
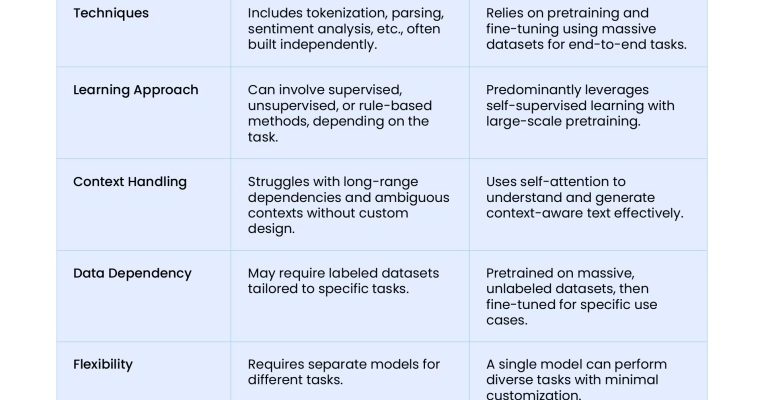
- Разгадывая Язык: Наш Глубокий Дайв в Мир NLP с Python
- Фундамент NLP: Предобработка Текста – Наш Первый Шаг к Пониманию
- Наши Инструменты для Предобработки
- Могучие Библиотеки: Наши Рабочие Лошадки в Мире NLP
- NLTK и SpaCy: От Азов до Глубин
- Gensim и Scikit-learn: Раскрываем Скрытые Смыслы
- TextBlob и Другие Помощники
- От Слов к Числам: Векторизация и Эмбеддинги — Как Мы Учим Машины "Чувствовать" Слова
- Классические Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: Погружение в Смысл
- От Слов к Документам: Doc2Vec и Контекстные Встраивания
- Революция Трансформеров: Наши Открытия в Глубоком NLP
- BERT, GPT и Другие Гиганты
- PyTorch/TensorFlow и LSTM: Когда Нужен Полный Контроль
- Прикладной NLP: От Анализа к Интеллектуальным Решениям
- Анализ Тональности (Sentiment Analysis): Понимая Эмоции
- Распознавание Именованных Сущностей (NER): Извлечение Важного
- Тематическое Моделирование и Извлечение Ключевых Фраз: Сквозь Шум к Смыслу
- Классификация и Суммаризация Текстов: Автоматизация Контента
- Чат-боты и Вопросно-ответные Системы: Интеллектуальный Диалог
- Специфические Задачи и Инструменты: От Юридических Документов до Сленга
- Вызовы и Оценка: Наш Подход к Качеству NLP-Решений
- Метрики Оценки: Precision, Recall, F1-score
- Сравнение Моделей и Методов: Выбираем Лучшее
- Оптимизация и Производительность
Разгадывая Язык: Наш Глубокий Дайв в Мир NLP с Python
Приветствуем, дорогие читатели и коллеги-энтузиасты! Сегодня мы отправляемся в захватывающее путешествие по бескрайним просторам обработки естественного языка, или, как принято говорить в кругах специалистов, NLP (Natural Language Processing). Представьте себе: миллиарды слов, ежедневно генерируемых человечеством, скрывают в себе океаны информации, невыраженные эмоции, скрытые смыслы и бесценные инсайты. Но как выудить эти жемчужины из бурного потока неструктурированного текста? Именно здесь на сцену выходит Python — наш верный спутник и мощный инструмент, который позволяет нам не просто читать, но и понимать, анализировать и даже генерировать человеческую речь.
Мы, как опытные блогеры и практики, не понаслышке знаем, насколько увлекателен и одновременно сложен мир NLP. От самых базовых операций, таких как разделение текста на слова, до создания интеллектуальных систем, способных вести диалог или переводить языки в реальном времени — каждый шаг в этой области открывает новые горизонты. В этой статье мы поделимся нашим обширным опытом, расскажем о ключевых библиотеках и методах, которые составляют фундамент современного NLP на Python, и покажем, как мы применяем их для решения самых разнообразных задач. Приготовьтесь, будет интересно!
