
- Разгадывая Тайны Текста: Наш Путь в Мир Обработки Естественного Языка на Python
- Первые Шаги: От Сырого Текста к Смысловым Единицам
- Очистка и Нормализация Текста: Борьба с Шумом
- Векторизация Текста: Как Научить Машину "Читать"
- Сравнение Методов Векторизации: Наш Опыт
- Ключевые Задачи NLP: От Идентификации Сущностей до Генерации Текста
- Распознавание Именованных Сущностей (NER)
- Классификация Текстов: Сортировка и Категоризация
- Анализ Тональности (Sentiment Analysis): Понимание Эмоций
- Тематическое Моделирование: Выявление Скрытых Смыслов
- Суммаризация Текста: Сжимаем Информацию
- Эра Трансформеров: Революция в NLP
- Практические Применения и Нишевые Задачи
- Работа с Мультиязычными Данными
- Извлечение Информации из Различных Источников
- Разработка Специализированных Инструментов
- Визуализация Текстовых Данных: Видеть Смыслы
Разгадывая Тайны Текста: Наш Путь в Мир Обработки Естественного Языка на Python
Привет, дорогие читатели и коллеги-энтузиасты технологий! Сегодня мы хотим поделиться с вами нашим многолетним опытом погружения в одну из самых увлекательных и быстроразвивающихся областей искусственного интеллекта – Обработку Естественного Языка, или NLP (Natural Language Processing). Представьте себе: миллиарды слов, ежедневно генерируемых людьми по всему миру, скрывают в себе бесценные сокровища информации. Наша миссия как исследователей и разработчиков — научить машины понимать, интерпретировать и даже генерировать этот человеческий язык. И что может быть лучшим инструментом для этого, чем Python, с его богатой экосистемой библиотек?
Мы прошли долгий путь от первых экспериментов с токенизацией до тонкой настройки сложнейших трансформерных моделей. За эти годы мы увидели, как NLP превратилось из нишевой академической дисциплины в мощный инструмент, меняющий бизнес, науку и повседневную жизнь. От голосовых помощников до систем анализа настроений в социальных сетях, от автоматического перевода до интеллектуальных поисковых систем — везде задействованы алгоритмы NLP. В этой статье мы приглашаем вас в наше путешествие, где мы разберем основные концепции, покажем ключевые инструменты и поделимся практическими советами, основанными на нашем личном опыте.
Первые Шаги: От Сырого Текста к Смысловым Единицам
Любое путешествие в мир NLP начинается с одного и того же шага: подготовки данных. Человеческий язык, со всей его сложностью и нюансами, для машины представляет собой лишь последовательность символов. Наша задача — разбить эту последовательность на осмысленные единицы и привести их к стандартизированному виду, чтобы алгоритмы могли их "понять". Этот процесс включает в себя несколько фундаментальных этапов, которые мы осваивали, зачастую, методом проб и ошибок.
Мы начинали с классических библиотек, таких как NLTK (Natural Language Toolkit), которая стала нашим верным спутником в освоении базовых операций. С ее помощью мы научились токенизировать текст, то есть разбивать его на слова или предложения. Это кажется простым, но попробуйте правильно разделить "Нью-Йорк" или "И.О. директора" без глубокого понимания контекста! Затем мы столкнулись с проблемой того, что одно и то же слово может иметь разные формы: "бежать", "бежит", "бегал". Здесь на помощь приходят стемминг и лемматизация. Стемминг отсекает окончания, пытаясь привести слово к его "основе" (например, "run" из "running", "runs"), а лемматизация использует лингвистические правила, чтобы привести слово к его словарной форме (например, "быть" из "был", "будет").
Со временем мы перешли к более производительным и функциональным инструментам, таким как spaCy, который предлагает не только быструю токенизацию и лемматизацию, но и продвинутый синтаксический парсинг, позволяющий понять структуру предложения и взаимосвязи между словами. Мы обнаружили, что для многих языков с богатой морфологией, например русского, продвинутая лемматизация в spaCy или Stanza дает гораздо лучшие результаты, чем простой стемминг, сохраняя при этом больший объем смысловой информации. Это было критически важно для наших проектов, требующих высокой точности.
