
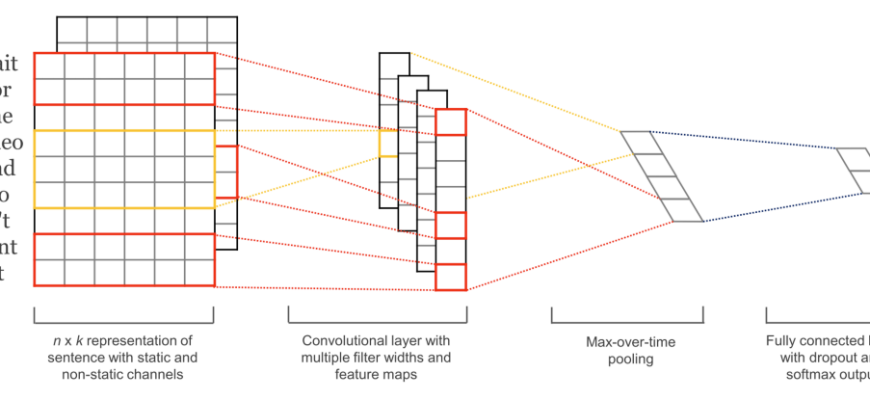
- Разгадывая Язык Машин: Наше Путешествие в Мир NLP на Python
- Основы Предобработки Текста: Токенизация, Стемминг и Лемматизация
- Токенизация: Разделяй и Властвуй
- Стемминг и Лемматизация: Ключ к Единообразию
- Регулярные Выражения (re) в Предобработке Текста
- Ключевые Библиотеки и Инструменты: Наш Арсенал NLP
- SpaCy: Скорость, NER и Синтаксический Парсинг
- От Тематического Моделирования до Векторов Слов: Gensim и Word Embeddings
- Тематическое Моделирование с Gensim (LDA, LSI)
- Word Embeddings: Word2Vec и GloVe с Использованием Gensim
- Scikit-learn: Стандарт для Классификации Текстов
- Разработка Собственных Векторизаторов Текста (CountVectorizer, TfidfVectorizer)
- TextBlob: Простота и Быстрый Анализ
- Beautiful Soup: Добыча Текста из Сети
- Stanza (StanfordNLP): Для Языков с Богатой Морфологией
- Продвинутые Техники NLP: Глубже в Смысл
- Трансформеры (Hugging Face): Революция в NLP
- Анализ Тональности (Sentiment Analysis): Понять Эмоции
- Разработка Систем Вопросно-ответных Систем (QA)
- Разработка Систем Суммаризации Текста
- Применение PyTorch/TensorFlow для Создания Нейросетей NLP
- Тонкая Настройка (Fine-tuning) Предварительно Обученных Моделей
- Векторизация Предложений и Документов (Doc2Vec, Sentence Transformers)
- Практические Приложения и Вызовы: NLP в Реальном Мире
- Анализ Текстов Отзывов Клиентов
- Работа с Эмодзи и Сленгом в Современных Текстах
- Обработка Неполных и Ошибочных Данных
- Инструменты для Визуализации Текстовых Данных
- Обработка Многоязычных Текстовых Корпусов (Polyglot)
- Разработка Чат-ботов на Python (Rasa framework)
- Анализ Стилистики Текстов (Авторский Почерк)
- Разработка Систем Обнаружения Плагиата
- Обработка Больших Текстовых Массивов (Big Data NLP)
- Оценка Качества NER-моделей (F1-score, Precision, Recall)
- Генерация Текста с Transformer-моделями (GPT)
Разгадывая Язык Машин: Наше Путешествие в Мир NLP на Python
Привет, дорогие читатели и коллеги-энтузиасты! Сегодня мы отправляемся в захватывающее путешествие по бескрайним просторам обработки естественного языка, или NLP (Natural Language Processing). Это не просто очередная техническая статья; это наш личный опыт, наши открытия и наши рекомендации, основанные на многих часах работы с текстами, кодом и, конечно же, Python. Мы постараемся показать вам, как мощные библиотеки и фреймворки превращают горы неструктурированного текста в ценные инсайты, помогая машинам "понимать" наш человеческий язык.