Фундамент NLP: Предобработка Текста – Наш Первый Шаг к Пониманию
Прежде чем мы сможем заставить машину "понять" текст, нам необходимо его тщательно подготовить. Представьте, что вы собираетесь приготовить изысканное блюдо: сначала нужно очистить, нарезать и подготовить ингредиенты. Точно так же и с текстом. Этап предобработки, это краеугольный камень любого NLP-проекта, и мы всегда уделяем ему особое внимание, ведь качество конечного результата напрямую зависит от чистоты и формы наших данных.
Начнем с самого простого, но жизненно важного процесса — токенизации. Это искусство разбиения непрерывного текста на более мелкие смысловые единицы, называемые токенами. Чаще всего токенами выступают слова, но в зависимости от задачи это могут быть и символы, и субслова, и даже целые предложения. Мы используем библиотеку NLTK (Natural Language Toolkit), которая предлагает простые и эффективные функции для этого. Например, для русского языка NLTK отлично справляется с разбиением текста на предложения и слова, учитывая особенности пунктуации.
После того как текст разбит на слова, мы часто сталкиваемся с проблемой вариативности форм одного и того же слова. "Бежать", "бежит", "бежал" — все это разные формы одного глагола. Здесь нам на помощь приходят стемминг и лемматизация. Стемминг — это грубое отсечение окончаний для приведения слова к его основе (корню), что не всегда дает реальное слово, но унифицирует их. Например, "running" и "runs" станут "run". Мы применяем NLTK для простого стемминга, когда скорость важнее лингвистической точности; Однако, когда нам нужна максимальная точность и полноценные словарные формы слов, мы обращаемся к лемматизации. Этот процесс более сложен, так как он использует морфологический анализ и словари для приведения слова к его начальной форме (лемме). SpaCy и Stanza показывают выдающиеся результаты в продвинутой лемматизации, особенно для языков с богатой морфологией, таких как русский, где одно слово может иметь десятки форм.
Иногда текст содержит нежелательные элементы: HTML-теги, пунктуацию, стоп-слова (вроде "и", "в", "на", которые не несут глубокого смысла), а также эмодзи и сленг, особенно в текстах из социальных сетей. Мы активно используем регулярные выражения (библиотека re) для очистки данных от всего лишнего. Это позволяет нам создать "чистый холст" для дальнейшего анализа. Textacy также предоставляет удобные инструменты для извлечения информации и работы с зависимостями, что помогает в тонкой очистке и предобработке.
Наши Инструменты для Предобработки
| Инструмент | Задача | Пример использования |
|---|---|---|
| NLTK | Токенизация, простой стемминг | nltk.word_tokenize("Пример текста") |
| spaCy | Продвинутая лемматизация, синтаксический парсинг | nlp("текст")._.lemma_ |
| Stanza | Лемматизация для языков с богатой морфологией | nlp("текст").sentences[0].words[0].lemma |
| re (регулярные выражения) | Очистка текста (удаление тегов, пунктуации) | re.sub(r'<.*?>', '', html_text) |
Могучие Библиотеки: Наши Рабочие Лошадки в Мире NLP
После того как текст подготовлен, мы переходим к его анализу с помощью специализированных библиотек. Python предлагает целую экосистему инструментов, каждый из которых заточен под свои уникальные задачи. Мы пользуемся широким спектром этих библиотек, чтобы максимально эффективно решать поставленные перед нами задачи.
NLTK и SpaCy: От Азов до Глубин
Мы уже упоминали NLTK для базовых задач, но его возможности гораздо шире. NLTK является отличной отправной точкой для новичков и предлагает множество алгоритмов и корпусов для обучения. Мы часто используем его для морфологического анализа, включая POS-теггинг (определение частей речи), что является важным шагом для понимания структуры предложения. Однако, когда речь заходит о скорости и производительности, наш выбор часто падает на spaCy. Эта библиотека известна своей эффективностью и предлагает предварительно обученные модели для различных языков, включая русский. С помощью spaCy мы можем выполнять распознавание именованных сущностей (NER) с высокой точностью и скоростью, а также проводить синтаксический парсинг и анализ зависимостей, что позволяет нам строить сложные графы предложений и извлекать связи между словами. Например, для быстрого NER spaCy, это наше "оружие" выбора.
