
- Разгадывая Тайны Текста: Полное Погружение в NLP на Python от А до Я
- Первые Шаги: Подготовка Текста к Анализу
- Токенизация и Стемминг: Разбираем Текст на Части
- Очистка и Нормализация Текста: Избавляемся от Шума
- От Слов к Числам: Векторизация Текста
- Простые, но Эффективные Методы: CountVectorizer и TF-IDF
- Глубокое Понимание: Word Embeddings (Word2Vec, GloVe, FastText)
- Ключевые Задачи NLP: От Поиска Сущностей до Анализа Тональности
- Распознавание Именованных Сущностей (NER)
- Тематическое Моделирование: Открываем Скрытые Темы
- Классификация Текстов: Автоматическое Распределение по Категориям
- Анализ Тональности (Sentiment Analysis): Понимаем Эмоции
- Глубокое Погружение: Трансформеры и Продвинутые Модели
- Эра Трансформеров: Hugging Face и Предварительно Обученные Модели
- Отдельные Сети: LSTM и Нейросети на PyTorch/TensorFlow
- Практические Приложения и Специальные Вызовы
- Создание Интеллектуальных Систем: От QA до Чат-ботов
- Анализ и Извлечение Информации: От Ключевых Фраз до Юридических Документов
- Специфические Вызовы и Инструменты
Разгадывая Тайны Текста: Полное Погружение в NLP на Python от А до Я
Добро пожаловать, дорогие читатели, в мир, где машины начинают понимать человеческий язык! Мы, как опытные исследователи и энтузиасты в области обработки естественного языка (NLP), готовы провести вас через увлекательное путешествие по самым глубоким и интересным аспектам этой науки, используя мощь Python․ Забудьте о скучных учебниках и сухих определениях – сегодня мы будем говорить о реальном опыте, о том, как мы применяем эти инструменты для решения самых разнообразных задач: от анализа отзывов клиентов до создания умных чат-ботов․ Приготовьтесь, ведь текст вокруг нас — это не просто буквы, это данные, полные скрытых смыслов, ожидающих, когда мы их раскроем․
Мы живем в эпоху, когда объем текстовой информации растет экспоненциально․ Социальные сети, новостные ленты, электронные письма, научные статьи, юридические документы – все это неструктурированные данные, которые человек просто не в состоянии обработать в полной мере․ Именно здесь на помощь приходит NLP, или Natural Language Processing – дисциплина, которая позволяет компьютерам понимать, интерпретировать и генерировать человеческий язык․ Наш путь в NLP начался много лет назад, и с тех пор мы видели, как эта область стремительно развивается, предлагая все более изощренные и эффективные инструменты․ Сегодня мы поделимся с вами нашим богатым опытом, охватывая как фундаментальные основы, так и передовые методы, которые мы активно используем в своих проектах․
Первые Шаги: Подготовка Текста к Анализу
Прежде чем мы сможем заставить машину "понять" текст, его необходимо тщательно подготовить․ Представьте, что вы хотите испечь пирог – вам нужно сначала очистить и нарезать ингредиенты․ В NLP этот процесс называется предобработкой текста, и он является краеугольным камнем любой успешной модели․ Мы неоднократно убеждались, что качество предобработки напрямую влияет на результат, поэтому уделяем этому этапу особое внимание․
Токенизация и Стемминг: Разбираем Текст на Части
Начнем с основ: токенизация и стемминг․ Токенизация – это процесс разбиения текста на мельчайшие значимые единицы, называемые токенами․ Чаще всего токенами являются слова или пунктуационные знаки․ Мы используем такие библиотеки, как NLTK (Natural Language Toolkit) и spaCy, которые предлагают эффективные и гибкие токенизаторы․ NLTK, например, предоставляет различные алгоритмы токенизации, включая WordPunctTokenizer, который отделяет пунктуацию от слов, что часто бывает полезно․