Наш мир переполнен текстами: электронные письма, сообщения в социальных сетях, новостные статьи, научные публикации, отзывы клиентов. Без инструментов NLP вся эта информация оставалась бы просто набором символов, недоступным для автоматического анализа и понимания. Но благодаря достижениям в этой области, мы можем не только обрабатывать, но и интерпретировать, генерировать и даже переводить тексты, открывая двери для совершенно новых приложений и возможностей. Мы увидим, как можно начать с самых азов – токенизации и стемминга – и дойти до вершин современных трансформерных моделей, способных творить настоящие чудеса.
Основы Предобработки Текста: Токенизация, Стемминг и Лемматизация
Прежде чем машина сможет "понять" текст, его необходимо подготовить. Этот этап, известный как предобработка, является фундаментом любого NLP-проекта. Мы начинаем с того, что разбиваем текст на более мелкие, осмысленные единицы, а затем приводим слова к их базовым формам, чтобы избежать избыточности и повысить эффективность анализа.
Токенизация: Разделяй и Властвуй
Токенизация – это процесс разделения текста на отдельные "токены", которые могут быть словами, фразами, символами или даже предложениями. Это первый и один из самых важных шагов. Без правильной токенизации все последующие этапы анализа могут быть ошибочными. Мы часто используем библиотеку NLTK (Natural Language Toolkit) для этих целей, благодаря её простоте и эффективности.
Например, предложение "Машины понимают язык!" может быть токенизировано в список слов: [‘Машины’, ‘понимают’, ‘язык’, ‘!’]. NLTK предлагает различные токенизаторы, включая токенизаторы по словам (`word_tokenize`) и по предложениям (`sent_tokenize`), что даёт нам гибкость в зависимости от задачи. Мы обнаружили, что для большинства стандартных задач `word_tokenize` из NLTK является отличной отправной точкой.
Стемминг и Лемматизация: Ключ к Единообразию
После токенизации мы сталкиваемся с проблемой вариативности слов. Слова "бежать", "бежит", "бегал" – все они относятся к одному и тому же корню, но выглядят по-разному. Здесь на помощь приходят стемминг и лемматизация.
Стемминг – это процесс обрезания окончаний слов, чтобы привести их к общей "основе" или "корню" (stem). Он работает по эвристическим правилам и часто не учитывает морфологию языка, что может приводить к созданию не существующих в языке слов. Например, "красивый" и "красота" могут быть приведены к "красив". В NLTK мы часто используем стеммеры, такие как PorterStemmer или SnowballStemmer (который поддерживает русский язык).
Лемматизация – более сложный и точный процесс. Она стремится привести слово к его словарной или канонической форме – лемме (lemma). В отличие от стемминга, лемматизация использует словарь и морфологический анализ, чтобы убедиться, что полученная форма является реальным словом. Например, "бежал", "бежит", "бегут" будут приведены к "бежать". Для лемматизации мы часто обращаемся к библиотекам, таким как spaCy или `pymorphy2` для русского языка, которые предлагают значительно более качественные результаты, чем простые стеммеры.
Мы всегда рекомендуем выбирать лемматизацию вместо стемминга, когда точность имеет решающее значение, несмотря на то, что лемматизация обычно более ресурсоёмка;
| Метод | Описание | Примеры | Преимущества | Недостатки |
|---|---|---|---|---|
| Токенизация | Разделение текста на отдельные единицы (токены). | "Язык Python" -> [‘Язык’, ‘Python’] | Основа для дальнейшей обработки. | Может быть сложной для языков без четких разделителей. |
| Стемминг | Удаление суффиксов и окончаний для получения "корня" слова. | "работает", "работать" -> "работ" | Быстрый, уменьшает размер словаря. | Может создавать несуществующие слова, терять смысл. |
| Лемматизация | Приведение слова к его словарной форме (лемме). | "лучший", "хорошо" -> "хороший" | Сохраняет смысл слова, более точная. | Медленнее, требует словарей и морфологического анализа. |
Регулярные Выражения (re) в Предобработке Текста
Регулярные выражения, или "регулярки", – это мощный инструмент для поиска, замены и извлечения паттернов из текста. В NLP они незаменимы для очистки данных: удаления HTML-тегов, ссылок, специальных символов, чисел или избыточных пробелов. Мы часто используем модуль `re` в Python для создания пользовательских правил предобработки, которые идеально подходят для специфических задач.
