться в этом быстро развивающемся направлении.
Мы часто слышим, что данные – это новая нефть, но тексты – это, пожалуй, самый богатый и самый сложный для обработки вид данных. От анализа отзывов клиентов до создания умных чат-ботов, от перевода документов до поиска скрытых смыслов в огромных массивах информации – NLP открывает двери в невероятные горизонты. В этой статье мы не просто расскажем о популярных библиотеках и алгоритмах, мы поделимся нашим взглядом на то, как эти инструменты работают вместе, создавая мощные и интеллектуальные системы. Приготовьтесь к увлекательному путешествию, ведь мы начинаем!
Основы Основания: Первые Шаги в Мире Текста
Прежде чем мы научим машины "читать" и "понимать", нам нужно научить их хотя бы "видеть" текст. Это означает, что сырые текстовые данные, будь то статья из Википедии или пост в социальной сети, должны быть подготовлены к анализу. Это этап, который мы называем предобработкой, и он является критически важным для успеха любого проекта NLP. Наш опыт показывает, что качество выходных данных напрямую зависит от тщательности предобработки.
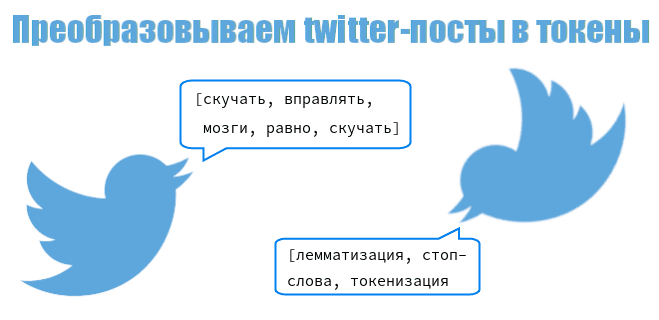
Самые базовые, но при этом невероятно важные операции, с которыми мы сталкиваемся, – это токенизация и стемминг/лемматизация. Представьте, что вы хотите проанализировать книгу: сначала вам нужно разделить её на слова, а затем привести эти слова к их базовой форме, чтобы считать "бежал", "бегущий" и "бег" одной и той же сущностью – "бежать". Для этих целей мы чаще всего обращаемся к библиотеке NLTK, которая является своего рода швейцарским армейским ножом для NLP в Python.
NLTK: Наш Надежный Спутник в Предобработке
NLTK (Natural Language Toolkit) – это одна из старейших и наиболее полных библиотек для работы с человеческим языком. Мы используем её для широкого спектра задач, от простой токенизации до более сложного морфологического анализа. Токенизация – это процесс разбиения текста на более мелкие единицы, называемые токенами, которые обычно являются словами или знаками пунктуации. Для стемминга NLTK предлагает различные алгоритмы, такие как Porter Stemmer или Snowball Stemmer, которые отсекают суффиксы слов, приводя их к "корню".
Однако стемминг имеет свои ограничения: он может создавать несуществующие слова. Например, "красивый" может стать "красив". Здесь на помощь приходит лемматизация, которая использует словарные данные для приведения слова к его базовой (словарной) форме, лемме. Так, "бегущий" превратится в "бежать", а не в "бег". Хотя NLTK предлагает свой лемматизатор (WordNetLemmatizer), для более точной и быстрой лемматизации, особенно для больших корпусов, мы часто прибегаем к spaCy, о которой поговорим чуть позже.
| Операция | Описание | Пример (Исходный текст) | Пример (Результат) |
|---|---|---|---|
| Токенизация | Разбиение текста на слова и пунктуацию. | "Это пример токенизации." | [‘Это’, ‘пример’, ‘токенизации’, ‘.’] |
| Стемминг (Porter) | Приведение слова к его "корню" путём отсечения суффиксов. | "running", "runs", "runner" | [‘run’, ‘run’, ‘runner’] |
| Лемматизация (WordNet) | Приведение слова к его словарной форме. | "better", "goose", "feet" | [‘good’, ‘goose’, ‘foot’] |
Регулярные Выражения: Наш Мастер-Ключ к Очистке Текста
Предобработка текста редко ограничивается только токенизацией и лемматизацией. Сырые данные часто содержат шум: HTML-теги, специальные символы, URL-адреса, эмодзи, сленг, дубликаты и многое другое. Для эффективной очистки текста мы активно используем регулярные выражения (модуль `re` в Python). Они позволяют нам находить и заменять сложные паттерны в строках, будь то удаление всех цифр, приведение текста к нижнему регистру или избавление от лишних пробелов.