Очистка и Нормализация Текста: Борьба с Шумом
Помимо токенизации и нормализации форм слов, мы постоянно сталкиваемся с необходимостью очистки данных. Реальный текст далёк от идеальных примеров из учебников: он полон опечаток, HTML-тегов, специальных символов, эмодзи, сленга и сокращений. Все это — "шум", который может значительно снизить качество анализа. Мы выработали для себя ряд обязательных шагов, которые всегда применяем к сырым текстовым данным.
В начале пути мы активно использовали регулярные выражения (модуль `re` в Python) для удаления ненужных символов, ссылок, цифр и HTML-тегов. Это мощный инструмент, но требующий аккуратности, чтобы не удалить что-то важное. Затем мы перешли к нормализации сленга и обработке эмодзи, что стало особенно актуально при анализе текстов из социальных сетей. Мы даже создавали собственные словари для замены сленговых выражений на их нормализованные эквиваленты.
Список стоп-слов (stop words), это еще одна важная часть предобработки. Это часто встречающиеся, но малоинформативные слова (например, "и", "в", "на", "он"), которые мы удаляем, чтобы сфокусироваться на более значимых словах. NLTK и spaCy предлагают готовые списки стоп-слов для разных языков, но мы часто их расширяли или адаптировали под специфику наших задач, например, при анализе юридических документов, где даже предлоги могут нести важный смысл.
| Этап предобработки | Описание | Используемые инструменты | Зачем это нужно |
|---|---|---|---|
| Токенизация | Разбиение текста на слова/предложения. | NLTK, spaCy, `re` | Создание базовых единиц для анализа. |
| Стемминг/Лемматизация | Приведение слов к их базовой форме. | NLTK (PorterStemmer, WordNetLemmatizer), spaCy, Stanza | Уменьшение размерности, объединение форм одного слова. |
| Удаление стоп-слов | Удаление часто встречающихся, но малоинформативных слов. | NLTK, spaCy (встроенные списки), пользовательские списки | Фокусировка на ключевых словах, уменьшение шума. |
| Очистка от спецсимволов/HTML | Удаление ненужных символов, тегов, ссылок. | `re`, Beautiful Soup | Приведение текста к "чистому" виду, удобному для обработки. |
| Нормализация регистра | Приведение всех слов к нижнему регистру. | Методы строк Python (`.lower`) | Рассмотрение "Слово" и "слово" как одного токена. |
Векторизация Текста: Как Научить Машину "Читать"
После того как текст очищен и нормализован, возникает следующая фундаментальная проблема: как представить слова и документы в виде, понятном для математических алгоритмов машинного обучения? Ведь компьютеры работают с числами, а не с человеческим языком. Здесь на сцену выходит векторизация текста — процесс преобразования текстовых данных в числовые векторы. Мы много экспериментировали с различными подходами, каждый из которых имеет свои преимущества и недостатки.
Наш путь начался с простых, но эффективных методов, таких как CountVectorizer и TF-IDF (Term Frequency-Inverse Document Frequency) векторизация из библиотеки Scikit-learn. CountVectorizer просто считает количество вхождений каждого слова в документе, создавая "мешок слов". TF-IDF идет дальше, взвешивая частоту слова в документе относительно его редкости во всем корпусе текстов. Этот подход помогает выделить слова, которые действительно характеризуют конкретный документ, а не просто часто встречаются везде. Мы использовали эти методы для задач классификации текстов, например, для определения категории новостных статей или анализа отзывов клиентов.
Однако, мы быстро осознали ограничения этих методов: они не учитывают семантическую связь между словами. Слова "король" и "королева", "мужчина" и "женщина" для TF-IDF так же далеки друг от друга, как "король" и "банан". Это привело нас к изучению Word Embeddings — встраиваний слов, которые произвели настоящую революцию в NLP. Мы начали работать с Word2Vec и GloVe с использованием библиотеки Gensim, которая оказалась невероятно удобной для создания и работы с этими моделями. Word2Vec (как Skip-gram, так и CBOW) учится предсказывать контекст слова или само слово по контексту, в результате чего слова с похожим значением оказываются близко в многомерном векторном пространстве.
"Язык — это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
Позднее мы расширили наши горизонты, изучив FastText, который, помимо Word2Vec, учитывает подслова (субслова) и потому особенно хорош для работы с редкими словами и языками с богатой морфологией. Для представления целых предложений и документов мы освоили Doc2Vec (также из Gensim) и, конечно же, Sentence Transformers, которые стали нашим основным инструментом для векторизации предложений с учетом их контекста. Эти методы позволили нам создавать системы для поиска смысловых дубликатов, суммаризации текстов и даже для построения вопросно-ответных систем, где понимание смысла вопроса критически важно.