Например, чтобы удалить все HTML-теги из текста, мы могли бы использовать `re.sub(r'<.*?>’, », text)`. Или, чтобы найти все email-адреса, `re.findall(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}’, text)`. Гибкость регулярок позволяет нам справляться с практически любыми задачами по очистке и форматированию текста, делая данные пригодными для дальнейшего анализа.
Ключевые Библиотеки и Инструменты: Наш Арсенал NLP
В арсенале современного NLP-специалиста есть множество инструментов, каждый из которых лучше всего подходит для определённых задач. Мы собрали те, которые стали нашими верными спутниками в работе с текстом.
SpaCy: Скорость, NER и Синтаксический Парсинг
Когда речь заходит о быстрой и эффективной обработке текста, особенно на больших объёмах, мы сразу вспоминаем spaCy. Эта библиотека написана на Cython, что делает её невероятно быстрой. Она поставляется с предварительно обученными моделями для различных языков, что позволяет нам сразу же приступить к работе без длительного обучения.
Что особенно ценно в spaCy, так это её возможности по:
- Распознаванию именованных сущностей (NER): spaCy может автоматически находить и классифицировать сущности в тексте, такие как имена людей, организации, местоположения, даты и денежные суммы. Это критически важно для извлечения информации.
- Синтаксическому парсингу: Библиотека строит дерево зависимостей для каждого предложения, показывая грамматические связи между словами. Это позволяет нам понять структуру предложения и роли слов в нём, что открывает путь к более глубокому семантическому анализу.
- Лемматизации и POS-теггингу: Она предоставляет точную лемматизацию и определяет часть речи (Part-of-Speech, POS) для каждого слова, что является неотъемлемой частью предобработки.
Мы активно используем spaCy в проектах, где нужна высокая производительность и надёжный NER, например, для анализа юридических документов или потоков новостей.
От Тематического Моделирования до Векторов Слов: Gensim и Word Embeddings
Библиотека Gensim – наш выбор, когда речь идёт о работе с неструктурированными текстовыми данными, особенно для задач тематического моделирования и создания векторных представлений слов. Она оптимизирована для обработки больших корпусов и является очень эффективной.
Тематическое Моделирование с Gensim (LDA, LSI)
Тематическое моделирование позволяет нам автоматически обнаруживать скрытые "темы" в большом наборе документов. Это невероятно полезно, когда нужно понять основное содержание корпуса текста без ручного чтения каждого документа.
ЛSI (Latent Semantic Indexing): Один из первых методов, использующий сингулярное разложение для выявления латентных семантических связей между словами и документами.
LDA (Latent Dirichlet Allocation): Более современный и популярный алгоритм, который предполагает, что каждый документ является смесью нескольких тем, а каждая тема – смесью нескольких слов. LDA даёт более интерпретируемые темы.
Мы используем тематическое моделирование для анализа отзывов клиентов, чтобы понять, какие аспекты продукта или услуги чаще всего обсуждаются, или для категоризации новостных статей.
Word Embeddings: Word2Vec и GloVe с Использованием Gensim
Одной из самых революционных идей в NLP стало создание векторных представлений слов, или Word Embeddings. Эти представления позволяют нам кодировать семантическое значение слова в виде многомерного вектора, где слова со схожим значением располагаются близко друг к другу в векторном пространстве.