Например, если мы анализируем данные, полученные путем веб-скрейпинга (для чего, кстати, отлично подходит Beautiful Soup), нам неизбежно придется сталкиваться с HTML-тегами. Регулярные выражения позволяют нам легко удалить их, оставив только чистый текст. Это фундаментальный навык, который мы освоили в самом начале нашего пути в NLP, и он остается одним из самых востребованных инструментов в нашем арсенале.
Превращая Слова в Числа: Векторизация Текста
Компьютеры не "понимают" слова в том смысле, в каком понимаем их мы. Для них это просто последовательности символов. Чтобы применить к тексту математические модели и алгоритмы машинного обучения, нам необходимо преобразовать слова в числовые векторы. Этот процесс называется векторизацией текста, и он является мостом между человеческим языком и миром алгоритмов. На протяжении нашей практики мы экспериментировали с множеством подходов, каждый из которых имеет свои преимущества.
От Простого к Сложному: CountVectorizer и TfidfVectorizer
Самые простые, но часто эффективные методы векторизации – это CountVectorizer и TfidfVectorizer из библиотеки Scikit-learn. CountVectorizer просто подсчитывает частоту каждого слова в документе. Он создает матрицу, где строки соответствуют документам, а столбцы – уникальным словам в корпусе. Это дает нам представление о том, какие слова присутствуют и как часто, но не учитывает важность слова.
Здесь в игру вступает TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает, как часто слово встречается в документе (TF), но и насколько оно уникально для этого документа по сравнению со всем корпусом (IDF). Слова, которые встречаются часто во многих документах (например, "и", "в", "на"), получают низкий вес, тогда как слова, специфичные для конкретного документа, получают высокий вес. Мы часто используем TF-IDF для задач классификации и поиска ключевых слов, поскольку он отлично выделяет информативные термины.
Word Embeddings: Когда Слова Обретают Смысл
CountVectorizer и TF-IDF имеют одно существенное ограничение: они не улавливают семантические отношения между словами. Для них "кошка" и "собака" так же далеки друг от друга, как "кошка" и "стол". Здесь на помощь приходят Word Embeddings – векторные представления слов, которые улавливают их семантический и синтаксический смысл. Слова с похожим значением будут расположены близко друг к другу в многомерном векторном пространстве.
Мы активно используем модели Word2Vec и GloVe, часто с помощью библиотеки Gensim. Word2Vec, разработанный Google, строит векторы слов, предсказывая контекст слова или само слово по его контексту (Skip-gram и CBOW). GloVe (Global Vectors for Word Representation) от Стэнфорда использует глобальную статистику со-встречаемости слов. Эти эмбеддинги стали настоящим прорывом, позволяя нам решать задачи, требующие понимания смысла, например, поиск синонимов или тематическое моделирование.
Для представления целых предложений и документов мы переходим к Doc2Vec. Этот подход, также реализованный в Gensim, расширяет идеи Word2Vec, создавая векторы не только для слов, но и для всего документа. Это особенно полезно, когда мы хотим сравнить документы по их содержанию или классифицировать их целиком. Когда же речь заходит о более глубоком понимании контекста и работе с редкими словами, мы обращаем внимание на FastText, который генерирует эмбеддинги на уровне символьных n-грамм, что делает его устойчивым к опечаткам и позволяет работать с внесловарными словами.
Библиотека spaCy: Скорость и Точность в Одном Флаконе
Если NLTK – это наш универсальный инструмент, то spaCy – это высокопроизводительный, оптимизированный конвейер для продакшн-уровня. Мы обожаем spaCy за его скорость и точность, особенно когда речь идет о распознавании именованных сущностей (NER) и синтаксическом парсинге. Он поставляется с предварительно обученными моделями для различных языков, что значительно упрощает старт проекта.
NER с spaCy: Идентификация Ключевых Сущностей
Распознавание именованных сущностей (NER) – это задача идентификации и классификации именованных сущностей в тексте, таких как имена людей, организаций, местоположений, дат и денежных величин. spaCy делает это невероятно эффективно. Представьте, что у вас есть тысячи новостных статей, и вам нужно быстро извлечь все упоминания компаний и городов. spaCy справится с этим в считанные секунды, предоставляя нам структурированные данные из неструктурированного текста.