Gensim и Scikit-learn: Раскрываем Скрытые Смыслы
Для задач, связанных с поиском скрытых тем в больших текстовых корпусах, мы активно применяем библиотеку Gensim. Это мощный инструмент для тематического моделирования, в частности, для алгоритмов LDA (Латентное размещение Дирихле) и LSI (Латентное семантическое индексирование). Gensim позволяет нам выявить основные темы, которые обсуждаются в массиве документов, что крайне полезно для анализа отзывов клиентов, новостных статей или научных работ. Мы также используем Gensim для работы с Word Embeddings, такими как Word2Vec и GloVe, о которых мы поговорим чуть позже, но уже здесь можем отметить их важность для понимания семантических связей между словами.
Когда же перед нами стоит задача классификации текстов, например, определение спама, категоризация новостей или анализ тональности — мы обращаемся к Scikit-learn. Эта библиотека является стандартом де-факто в машинном обучении и предлагает широкий спектр алгоритмов: от простых наивных байесовских классификаторов до мощных SVM (Метод опорных векторов). Мы можем легко интегрировать наши векторизованные текстовые данные с моделями Scikit-learn для построения надежных систем классификации. Сравнение различных методов машинного обучения для NLP, таких как SVM и наивный байесовский классификатор, также удобно проводить с помощью этой библиотеки.
TextBlob и Другие Помощники
Для более простых и быстрых NLP-задач мы иногда обращаемся к TextBlob. Это библиотека, построенная на базе NLTK, которая предоставляет интуитивно понятный API для таких операций, как анализ тональности, POS-теггинг и извлечение фраз. Она отлично подходит для быстрого прототипирования и проектов, не требующих глубокой кастомизации. Тем не менее, мы всегда помним об ограничениях TextBlob и, при необходимости, используем более мощные альтернативы.
В нашем арсенале также присутствуют специализированные библиотеки для работы с многоязычными текстами, такие как Polyglot, которая позволяет нам обрабатывать тексты на редких языках, и Stanza, которая, как мы уже упоминали, незаменима для языков с богатой морфологией, предлагая мощный синтаксический анализ и NER. Для веб-скрейпинга текста мы используем Beautiful Soup, а для извлечения текста из PDF-документов — PyMuPDF, что расширяет наши возможности по сбору и предобработке данных из различных источников.
От Слов к Числам: Векторизация и Эмбеддинги — Как Мы Учим Машины "Чувствовать" Слова
Сырой текст, даже после тщательной предобработки, представляет собой набор символов, который машина не может напрямую "понять". Чтобы алгоритмы машинного обучения могли работать с текстом, нам необходимо преобразовать слова и документы в числовые векторы. Этот процесс называется векторизацией, и он является одним из самых интригующих и важных этапов в NLP. Мы постоянно экспериментируем с различными методами векторизации, чтобы найти наиболее эффективный подход для каждой конкретной задачи.
Классические Векторизаторы: CountVectorizer и TF-IDF
Наш путь в мир векторизации часто начинается с простых, но эффективных методов. CountVectorizer из Scikit-learn создает векторное представление текста, подсчитывая частоту появления каждого слова в документе. Это формирует так называемую "мешок слов" (bag-of-words) модель, где порядок слов не учитывается, но их присутствие и количество важны. Мы используем его, когда нам нужно быстро получить числовое представление текста для задач классификации или кластеризации.
Однако простое количество слов не всегда отражает их значимость. Слово "и" может встречаться часто, но не нести много информации. Здесь на помощь приходит TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает частоту слова в документе (TF), но и его редкость во всем корпусе документов (IDF). Таким образом, слова, которые встречаются часто в одном документе, но редко в других, получают более высокий вес, что делает их более значимыми. Мы активно используем TF-IDF для задач извлечения ключевых фраз, категоризации статей и сравнения документов, так как он отлично справляется с выделением наиболее релевантных терминов.