Word2Vec: Разработанный Google, этот алгоритм (с двумя архитектурами: Skip-gram и CBOW) учится генерировать векторные представления слов, предсказывая контекст слова или само слово по его контексту.
GloVe (Global Vectors for Word Representation): Разработанный Stanford, GloVe объединяет преимущества методов, основанных на локальном контексте (как Word2Vec), с методами, основанными на глобальной матрице коокуррентности слов.
Gensim предоставляет удобные инструменты для обучения собственных моделей Word2Vec и GloVe, а также для загрузки предварительно обученных моделей. Мы активно применяем Word Embeddings для задач, где необходимо сравнивать слова по смыслу, например, для поиска синонимов, рекомендательных систем или улучшения качества классификации текстов.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
– Рита Мэй Браун
Эта цитата прекрасно отражает суть нашего стремления – понять язык, чтобы понять культуру, общество и даже индивидуальные мысли, стоящие за текстом. В NLP мы строим эти "дорожные карты" для машин.
Scikit-learn: Стандарт для Классификации Текстов
Когда задача сводится к категоризации или классификации текстовых данных, Scikit-learn становится нашим незаменимым инструментом. Это универсальная библиотека для машинного обучения, которая предлагает широкий спектр алгоритмов, включая те, что идеально подходят для NLP.
Мы используем Scikit-learn для:
- Классификации текстов: Например, определение спама, категоризация новостей по темам, или определение тональности. Популярные алгоритмы включают Наивный Байесовский классификатор, Метод Опорных Векторов (SVM), Логистическую Регрессию.
- Создания собственных векторизаторов текста: Scikit-learn предоставляет такие классы, как `CountVectorizer` и `TfidfVectorizer`, которые преобразуют текст в числовые векторы.
Разработка Собственных Векторизаторов Текста (CountVectorizer, TfidfVectorizer)
Прежде чем применить алгоритмы машинного обучения, текст должен быть преобразован в числовой формат. Это задача векторизации.
CountVectorizer: Создаёт матрицу, где каждая строка представляет документ, а каждый столбец – уникальное слово в корпусе. Значение в ячейке – это количество раз, сколько слово встречается в документе.
TfidfVectorizer (Term Frequency-Inverse Document Frequency): Более продвинутый метод, который не только учитывает частоту слова в документе (TF), но и его редкость во всём корпусе (IDF). Слова, которые часто встречаются в одном документе, но редко в других, получают более высокий вес, что делает их более значимыми.
Мы часто начинаем с TF-IDF, так как он обычно даёт лучшие результаты, чем простой подсчёт частот, особенно когда нужно выделить наиболее характерные слова для каждого документа;
TextBlob: Простота и Быстрый Анализ
Для быстрых и простых задач NLP, таких как анализ тональности, извлечение ключевых фраз или перевод, мы иногда обращаемся к библиотеке TextBlob. Она построена на основе NLTK и Pattern, предоставляя удобный API для базовых операций.
TextBlob позволяет нам:
- Легко проводить анализ тональности (позитивный, негативный, нейтральный).
- Извлекать существительные фразы.
- Определять язык текста и переводить его.
Это отличный инструмент для быстрого прототипирования или для тех, кто только начинает свой путь в NLP и хочет получить результаты без глубокого погружения в детали. Однако для более сложных и высокопроизводительных задач мы обычно выбираем более мощные и специализированные библиотеки.
Beautiful Soup: Добыча Текста из Сети
Прежде чем мы сможем анализировать текст, нам нужно его получить. В современном мире большая часть текстовых данных находится в интернете. Для извлечения текста с веб-страниц мы используем библиотеку Beautiful Soup. Она идеально подходит для веб-скрейпинга, позволяя нам парсить HTML и XML документы и извлекать нужные фрагменты текста.
Мы используем Beautiful Soup для:
- Извлечения статей из блогов и новостных сайтов.
- Сбора отзывов клиентов с различных платформ.
- Получения данных для обучения наших моделей.
Это первый шаг в работе с "живыми" данными из интернета, и без него многие наши проекты просто не смогли бы начаться.