Наш опыт показывает, что NER является краеугольным камнем для многих более сложных задач, таких как извлечение информации, построение графов знаний или автоматическое тегирование контента. Мы также исследовали другие подходы к NER, такие как Conditional Random Fields (CRF) для более кастомных задач и, конечно же, трансформерные модели, которые обеспечивают state-of-the-art точность. Но для быстрой и надежной работы "из коробки" spaCy остается нашим фаворитом.
Синтаксический Парсинг: Разбирая Структуру Предложений
Помимо NER, spaCy также превосходен в синтаксическом парсинге, который позволяет нам понять грамматическую структуру предложения. Мы можем определить отношения между словами, например, кто является подлежащим, кто сказуемым, какие слова являются модификаторами. Это открывает двери для более глубокого анализа текста, например, для извлечения фактов или построения вопросно-ответных систем.
Для языков с богатой морфологией, таких как русский, мы также используем библиотеку Stanza (разработанную Stanford NLP Group), которая предоставляет более продвинутый морфологический анализ, включая POS-теггинг (Part-of-Speech Tagging) и анализ зависимостей. Она часто дает более точные результаты для русского языка по сравнению с базовыми моделями spaCy, хотя и требует больше вычислительных ресурсов.
"Язык – это всего лишь набор привычных звуков и знаков, но именно через него мы строим миры, обмениваемся идеями и понимаем друг друга. Научить машину этому – значит дать ей ключ к человеческому опыту."
— Джон Серль, американский философ, известный работами в области философии языка и философии сознания.
Глубокое Погружение: Тематическое Моделирование и Классификация
После того как мы подготовили текст и векторизовали его, мы можем начать извлекать из него более высокие уровни смысла. Две из наиболее мощных задач, которые мы регулярно решаем, – это тематическое моделирование и классификация текстов. Они позволяют нам понять, о чем идет речь в больших объемах документов, и автоматически распределять их по категориям.
Gensim: Открывая Скрытые Темы (LDA, LSI)
Представьте, что у вас есть огромный архив новостных статей, и вы хотите понять, какие основные темы обсуждаются без ручного чтения каждой из них. Здесь на помощь приходит тематическое моделирование, и библиотека Gensim является нашим основным инструментом для этого. Мы используем её для реализации таких алгоритмов, как Latent Dirichlet Allocation (LDA) и Latent Semantic Indexing (LSI).
LDA – это, пожалуй, самый популярный алгоритм для тематического моделирования. Он предполагает, что каждый документ представляет собой смесь нескольких тем, а каждая тема – это смесь слов. LDA пытается найти эти скрытые темы, анализируя встречаемость слов в документах. LSI, в свою очередь, использует сингулярное разложение (SVD) для выявления скрытых семантических структур. Мы часто сравниваем LDA и NMF (Non-negative Matrix Factorization) для тематического моделирования, чтобы выбрать наиболее подходящий подход для конкретного набора данных, исходя из их интерпретируемости и качества тем.
Тематическое моделирование – это не просто академическая задача. Мы применяем его для анализа текстов отзывов клиентов, чтобы выявить основные проблемы или предпочтения, для категоризации статей по темам, или для анализа финансовых новостей, чтобы понять, какие аспекты рынка обсуждаются.
Scikit-learn: Наш Выбор для Классификации Текстов
Классификация текстов – это задача присвоения документу одной или нескольких категорий. От спам-фильтров до категоризации обращений в службу поддержки – это одна из самых распространенных и ценных задач в NLP. Scikit-learn предоставляет нам богатый набор алгоритмов машинного обучения, которые мы успешно применяем для этой цели.
Мы часто начинаем с простых, но мощных моделей, таких как Наивный Байесовский классификатор или Support Vector Machines (SVM). Они относительно легко обучаються и часто дают отличные результаты, особенно с хорошо векторизованными данными (например, с использованием TF-IDF). Для более сложных задач и больших объемов данных мы переходим к более продвинутым моделям, включая нейронные сети, реализованные с помощью PyTorch или TensorFlow, и, конечно же, трансформерные модели.
-
Подготовка данных: Токенизация, лемматизация, удаление стоп-слов, очистка.
-
Векторизация: Преобразование текста в числовые признаки (TF-IDF, Word Embeddings).
-
Выбор модели: Определение подходящего алгоритма (SVM, Наивный Байес, BERT).
-
Обучение модели: Тренировка классификатора на размеченных данных.
-
Оценка: Измерение производительности модели (Precision, Recall, F1-score).