Сравнение Методов Векторизации: Наш Опыт
Выбор правильного метода векторизации часто зависит от конкретной задачи и объема данных. Мы постоянно сравниваем различные подходы, чтобы найти оптимальное решение.
Вот краткий обзор наших наблюдений:
- TF-IDF: Прекрасно подходит для задач, где важны уникальные термины и их значимость в документе. Хорош для классификации, извлечения ключевых слов. Легко интерпретируется.
- Word2Vec/GloVe: Отлично улавливает семантические отношения между словами. Незаменим, когда важно понимание смысла слова в контексте. Требует больших корпусов для обучения или использования предобученных моделей.
- FastText: Мощнее Word2Vec для редких слов и морфологически сложных языков благодаря учету субслов. Также хорошо работает с небольшими корпусами.
- Doc2Vec/Sentence Transformers: Идеальны для задач, где нужно сравнивать или классифицировать целые документы или предложения, сохраняя их общий смысл. Основа для поиска схожих документов, суммаризации.
Ключевые Задачи NLP: От Идентификации Сущностей до Генерации Текста
После того как текст подготовлен и представлен в числовом виде, мы можем приступить к решению конкретных задач. За годы работы мы сталкивались с широким спектром применений NLP, каждое из которых требовало своего набора инструментов и подходов. Давайте рассмотрим некоторые из наиболее важных.
Распознавание Именованных Сущностей (NER)
Одной из первых задач, которая нас по-настоящему увлекла, было Распознавание Именованных Сущностей (NER). Представьте, что у вас есть огромный массив новостных статей, и вам нужно быстро найти все имена людей, названия организаций, географические объекты или даты. Ручная обработка такого объема невозможна. NER позволяет автоматически извлекать эти сущности из текста.
Мы начинали с использования spaCy для быстрого и достаточно точного NER. Его предобученные модели отлично справляются со стандартными сущностями на многих языках. Однако для более специфичных доменов, таких как медицинские записи или юридические документы, нам приходилось либо тонко настраивать существующие модели, либо обучать собственные, используя CRF (Conditional Random Fields) или современные нейросетевые подходы с библиотекой Flair, которая известна своими State-of-the-Art результатами в этой области. Мы также экспериментировали с BERT для задачи NER, получая впечатляющие результаты, особенно после тонкой настройки на наших размеченных данных;
Классификация Текстов: Сортировка и Категоризация
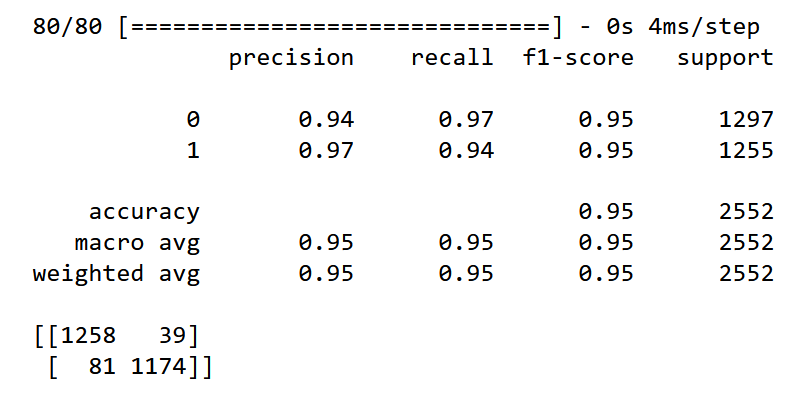
Классификация текстов — это, пожалуй, одна из самых распространенных задач в NLP. От фильтрации спама до категоризации статей по темам, от анализа отзывов клиентов до автоматической модерации контента — везде, где нужно отнести текст к одному или нескольким предопределенным классам, применяется классификация. Мы использовали широкий спектр алгоритмов из Scikit-learn, таких как SVM (Support Vector Machines) и наивный байесовский классификатор, которые показали себя надежными "рабочими лошадками" для многих задач.