Word Embeddings: Погружение в Смысл
Классические векторизаторы имеют один существенный недостаток: они не учитывают семантические связи между словами. Слова "король" и "королева" могут быть очень далеки друг от друга в векторном пространстве, хотя они тесно связаны по смыслу. Здесь на сцену выходят Word Embeddings — векторные представления слов, которые улавливают их семантические отношения. Мы активно работаем с Word2Vec и GloVe, обычно используя библиотеку Gensim для их генерации и применения. Эти модели обучаются на огромных текстовых корпусах и могут предсказывать, какие слова похожи друг на друга, а какие — нет. Например, если мы вычтем вектор "мужчина" из вектора "король" и добавим вектор "женщина", мы получим вектор, близкий к "королева". Это открывает двери для невероятных возможностей в задачах, требующих понимания смысла, таких как анализ синонимов, рекомендательные системы и даже машинный перевод.
Для работы с редкими словами, которые плохо представлены в стандартных Word Embeddings, мы обращаемся к FastText. Эта модель учитывает морфемную структуру слов, что позволяет ей создавать качественные векторы даже для слов, которые она не видела во время обучения. Мы находим ее особенно полезной при работе с языками, где много словоформ или опечаток.
От Слов к Документам: Doc2Vec и Контекстные Встраивания
Если Word Embeddings представляют слова, то Doc2Vec (также из Gensim) расширяет эту концепцию на целые документы или абзацы. Это позволяет нам получать векторное представление всего текста, что крайне полезно для задач сравнения документов, поиска похожих статей или кластеризации больших текстовых массивов. Мы используем Doc2Vec для анализа больших текстовых массивов (Big Data NLP) и разработки систем обнаружения плагиата.
Современные методы пошли еще дальше, представив контекстные встраивания (Contextual Embeddings). Они учитывают не только само слово, но и его окружение в предложении. Это означает, что одно и то же слово может иметь разные векторы в зависимости от контекста, что гораздо ближе к тому, как люди понимают язык. Мы применяем Sentence Transformers для векторизации предложений и документов, что дает нам очень мощные представления для задач семантического поиска и сравнения. Также, для более глубокого анализа взаимосвязей в тексте, мы исследуем Graph Embeddings, которые позволяют нам моделировать сложные отношения между сущностями.
"Язык, это дорожная карта культуры. Он говорит вам, откуда люди пришли и куда они направляются."
— Рита Мэй Браун
Революция Трансформеров: Наши Открытия в Глубоком NLP
Если предыдущие методы были мощными, то появление архитектуры Трансформеров произвело настоящую революцию в мире NLP. Мы не преувеличиваем, когда говорим, что это изменило правила игры. Трансформеры, и в частности такие модели как BERT, GPT, T5, позволяют нам решать задачи, которые еще несколько лет назад казались фантастикой. Мы активно используем экосистему Hugging Face Transformers, которая предоставляет доступ к сотням предварительно обученных моделей и удобные инструменты для их тонкой настройки (fine-tuning).
BERT, GPT и Другие Гиганты
BERT (Bidirectional Encoder Representations from Transformers) — это модель-кодировщик, которая позволяет нам получать глубокие контекстные представления слов и предложений. Мы используем BERT для широкого круга задач: от классификации текстов (например, анализ тональности финансовых новостей или постов о политике) и распознавания именованных сущностей (NER) до разработки систем вопросно-ответных систем (QA). Его способность понимать контекст с обеих сторон слова делает его невероятно мощным.
GPT (Generative Pre-trained Transformer), наоборот, является моделью-декодером, специализирующейся на генерации текста. Мы экспериментируем с GPT для создания контента, генерации диалогов для чат-ботов, автоматического перефразирования и даже генерации кода. Возможности этих моделей поражают воображение, и мы постоянно ищем новые способы их применения. Тонкая настройка предварительно обученных моделей с помощью наших собственных данных позволяет нам адаптировать их под очень специфические задачи, достигая при этом выдающихся результатов.
PyTorch/TensorFlow и LSTM: Когда Нужен Полный Контроль
Хотя Hugging Face предоставляет удобный интерфейс к трансформерам, иногда нам нужен полный контроль над архитектурой нейронной сети. В таких случаях мы обращаемся к фреймворкам глубокого обучения, таким как PyTorch и TensorFlow (включая Keras). Мы используем их для создания собственных нейросетей NLP, включая рекуррентные нейронные сети (RNN) и особенно их продвинутые варианты — LSTM (Long Short-Term Memory). LSTM-сети отлично подходят для задач, где важен порядок слов и долгосрочные зависимости, например, в анализе временных рядов в текстовых данных или в сложных задачах машинного перевода. Применение классификации текста с использованием PyTorch дает нам гибкость в построении и экспериментировании с моделями.