-
Тонкая настройка: Оптимизация гиперпараметров для улучшения результатов.
Оценка качества NER-моделей или моделей классификации текстов является ключевым этапом. Мы всегда используем метрики, такие как F1-score, Precision и Recall, чтобы объективно оценить, насколько хорошо наша модель справляется с задачей, и избежать смещения в оценке.
Эмоции и Смысл: Анализ Тональности и Извлечение Ключевых Фраз
Текст – это не просто слова, это еще и эмоции, мнения, оценки. Понимание этих нюансов позволяет нам получать гораздо более глубокие инсайты из текстовых данных. Анализ тональности и извлечение ключевых фраз – это две задачи, которые мы регулярно используем для "добычи" ценной информации;
Анализ Тональности: Понимая Настроение
Анализ тональности (Sentiment Analysis) – это задача определения эмоциональной окраски текста: позитивная, негативная или нейтральная. Это невероятно полезно для анализа отзывов клиентов, комментариев в социальных сетях или новостных статей. Мы начинаем с простых, основанных на правилах подходов, таких как VADER (Valence Aware Dictionary and sEntiment Reasoner), который хорошо работает с короткими текстами и социальными медиа благодаря встроенному словарю эмоций;
Библиотека TextBlob также предлагает простой интерфейс для анализа тональности, хотя её возможности более ограничены по сравнению с VADER или моделями машинного обучения. Для более сложных случаев, особенно с учетом сарказма или тонких нюансов языка, мы переходим к моделям машинного обучения, обученным на больших размеченных датасетах. Наш опыт показывает, что анализ тональности финансовых новостей требует специализированных моделей, так как "позитивные" или "негативные" слова в финансовом контексте могут отличаться от обыденного языка. Мы также активно работаем с эмодзи и сленгом в современных текстах, используя кастомные словари и предобученные модели для их корректной интерпретации.
Извлечение Ключевых Фраз: Выделяя Главное
Когда мы сталкиваемся с длинными документами, нам часто нужно быстро понять их основное содержание, выделив ключевые слова или фразы. Для этого мы применяем различные алгоритмы извлечения ключевых фраз. Один из наших любимых инструментов – это RAKE (Rapid Automatic Keyword Extraction), который эффективно идентифицирует ключевые фразы на основе частотности слов и их со-встречаемости.
Еще один мощный подход – TextRank, основанный на алгоритме PageRank, который используется для ранжирования веб-страниц. TextRank строит граф слов или предложений, где ребра представляют собой их связи. Мы используем TextRank не только для извлечения ключевых фраз, но и для суммаризации текста, выделяя наиболее важные предложения. Это позволяет нам быстро получать сводки больших документов, что неоценимо в потоке информации.
Революция Трансформеров: Новый Уровень NLP
Последние годы ознаменовались настоящей революцией в NLP благодаря появлению трансформерных архитектур. Эти модели, такие как BERT, GPT, T5, изменили наше представление о возможностях обработки языка. Мы активно используем библиотеку Hugging Face Transformers, которая предоставляет простой доступ к сотням предварительно обученных моделей и инструментам для их тонкой настройки.
BERT и Fine-tuning: Сверхточные Решения
BERT (Bidirectional Encoder Representations from Transformers) – это мощная модель, способная понимать контекст слова, учитывая все слова в предложении, а не только предыдущие. Мы используем BERT для широкого круга задач: от классификации текстов и распознавания именованных сущностей до вопросно-ответных систем и анализа тональности. Его основное преимущество – способность к "тонкой настройке" (fine-tuning) на конкретную задачу с относительно небольшим объемом размеченных данных, что позволяет достигать state-of-the-art результатов.
Тонкая настройка предварительно обученных моделей стала стандартом де-факто в современном NLP. Мы берем модель, которая уже "видела" огромное количество текста и усвоила общие языковые паттерны, а затем дообучаем её на нашем специфическом наборе данных. Это значительно сокращает время и ресурсы, необходимые для создания высокопроизводительных моделей.
Генерация Текста и Диалоги: От GPT до Чат-ботов
Трансформеры также открыли новую эру в генерации текста. Модели, подобные GPT (Generative Pre-trained Transformer), могут создавать связный, грамматически правильный и даже творческий текст. Мы используем их для автоматического создания статей, генерации описаний продуктов, написания ответов в чат-ботах и даже для генерации кода. Возможности практически безграничны.