После токенизации слова могут быть представлены в различных формах (например, "бежал", "бегу", "бежать")․ Чтобы привести их к общей основе, мы применяем стемминг или лемматизацию․ Стемминг – это более грубый процесс, который обрезает окончания слов, приводя их к "корню" (например, "бежал" -> "беж")․ В NLTK мы часто используем Porter Stemmer или Snowball Stemmer для английского языка, а для русского – Snowball Stemmer (RussianStemmer)․ Несмотря на свою простоту, стемминг может быть очень эффективен для многих задач․
Лемматизация, в отличие от стемминга, более интеллектуальный процесс․ Она приводит слова к их словарной (нормальной) форме, учитывая морфологию языка (например, "бежал" -> "бежать")․ Это требует использования словарей и морфологических правил․ Здесь spaCy проявляет себя наилучшим образом, предлагая высококачественную лемматизацию для множества языков, включая русский․ Для языков с богатой морфологией, таких как русский, мы также активно используем библиотеку Stanza, которая предоставляет продвинутые инструменты для лемматизации и синтаксического анализа․
Вот пример того, как мы можем использовать NLTK для токенизации и стемминга:
import nltk
from nltk․stem import PorterStemmer
from nltk․tokenize import word_tokenize
text = "Мы бежали, бежим и будем бежать к нашим целям․"
tokens = word_tokenize(text)
stemmer = PorterStemmer
stemmed_tokens = [stemmer․stem(word) for word in tokens]
print("Токены:", tokens)
print("Стеммированные токены (английский стеммер):", stemmed_tokens)
Для более точной лемматизации на русском языке мы обычно обращаемся к spaCy:
import spacy
Загружаем русскую модель
spacy․cli․download("ru_core_news_sm") # Если модель не установлена
nlp = spacy․load("ru_core_news_sm")
text = "Мы бежали, бежим и будем бежать к нашим целям․"
doc = nlp(text)
lemmas = [token․lemma_ for token in doc]
print("Леммы:", lemmas)
Очистка и Нормализация Текста: Избавляемся от Шума
После того как мы разбили текст на токены, нам часто нужно избавиться от "шума" – слов, которые не несут смысловой нагрузки для нашей конкретной задачи․ К таким словам относятся:
- Стоп-слова (Stop Words): Артикли, предлоги, союзы (например, "и", "в", "на", "a", "the")․ NLTK предоставляет списки стоп-слов для разных языков, и мы всегда можем дополнить их собственными списками․
- Пунктуация: Запятые, точки, восклицательные знаки․ Часто они удаляются или заменяются пробелами․
- Числа: В зависимости от задачи, числа могут быть удалены, заменены на специальный токен (например, `
`) или оставлены․ - HTML-теги: При парсинге веб-страниц с помощью Beautiful Soup, мы получаем текст с HTML-тегами, которые необходимо удалить․
- Сленг, эмодзи, неполные и ошибочные данные: Работа с современными текстами, особенно из социальных сетей, требует специальных подходов для нормализации сленга, обработки эмодзи и исправления опечаток․ Здесь нам помогают регулярные выражения (`re`) и специализированные словари․
Регулярные выражения (`re`) – это наш незаменимый инструмент для поиска и манипулирования текстовыми паттернами․ Они позволяют нам легко удалять нежелательные символы, приводить текст к нижнему регистру, выделять определенные конструкции․ Мы часто начинаем предобработку с перевода всего текста в нижний регистр, чтобы избежать дублирования слов из-за разного регистра․
Для более сложных задач очистки, например, от HTML-тегов, мы используем библиотеку Beautiful Soup, которая позволяет нам извлекать чистый текст из веб-страниц․ Также, когда мы работаем с текстом из PDF-документов, PyMuPDF становится нашим верным помощником для извлечения текстового контента․