С появлением глубокого обучения, мы начали применять нейросети, построенные на PyTorch и TensorFlow, включая LSTM-сети, которые хорошо справляются с последовательными данными, такими как текст. В последние годы, конечно, трансформерные модели, такие как BERT, стали нашим фаворитом для задач классификации, особенно когда требовалась высокая точность. Их способность улавливать контекст и семантику слов значительно повысила качество наших классификаторов.
Анализ Тональности (Sentiment Analysis): Понимание Эмоций
Понимание эмоций и настроений, выраженных в тексте, стало критически важным для многих наших проектов, особенно в сфере маркетинга и обслуживания клиентов. Анализ тональности позволяет автоматически определять, является ли отзыв положительным, отрицательным или нейтральным.
Мы начинали с простых подходов, таких как VADER (Valence Aware Dictionary and sEntiment Reasoner) — лексикографического инструмента, который хорошо работает с текстами из социальных сетей благодаря встроенной поддержке сленга и смайликов. TextBlob также оказался удобным инструментом для быстрого анализа тональности на английском языке. Однако, как мы быстро выяснили, эти подходы имеют свои ограничения, особенно при работе с сарказмом, иронией или специфическим жаргоном. Для более точного анализа тональности в социальных сетях, а также в финансовых новостях, где ставки особенно высоки, мы перешли к обучению моделей на основе машинного обучения и глубокого обучения, используя размеченные данные и мощь трансформеров.
Тематическое Моделирование: Выявление Скрытых Смыслов
Иногда нам нужно не просто классифицировать текст по предопределенным категориям, а обнаружить скрытые, латентные темы в большом корпусе документов. Здесь на помощь приходит тематическое моделирование. Мы активно использовали библиотеку Gensim для реализации алгоритмов LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing).
LDA, например, позволяет нам определить, какие темы присутствуют в коллекции документов и какие слова характерны для каждой темы. Это очень полезно для анализа текстов отзывов клиентов, блогов и форумов, где мы можем выявить основные проблемы или интересы пользователей, не имея предварительной разметки. Мы также сравнивали LDA с NMF (Non-negative Matrix Factorization) из Scikit-learn, обнаруживая, что каждый из них имеет свои сильные стороны в зависимости от структуры данных и желаемой интерпретируемости результатов. Этот подход помог нам, например, выявить скрытые темы в финансовых отчетах или определить основные направления обсуждений в больших текстовых массивах.
Суммаризация Текста: Сжимаем Информацию
В мире, переполненном информацией, способность быстро извлекать суть из длинных текстов становится бесценной. Мы работали над созданием систем суммаризации текста, которые бывают двух основных типов: экстрактивная и абстрактивная.
- Экстрактивная суммаризация: Выбирает наиболее важные предложения из оригинального текста и объединяет их в краткое изложение. Для этого мы использовали такие алгоритмы, как TextRank, который строит граф предложений и ранжирует их по важности. Это отличный способ для быстрого создания дайджестов новостей или обзоров документов.
- Абстрактивная суммаризация: Создает новое, грамматически связное изложение, которое может не содержать предложений из оригинального текста. Это гораздо более сложная задача, требующая генерации текста. Здесь нам на помощь пришли трансформерные модели, такие как те, что доступны через Hugging Face. Они способны "понимать" текст и перефразировать его, создавая краткое содержание, которое звучит естественно. Мы активно применяем их для создания аннотаций к статьям или для формирования кратких ответов в вопросно-ответных системах.
Эра Трансформеров: Революция в NLP
Наш опыт работы с NLP резко изменился с появлением трансформерных архитектур. То, что раньше казалось недостижимым, стало реальностью благодаря моделям, таким как BERT, GPT и их многочисленным потомкам. Эти модели, доступные через библиотеку Hugging Face Transformers, стали нашим основным инструментом для решения самых сложных задач.
Мы использовали BERT для тонкой настройки на специфические задачи классификации, NER и даже для выявления связей между сущностями в тексте. Его способность понимать контекст слова, учитывая все остальные слова в предложении, была прорывом по сравнению с предыдущими Word Embeddings. А с моделями GPT, мы впервые смогли создавать системы для генерации текста, которые производят поразительно связные и осмысленные предложения и абзацы. Это открыло нам двери к разработке чат-ботов, систем автоматического перефразирования, генерации диалогов и даже к экспериментам по генерации кода на основе текстовых описаний.