Разработка чат-ботов на Python, особенно с использованием фреймворков вроде Rasa, стала гораздо эффективнее благодаря трансформерам. Они позволяют ботам не просто следовать жестким правилам, но и понимать намерения пользователя, вести более естественные диалоги и даже адаптироваться к контексту. Мы также экспериментируем с трансформерными архитектурами для распознавания эмоций в диалогах, что критически важно для создания эмпатичных и полезных ассистентов.
Практические Приложения и Расширенные Возможности
NLP – это не только академические исследования, но и мощный инструмент для решения реальных бизнес-задач. Наш опыт охватывает широкий спектр практических применений, от анализа документов до борьбы с плагиатом.
Работа с Документами: От PDF до Юридических Текстов
Текст часто заперт в различных форматах. Мы используем PyMuPDF для эффективного извлечения текста из PDF-документов, что является первым шагом для их дальнейшего анализа. Для анализа юридических документов, например, контрактов, мы применяем комбинацию NER, извлечения ключевых фраз и тематического моделирования для выявления важных условий, дат и сторон.
Создание систем вопросно-ответных систем (QA) на основе документов – еще одна область, где мы активно работаем. Это позволяет пользователям задавать вопросы на естественном языке и получать точные ответы из больших корпусов документации, что значительно сокращает время на поиск информации.
Многоязычность и Редкие Языки
Мир не ограничивается английским языком. Мы работаем с многоязычными текстовыми корпусами, используя такие библиотеки, как Polyglot, для анализа и обработки текстов на разных языках, включая редкие. Разработка систем машинного перевода на Python, особенно с использованием современных трансформерных моделей, позволяет нам преодолевать языковые барьеры и работать с глобальными данными.
Для русского языка, как уже упоминалось, Stanza предлагает отличные возможности для морфологического анализа и синтаксического парсинга, что критически важно для языков со сложной грамматикой.
Качество Текста и Его Анализ
Качество текста имеет огромное значение. Мы разрабатываем инструменты для проверки грамматики и орфографии, используем библиотеку Jellyfish для сравнения строк и поиска сходства, что полезно для обнаружения плагиата или дубликатов. Анализ лексического богатства и сложности текстов помогает нам оценивать качество письма и адаптировать контент для различных аудиторий.
Мы также используем инструменты для визуализации текстовых данных, такие как Word Clouds для быстрого понимания частотности слов, или Heatmaps для визуализации матриц сходства. Это помогает нам не только анализировать, но и наглядно представлять результаты нашей работы.
Обработка Больших Массивов Данных и Потоков
В современном мире объемы текстовых данных растут экспоненциально. Мы сталкиваемся с необходимостью обработки больших текстовых массивов (Big Data NLP) и текста в режиме реального времени (Streaming NLP). Для этого мы оптимизируем наши пайплайны, используем GPU-ускорение для нейронных сетей и выбираем библиотеки, которые хорошо масштабируются, такие как Gensim для тематического моделирования больших корпусов.
Разработка инструментов для автоматической разметки данных также является важной частью нашей работы, поскольку высококачественные размеченные данные – это основа для обучения мощных моделей машинного обучения.
Наше путешествие по миру NLP в Python было долгим и насыщенным, но мы надеемся, что смогли поделиться с вами частью нашего опыта и вдохновить на собственные исследования. От базовой предобработки с NLTK до создания интеллектуальных систем с помощью трансформеров Hugging Face – мы увидели, как Python предоставляет нам мощный и гибкий набор инструментов для работы с человеческим языком. Способность машин понимать, генерировать и анализировать текст открывает двери для невероятных инноваций во всех сферах – от бизнеса и науки до искусства и повседневной жизни.
Помните, что мир NLP постоянно развивается. Новые модели и подходы появляются регулярно, и наша задача – оставаться в курсе событий, экспериментировать и применять самые эффективные решения. Мы верим, что каждый из вас может внести свой вклад в эту захватывающую область. Начните с малого, выберите одну из библиотек или задач, о которых мы говорили, и погрузитесь в неё. Практика – ключ к мастерству. Удачи в ваших NLP-приключениях, и до новых встреч на страницах нашего блога!
Подробнее
| NLTK основы | spaCy NER | Gensim LDA | Scikit-learn классификация | Word2Vec Gensim |
| Sentiment Analysis VADER | Трансформеры Hugging Face | Doc2Vec документы | Регулярные выражения Python | FastText редкие слова |