От Слов к Числам: Векторизация Текста
Компьютеры не "понимают" слова в том смысле, в каком их понимаем мы․ Для того чтобы алгоритмы машинного обучения могли работать с текстом, его необходимо преобразовать в числовое представление – векторы․ Это один из самых захватывающих этапов, где мы видим, как абстрактные концепции языка обретают математическую форму․ Мы исследовали множество подходов к векторизации и готовы поделиться наиболее эффективными․
Простые, но Эффективные Методы: CountVectorizer и TF-IDF
Начнем с классики․ CountVectorizer из библиотеки Scikit-learn – это простой, но мощный способ преобразования коллекции текстовых документов в матрицу подсчета токенов․ Каждая строка матрицы соответствует документу, а каждый столбец – уникальному слову (токену) во всем корпусе․ Значение в ячейке показывает, сколько раз данное слово встречается в данном документе․ Это отличная отправная точка для многих задач․
Однако, CountVectorizer имеет один недостаток: он не учитывает важность слов․ Например, очень частые слова, такие как "и", "в", могут иметь высокие частоты, но не нести много уникальной информации․ Здесь на помощь приходит TfidfVectorizer (Term Frequency-Inverse Document Frequency)․ TF-IDF взвешивает частоту слова в документе (TF) с обратной частотой документа (IDF), которая показывает, насколько редко слово встречается во всем корпусе․ Таким образом, слова, которые часто встречаются в одном документе, но редко во всем корпусе, получают больший вес, что делает их более значимыми․ Мы часто используем TF-IDF для задач классификации и извлечения ключевых слов, поскольку он отлично выделяет наиболее релевантные термины․
Пример использования TfidfVectorizer:
from sklearn․feature_extraction․text import TfidfVectorizer
corpus = [
"Этот документ о машинах и технологиях․",
"Машины и технологии важны для будущего․",
"Будущее технологий интересно и сложно․"
]
vectorizer = TfidfVectorizer
tfidf_matrix = vectorizer․fit_transform(corpus)
print("Размерность TF-IDF матрицы:", tfidf_matrix․shape)
print("Список слов (признаков):", vectorizer․get_feature_names_out)
print("TF-IDF значения для первого документа:
", tfidf_matrix[0]․toarray)
Глубокое Понимание: Word Embeddings (Word2Vec, GloVe, FastText)
TF-IDF – это хорошо, но он не учитывает семантическую связь между словами․ "Кошка" и "кот" для TF-IDF – это просто разные слова, хотя мы понимаем, что они очень близки по смыслу․ Здесь в игру вступают Word Embeddings – векторные представления слов, которые отображают их семантические и синтаксические отношения в многомерном пространстве․ Слова с похожим значением будут располагаться близко друг к другу в этом пространстве․ Это был настоящий прорыв в NLP, который значительно улучшил качество многих задач․
Мы активно используем библиотеку Gensim для работы с Word Embeddings․ Она предоставляет эффективные реализации таких моделей, как Word2Vec и Doc2Vec․ Word2Vec имеет две основные архитектуры: Skip-gram и CBOW․ Skip-gram предсказывает контекстные слова по данному слову, а CBOW (Continuous Bag-of-Words) предсказывает слово по его контексту․ Оба подхода позволяют нам получить плотные векторы слов, которые удивительно точно отражают их смысл․
GloVe (Global Vectors for Word Representation) – это еще один популярный метод, который, в отличие от Word2Vec, основан на глобальной статистике со-встречаемости слов во всем корпусе․ Мы часто экспериментируем с обоими подходами, выбирая тот, который лучше подходит для конкретной задачи и объема данных․