Stanza (StanfordNLP): Для Языков с Богатой Морфологией
Когда мы работаем с языками, имеющими сложную морфологию, такими как русский, арабский или финский, стандартные инструменты могут оказаться недостаточно эффективными. Здесь на помощь приходит Stanza (ранее известная как StanfordNLP). Эта библиотека от Стэнфордского университета предоставляет полный набор инструментов для NLP, включая:
- Токенизацию с учётом особенностей языка.
- Многоязычный POS-теггинг и лемматизацию.
- Синтаксический парсинг зависимостей.
- Распознавание именованных сущностей (NER).
Stanza выделяется своей точностью и поддержкой множества языков, что делает её незаменимой для наших проектов, требующих глубокого лингвистического анализа неанглийских текстов. Мы ценим её за надёжность и высокое качество предварительно обученных моделей.
Продвинутые Техники NLP: Глубже в Смысл
После освоения основ, мы переходим к более сложным задачам, которые требуют более глубокого понимания языка и использования передовых алгоритмов.
Трансформеры (Hugging Face): Революция в NLP
Последние несколько лет принесли настоящую революцию в NLP с появлением архитектуры Трансформеров. Эти модели, такие как BERT, GPT, RoBERTa и многие другие, изменили наше представление о том, на что способны машины в работе с языком. Библиотека Hugging Face Transformers стала де-факто стандартом для работы с этими моделями, предоставляя доступ к тысячам предварительно обученных моделей и удобный API для их использования и тонкой настройки.
Мы используем трансформеры для:
- Сложных задач классификации текста: С их помощью мы достигаем беспрецедентной точности в определении тональности, категоризации документов или обнаружении спама.
- Распознавания именованных сущностей (NER): Трансформеры значительно превосходят традиционные методы в извлечении сущностей из текста.
- Вопросно-ответных систем (QA): Модели, такие как BERT, могут находить ответы на вопросы в заданном тексте с высокой точностью.
- Генерации текста: Модели GPT-подобных архитектур способны генерировать связный и осмысленный текст, что открывает двери для автоматического написания статей, создания чат-ботов и других креативных приложений.
Работа с Hugging Face Transformers требует определённых знаний, но результаты, которые мы получаем, стоят затраченных усилий. Это будущее NLP, и мы активно его исследуем.
Анализ Тональности (Sentiment Analysis): Понять Эмоции
Анализ тональности, или сентимент-анализ, позволяет нам определить эмоциональную окраску текста – является ли он позитивным, негативным или нейтральным. Это критически важно для бизнеса, который хочет понять, что клиенты думают об их продуктах или услугах.
Мы используем различные подходы:
- VADER (Valence Aware Dictionary and sEntiment Reasoner): Этот лексический и основанный на правилах инструмент отлично подходит для анализа тональности текстов из социальных сетей. Он учитывает не только слова, но и пунктуацию, использование заглавных букв и эмодзи, что делает его очень чувствительным к нюансам разговорной речи.
- Модели на основе машинного обучения и глубокого обучения: Для более сложных задач мы обучаем собственные модели классификации тональности с использованием Scikit-learn или трансформеров из Hugging Face.
- Flair: Эта библиотека предлагает state-of-the-art модели для анализа тональности, NER и других задач, часто превосходя по точности VADER, особенно для более длинных и формальных текстов.
Анализ тональности сообщений в социальных сетях, отзывов о продуктах и финансовых новостей – это лишь некоторые из областей, где мы успешно применяем эти методы.
Разработка Систем Вопросно-ответных Систем (QA)
Создание систем, способных отвечать на вопросы, – одна из самых амбициозных задач в NLP. Мы работаем над двумя основными типами QA-систем:
- Экстрактивные QA-системы: Эти системы находят ответ на вопрос непосредственно в предоставленном тексте. Трансформеры, такие как BERT, показали выдающиеся результаты в этой области, идентифицируя точный спан текста, содержащий ответ.