Тонкая настройка (fine-tuning) предварительно обученных трансформерных моделей на наших собственных данных стала стандартной практикой. Это позволяет нам адаптировать мощь этих гигантских моделей к нашим узкоспециализированным доменам, достигая результатов, которые ранее были немыслимы с нуля. Мы также экспериментировали с использованием GPU-ускорения для обучения и инференса этих моделей, что является критически важным при работе с большими объемами данных и сложными архитектурами.
Практические Применения и Нишевые Задачи
Наше путешествие в NLP не ограничивается только фундаментальными задачами. Мы постоянно ищем новые способы применения этих технологий для решения реальных проблем.
Работа с Мультиязычными Данными
Мир не ограничивается одним языком, и наши проекты тоже. Мы столкнулись с необходимостью обрабатывать многоязычные текстовые корпусы. Библиотеки, такие как Polyglot и Stanza, стали нашими помощниками в работе с языками, отличными от английского, особенно с теми, которые имеют богатую морфологию, как русский. Stanza, разработанная Стэндфордским университетом, предоставляет полный конвейер NLP для десятков языков, включая токенизацию, POS-теггинг, лемматизацию и синтаксический анализ, что позволило нам значительно расширить географию наших проектов.
Извлечение Информации из Различных Источников
Прежде чем анализировать текст, его нужно получить. Мы часто используем Beautiful Soup для веб-скрейпинга, чтобы извлекать текст со страниц сайтов. А для работы с PDF-документами, такими как отчеты или юридические контракты, библиотека PyMuPDF стала незаменимым инструментом для извлечения текстового содержимого, позволяя нам анализировать структурированную информацию, скрытую в неструктурированном формате.
Разработка Специализированных Инструментов
Иногда готовых решений недостаточно, и мы приступаем к разработке собственных инструментов:
- Словари и Тезаурусы: Для узкоспециализированных областей мы создаем собственные словари терминов и тезаурусы, чтобы улучшить точность NER или тематического моделирования.
- Проверка Грамматики и Орфографии: Мы экспериментировали с созданием инструментов для проверки грамматики и исправления орфографии, используя правила и статистические модели.
- Обнаружение Плагиата: С помощью TextDistance и других метрик сходства строк и документов мы разрабатывали системы для обнаружения плагиата.
- Анализ Стилистики и Авторского Почерка: Это более продвинутая задача, но мы работали над системами, которые могут анализировать лексическое богатство, частотность n-грамм и другие характеристики текста для определения авторства или стилистики.
Визуализация Текстовых Данных: Видеть Смыслы
Для нас, как для блогеров, очень важна наглядность. Просто цифры и метрики не всегда дают полную картину. Мы активно используем инструменты для визуализации текстовых данных, такие как Word Clouds (облака слов), которые позволяют быстро получить представление о наиболее частотных словах в корпусе. Для более глубокого анализа мы применяем тепловые карты для визуализации матриц сходства или используем библиотеки вроде Sweetviz для комплексного анализа текстовых данных.
Наше путешествие в мир Обработки Естественного Языка на Python было и остается невероятно захватывающим. От первых примитивных скриптов на NLTK до создания сложных систем на базе трансформеров — каждый этап приносил новые знания, вызовы и, конечно же, удовлетворение от решения реальных задач; Мы убедились, что Python с его богатой экосистемой библиотек является идеальным инструментом для любого, кто хочет исследовать эту область, будь то новичок или опытный исследователь.
Мы надеемся, что наш опыт, описанный в этой статье, вдохновит вас на собственные эксперименты и проекты. Помните, что мир NLP постоянно развивается, и новые прорывы случаются регулярно. Главное — не бояться пробовать, учиться на ошибках и всегда оставаться любознательными. Текст окружает нас повсюду, и с помощью Python и NLP мы можем научить машины не просто видеть буквы, но и понимать смыслы, скрытые за ними. Это открывает бесконечные горизонты для инноваций и улучшений в самых разных сферах нашей жизни. Удачи вам в ваших приключениях в мире текста!
Подробнее
| NLTK основы | spaCy NER | Gensim LDA | Scikit-learn классификация | Word2Vec GloVe |
| Анализ тональности Python | Трансформеры NLP | Обработка текста Python | Векторизация текста | Python NLP библиотеки |