Для современного NER и суммаризации мы также используем библиотеку Flair, которая предлагает мощные контекстные эмбеддинги и модели на их основе. Работа с Transformer-моделями для машинного перевода, суммаризации и даже генерации кода становится все более доступной и эффективной благодаря этим фреймворкам и библиотекам.
Прикладной NLP: От Анализа к Интеллектуальным Решениям
Теория и инструменты, это здорово, но настоящая магия NLP раскрывается в его практическом применении. Мы используем Python и описанные выше библиотеки для создания реальных интеллектуальных систем, которые решают конкретные бизнес-задачи и улучшают пользовательский опыт. Наш опыт охватывает широкий спектр прикладных областей.
Анализ Тональности (Sentiment Analysis): Понимая Эмоции
Понимание эмоциональной окраски текста — одна из самых востребованных задач в NLP. Мы применяем анализ тональности для оценки отзывов клиентов о продуктах и услугах, анализа сообщений в социальных сетях (Twitter, Reddit), а также для мониторинга финансовых новостей. Для базовых задач мы используем VADER (Valence Aware Dictionary and sEntiment Reasoner), который хорошо справляется с англоязычными текстами. Однако для более сложных случаев, особенно с учетом сарказма, сленга и специфики русского языка, мы разрабатываем собственные модели на основе Scikit-learn или Transformer-моделей. Анализ тональности отзывов о фильмах или ресторанах помогает нам выявить общественное мнение и предпочтения.
Распознавание Именованных Сущностей (NER): Извлечение Важного
NER — это процесс идентификации и классификации именованных сущностей в тексте, таких как имена людей, названия организаций, локации, даты и т.д.. Мы используем NER для извлечения ключевой информации из юридических документов, медицинских записей, новостных статей. spaCy и Flair предлагают высокопроизводительные модели для NER. Мы также экспериментируем с CRF (Conditional Random Fields) для более специфических задач и, конечно, применяем BERT для задачи NER, что дает нам state-of-the-art результаты, особенно при тонкой настройке на наших данных.
Тематическое Моделирование и Извлечение Ключевых Фраз: Сквозь Шум к Смыслу
Чтобы понять, о чем идет речь в большом корпусе текстов, мы используем тематическое моделирование с Gensim (LDA, LSI). Это позволяет нам выявлять скрытые темы и кластеризовать документы по их смысловому содержанию. Мы также сравниваем модели тематического моделирования, такие как LDA и NMF, чтобы выбрать наиболее подходящую для конкретной задачи. Для извлечения ключевых фраз и предложений мы используем RAKE и TextRank, которые помогают нам быстро выделить наиболее важные части текста, что крайне полезно для суммаризации и автоматической категоризации статей.
Классификация и Суммаризация Текстов: Автоматизация Контента
Мы активно разрабатываем системы автоматической категоризации статей, новостей и отзывов, используя Scikit-learn и PyTorch. Это позволяет нам эффективно организовывать большие объемы информации. Для суммаризации текста мы работаем с двумя основными подходами: экстрактивным (извлечение наиболее важных предложений из исходного текста) и абстрактивным (генерация нового, краткого текста). Мы используем TextRank для суммаризации и, конечно, Transformer-модели для суммаризации, которые показывают впечатляющие результаты в создании связных и информативных резюме.
Чат-боты и Вопросно-ответные Системы: Интеллектуальный Диалог
Разработка чат-ботов на Python, в т.ч. с использованием фреймворка Rasa, является одним из наших любимых направлений. Мы создаем ботов, способных вести осмысленный диалог, отвечать на вопросы и автоматизировать клиентскую поддержку. Для более сложных вопросно-ответных систем (QA) мы применяем мощные Transformer-модели, которые могут находить точные ответы в больших базах знаний. Использование Transformer-моделей для генерации диалогов позволяет нам создавать более естественные и человечные взаимодействия.