- Абстрактивные QA-системы: Более сложные системы, которые генерируют новый ответ, а не просто извлекают его из текста. Это требует более продвинутых генеративных моделей.
Мы применяем эти системы для создания внутренних баз знаний, где пользователи могут быстро получать ответы на свои вопросы из обширных корпоративных документов.
Разработка Систем Суммаризации Текста
В мире, переполненном информацией, способность быстро извлекать суть длинных документов становится критически важной. Суммаризация текста позволяет нам автоматически создавать краткие изложения.
Экстрактивная суммаризация: Идентифицирует наиболее важные предложения или фразы из исходного текста и объединяет их для формирования резюме. Методы, такие как TextRank, часто используются здесь.
Абстрактивная суммаризация: Генерирует совершенно новый текст, который передаёт основную идею исходного документа, но не обязательно содержит его оригинальные предложения. Это более сложная задача, требующая генеративных моделей, часто на основе трансформеров.
Мы разрабатываем такие системы для автоматического создания аннотаций к статьям, сводок новостей или резюме длинных отчётов.
Применение PyTorch/TensorFlow для Создания Нейросетей NLP
Для тех задач, которые требуют максимальной гибкости и контроля над архитектурой модели, мы обращаемся к фреймворкам глубокого обучения, таким как PyTorch и TensorFlow. Эти фреймворки позволяют нам строить, обучать и развёртывать собственные нейронные сети для NLP с нуля.
Мы используем их для:
- Создания пользовательских архитектур для специфических задач (например, LSTM-сети для анализа последовательностей).
- Тонкой настройки предварительно обученных моделей трансформеров на наших собственных данных.
- Разработки систем машинного перевода или генерации текста.
Хотя это требует более глубоких знаний в глубоком обучении, возможности, которые они предоставляют, безграничны. Особенно мы ценим PyTorch за его "питонический" стиль и удобство отладки.
Тонкая Настройка (Fine-tuning) Предварительно Обученных Моделей
Одним из самых мощных подходов в современном NLP является тонкая настройка предварительно обученных моделей. Вместо того чтобы обучать модель с нуля на огромных массивах данных, мы берём уже существующую, мощную модель (например, BERT или GPT), которая уже "понимает" язык, и дообучаем её на небольшом, специфичном для нашей задачи наборе данных.
Это позволяет нам:
- Достигать высокой точности даже с относительно небольшим объёмом размеченных данных.
- Значительно сокращать время и вычислительные ресурсы, необходимые для обучения.
- Адаптировать общие языковые модели к узкоспециализированным доменам (например, к юридическим текстам или медицинским записям).
Мы активно используем этот подход, особенно с библиотекой Hugging Face Transformers, для создания высокоэффективных моделей для наших клиентов.
Векторизация Предложений и Документов (Doc2Vec, Sentence Transformers)
Хотя Word Embeddings отлично подходят для слов, часто нам нужно векторное представление целых предложений или документов. Здесь на помощь приходят:
Doc2Vec (Paragraph Vector): Расширение Word2Vec, которое генерирует векторные представления для целых документов или абзацев. Это позволяет нам сравнивать документы по смыслу, находить похожие статьи или кластеризовать их.
Sentence Transformers: Это более современный подход, основанный на трансформерных моделях, который позволяет создавать высококачественные векторные представления предложений. Они особенно эффективны для задач поиска семантически похожих предложений, кластеризации и семантического поиска.
Мы используем эти методы для построения систем рекомендаций документов, анализа дубликатов текста или для повышения точности информационного поиска.
Практические Приложения и Вызовы: NLP в Реальном Мире
Теперь, когда мы рассмотрели основные инструменты и методы, давайте посмотрим, как мы применяем их для решения реальных задач и с какими вызовами сталкиваемся.
Анализ Текстов Отзывов Клиентов
Одна из наиболее востребованных областей применения NLP – это анализ отзывов клиентов. Это позволяет компаниям понять настроения потребителей, выявить сильные и слабые стороны продуктов, а также оперативно реагировать на проблемы.