Специфические Задачи и Инструменты: От Юридических Документов до Сленга
Наш опыт охватывает и более нишевые, но не менее интересные задачи:
- Анализ юридических документов: Мы используем Python для извлечения фактов, дат и ключевых положений из контрактов.
- Обнаружение плагиата: Применение TextDistance помогает нам измерять сходство строк и документов для выявления дубликатов.
- Проверка грамматики и орфографии: Мы разрабатываем инструменты для исправления ошибок и нормализации пунктуации, что важно для качественного контента.
- Работа с эмодзи и сленгом: Современные тексты в социальных сетях требуют учета этих особенностей. Мы разрабатываем инструменты для нормализации сленга и анализа его значения.
- Анализ стилистики текстов: Определение авторского почерка и стиля письма для задач атрибуции.
- Обработка неструктурированного текста: Очистка данных, работа с неполными и ошибочными данными — это постоянный вызов, который мы решаем с помощью различных подходов.
Вызовы и Оценка: Наш Подход к Качеству NLP-Решений
Мир NLP полон возможностей, но и вызовов. Мы постоянно сталкиваемся с проблемами обработки неполных и ошибочных данных, многозначностью слов и сложностью человеческого языка. Поэтому оценка качества наших моделей и решений является критически важным этапом.
Метрики Оценки: Precision, Recall, F1-score
Для оценки качества моделей NER, классификации и других задач мы используем стандартные метрики: Precision (точность), Recall (полнота) и F1-score. Precision показывает, насколько точно наша модель предсказывает положительные классы, Recall — сколько фактических положительных классов она смогла найти, а F1-score — это гармоническое среднее между ними, дающее сбалансированную оценку. Мы тщательно анализируем эти метрики, чтобы понять сильные и слабые стороны наших решений и постоянно их улучшать.
Сравнение Моделей и Методов: Выбираем Лучшее
В NLP нет универсального решения. Мы постоянно сравниваем различные подходы и модели, чтобы найти наиболее эффективные для конкретной задачи. Например, мы проводим сравнение моделей тематического моделирования (LDA vs NMF), методов векторизации (TF-IDF vs Word2Vec), а также моделей Word2Vec (Skip-gram vs CBOW). Это позволяет нам не только выбирать оптимальные инструменты, но и глубоко понимать их принципы работы и ограничения. Мы также оцениваем эффективность различных токенизаторов и методов лемматизации (SpaCy vs NLTK).
Оптимизация и Производительность
С ростом объемов данных и сложности моделей, производительность становится ключевым фактором. Мы активно работаем с обработкой больших текстовых массивов (Big Data NLP) и используем GPU-ускорение для тренировки глубоких нейронных сетей, чтобы сократить время обучения и обработки. Также, для задач, требующих мгновенной реакции, мы разрабатываем системы обработки текста в режиме реального времени (Streaming NLP).
Мы прошли долгий путь, исследуя бескрайние возможности обработки естественного языка с помощью Python. От фундаментальных шагов предобработки текста до создания интеллектуальных систем на базе трансформеров — каждый этап этого путешествия наполнен открытиями и новыми знаниями. Мы надеемся, что наш опыт и практические советы помогут вам в вашем собственном освоении этой увлекательной области.
Мир NLP постоянно развивается, и мы, как блогеры и практики, всегда остаемся на переднем крае этих изменений, изучая новые модели, алгоритмы и подходы. Использование Python, с его богатой экосистемой библиотек, делает эту задачу не только выполнимой, но и невероятно увлекательной. Не бойтесь экспериментировать, погружаться в код и создавать свои собственные решения — именно так рождаются инновации. Удачи вам в ваших NLP-приключениях, и помните: язык, это не просто слова, это ключ к пониманию мира вокруг нас!
Подробнее: Наши LSI Запросы
| NLTK основы | spaCy NER | Gensim LDA LSI | Scikit-learn текст | Word2Vec GloVe |
| Sentiment Analysis VADER | Hugging Face Transformers | Лемматизация стемминг | Разработка чат-ботов | Извлечение ключевых фраз |