Мы используем:
- Анализ тональности для определения общей эмоциональной окраски отзывов.
- Тематическое моделирование (LDA) для выявления основных тем, обсуждаемых в отзывах (например, "цена", "качество обслуживания", "доставка").
- Извлечение ключевых фраз (RAKE, TextRank) для быстрого понимания наиболее важных аспектов, упоминаемых клиентами.
- NER для извлечения названий продуктов, мест или имён сотрудников, упомянутых в отзывах.
Это позволяет нам предоставлять бизнесу глубокие инсайты о клиентском опыте и помогать принимать обоснованные решения.
Работа с Эмодзи и Сленгом в Современных Текстах
Современные тексты, особенно в социальных сетях, полны эмодзи, сокращений, сленга и неформального языка. Обработка таких данных представляет собой уникальный вызов.
Мы разработали методы для:
- Нормализации сленга: Создание словарей сленговых выражений и их стандартизированных аналогов.
- Интерпретации эмодзи: Преобразование эмодзи в текстовые описания (например, ❤️ в "красное сердце") или использование специализированных моделей тональности, обученных на текстах с эмодзи.
- Обработки опечаток и грамматических ошибок: Использование библиотек, таких как `TextBlob` или пользовательских алгоритмов для исправления распространённых ошибок.
Это помогает нам не терять ценную информацию, содержащуюся в неформальных текстах, и повышать точность анализа.
Обработка Неполных и Ошибочных Данных
Реальные данные редко бывают чистыми и идеальными. Мы постоянно сталкиваемся с неполными записями, опечатками, некорректным форматированием и пропусками. Наш подход к обработке таких "грязных" данных включает:
- Очистка данных: Удаление HTML-тегов, лишних пробелов, специальных символов с использованием регулярных выражений.
- Нормализация: Приведение текста к нижнему регистру, исправление опечаток.
- Обработка пропущенных значений: Методы заполнения или удаления записей с отсутствующими данными.
Мы понимаем, что качество входных данных напрямую влияет на качество выходных результатов, поэтому уделяем этому этапу пристальное внимание.
Инструменты для Визуализации Текстовых Данных
Визуализация помогает нам быстро понять основные паттерны и инсайты в текстовых данных. Мы активно используем:
- Облака слов (Word Clouds): Для визуализации наиболее часто встречающихся слов, что даёт быстрое представление о содержании корпуса;
- Тепловые карты (Heatmaps): Для отображения корреляций между словами или темами.
- Графики распределения частот: Для анализа частотности слов и N-грамм.
Эти инструменты делают результаты нашего анализа более доступными и понятными для неспециалистов.
Обработка Многоязычных Текстовых Корпусов (Polyglot)
Всё чаще мы сталкиваемся с необходимостью работать с текстами на разных языках. Библиотека Polyglot – один из наших инструментов для мультиязычного NLP. Она предоставляет функционал для:
- Определения языка.
- Токенизации, POS-теггинга и NER для множества языков.
- Перевода текста.
Для более глубокого многоязычного анализа мы также используем мультиязычные модели трансформеров, такие как mBERT или XLM-R, которые способны понимать и обрабатывать текст на десятках языков одновременно.
Разработка Чат-ботов на Python (Rasa framework)
Чат-боты стали повсеместными, и мы активно участвуем в их разработке. Для создания сложных, контекстно-ориентированных чат-ботов мы часто используем фреймворк Rasa. Rasa позволяет нам:
- Создавать диалоговые системы, способные понимать намерения пользователя и управлять диалогом.
- Интегрировать собственные модели NLP для улучшения понимания естественного языка (NLU).
- Развёртывать ботов на различных платформах (веб, мессенджеры).
Это позволяет нам создавать интеллектуальных ассистентов для автоматизации поддержки клиентов, внутренних коммуникаций и других задач.
Анализ Стилистики Текстов (Авторский Почерк)
Иногда нам нужно не только понять содержание текста, но и определить его автора или выявить уникальные стилистические особенности. Это область стилометрии.
Мы используем:
- Анализ частотности слов и N-грамм: Определённые слова или последовательности слов могут быть характерными для конкретного автора.
- Лексическое богатство: Измерение разнообразия используемой лексики.
- Анализ синтаксических структур: Использование spaCy для извлечения паттернов в построении предложений.
- Векторизация текста: Сравнение векторных представлений документов для поиска сходства в стиле.
Эти методы применяются в криминалистике, литературоведении и для обнаружения плагиата.
Разработка Систем Обнаружения Плагиата
Обнаружение плагиата – это задача по поиску сходства между текстами. Мы подходим к этой задаче, используя различные методы:
- Сравнение строк (Jellyfish, Textdistance): Для оценки сходства на уровне символов или слов.
- Векторизация документов (Doc2Vec, TF-IDF): Преобразование документов в векторы и измерение косинусного сходства между ними.
- Поиск N-грамм: Идентификация совпадающих последовательностей слов между документами.
Эти системы помогают в образовании, журналистике и научных исследованиях.
Обработка Больших Текстовых Массивов (Big Data NLP)
Работа с петабайтами текстовых данных требует особых подходов и инструментов. Мы используем:
- Распределённые вычисления: Интеграция с платформами, такими как Apache Spark, для параллельной обработки данных.
- Оптимизированные библиотеки: Такие как Gensim, spaCy, которые эффективно работают с большими объёмами данных.
- GPU-ускорение: Для обучения и инференса сложных моделей глубокого обучения.
Масштабируемость является ключевым фактором, когда мы работаем с Big Data NLP, и мы постоянно ищем способы оптимизировать наши процессы.
Оценка Качества NER-моделей (F1-score, Precision, Recall)
В NLP, как и в любом машинном обучении, очень важно уметь оценивать качество наших моделей. Для NER мы используем стандартные метрики:
- Precision (Точность): Доля правильно идентифицированных сущностей среди всех, которые модель пометила как сущности.
- Recall (Полнота): Доля правильно идентифицированных сущностей среди всех реальных сущностей в тексте.
- F1-score: Гармоническое среднее Precision и Recall, которое даёт сбалансированную оценку качества.
Эти метрики помогают нам понять, насколько хорошо наша модель справляется с задачей распознавания сущностей и где её можно улучшить.
Мир NLP постоянно развивается, и мы стараемся быть на острие этих изменений.
Генерация Текста с Transformer-моделями (GPT)
Одной из самых захватывающих областей является генерация текста с использованием таких моделей, как GPT. Эти модели способны создавать текст, который практически неотличим от написанного человеком. Мы используем их для:
- Автоматического написания статей, описаний продуктов, маркетинговых текстов.
- Генерации ответов в чат-ботах для более естественного диалога.
- Творческого письма и создания контента.
Возможности здесь безграничны, и мы только начинаем осознавать их полный потенциал.
Наше путешествие по миру NLP на Python – это непрерывный процесс обучения и открытий. От базовой токенизации до продвинутых трансформерных моделей, каждый инструмент и метод открывает новые горизонты для понимания и взаимодействия с человеческим языком. Мы надеемся, что наш опыт и рекомендации помогут вам в ваших собственных проектах и вдохновят на дальнейшие исследования.
Помните, что NLP – это не только про код и алгоритмы, но и про глубокое понимание лингвистики, контекста и человеческого фактора. Именно это сочетание делает область такой увлекательной и перспективной. Мы верим, что с каждым днём машины будут всё лучше понимать нас, и это открывает путь к созданию по-настоящему интеллектуальных систем, способных изменить наш мир к лучшему. Спасибо, что были с нами в этом приключении!
Подробнее
| Токенизация NLTK | NER SpaCy | Тематическое моделирование LDA | Word Embeddings Gensim | Классификация Scikit-learn |
| Анализ тональности VADER | Трансформеры Hugging Face | Суммаризация текста | Чат-боты Rasa | Doc2Vec |