Для работы с редкими словами и морфологически богатыми языками мы обращаемся к FastText․ Эта модель, также разработанная Facebook, представляет слова как набор символьных n-грамм․ Это позволяет ей генерировать векторные представления даже для слов, которые не встречались во время обучения, просто комбинируя векторы своих составляющих n-грамм․ Это делает FastText особенно ценным для русского языка, где много словоизменений․
Кроме векторизации отдельных слов, нам часто требуется векторизовать целые предложения или документы․ Для этого мы применяем Doc2Vec (расширение Word2Vec) или современные Sentence Transformers, которые создают высококачественные векторные представления для предложений и параграфов, сохраняя их семантическое значение․
"Язык – это не просто набор слов; это сложная система, отражающая наши мысли, эмоции и культуру․ Понимание языка машинами открывает двери в будущее, где технологии будут по-настоящему интуитивными․"
— Йошуа Бенджио (один из пионеров глубокого обучения и NLP)
Ключевые Задачи NLP: От Поиска Сущностей до Анализа Тональности
После того как мы подготовили и векторизовали наш текст, мы можем переходить к решению конкретных задач․ Именно здесь NLP показывает свою истинную мощь, позволяя нам извлекать ценную информацию из огромных объемов данных․ Мы накопили обширный опыт в применении различных методов для решения этих задач․
Распознавание Именованных Сущностей (NER)
Одной из фундаментальных задач в NLP является Распознавание Именованных Сущностей (NER)․ Это процесс идентификации и классификации именованных сущностей в тексте по заранее определенным категориям, таким как имена людей, названия организаций, локации, даты, суммы денег и т․д․ NER является критически важным для информационного извлечения, вопросно-ответных систем и многих других приложений․
Для быстрого и эффективного NER мы активно используем spaCy․ Эта библиотека поставляется с предварительно обученными моделями для различных языков, которые обеспечивают высокую точность и скорость․ Мы также применяем более продвинутые подходы, такие как Conditional Random Fields (CRF) для задач, требующих высокой кастомизации или работы с специфическими типами сущностей․ В последнее время мы все чаще обращаемся к библиотеке Flair, которая предлагает современные подходы к NER, основанные на глубоких контекстных встраиваниях (contextual embeddings), что позволяет достигать state-of-the-art результатов․
Вот как мы можем использовать spaCy для NER:
import spacy
nlp = spacy․load("ru_core_news_sm")
text = "Александр Пушкин родился в Москве 6 июня 1799 года․"
doc = nlp(text)
print("Сущности в тексте:")
for ent in doc;ents:
print(f" {ent․text} ({ent․label_})")
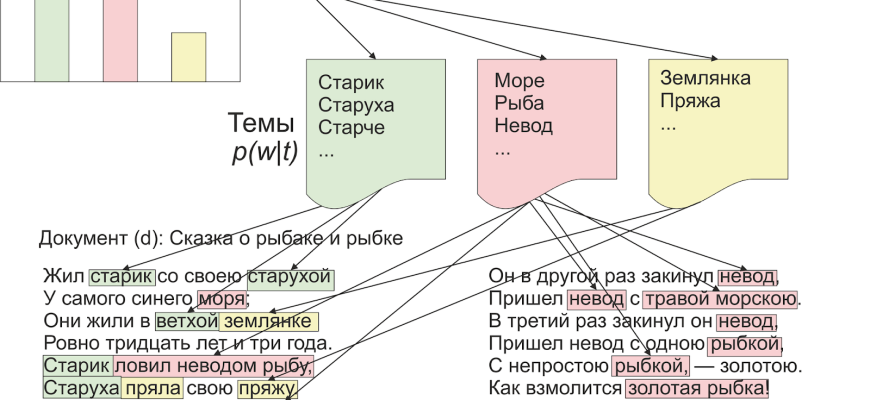
Тематическое Моделирование: Открываем Скрытые Темы
Представьте, что у вас есть огромный архив документов, и вы хотите понять, о чем они вообще․ Тематическое моделирование – это набор алгоритмов, которые позволяют нам автоматически обнаруживать скрытые "темы" в коллекции текстов․ Каждая тема представляется как набор слов, которые часто встречаются вместе․
Мы регулярно используем библиотеку Gensim для тематического моделирования, в частности, для реализации LDA (Latent Dirichlet Allocation) и LSI (Latent Semantic Indexing)․ LDA – это вероятностная модель, которая предполагает, что каждый документ состоит из смеси нескольких тем, а каждая тема – из смеси слов․ LSI, в свою очередь, использует сингулярное разложение (SVD) для выявления латентных семантических связей между терминами и документами․
Мы также сравниваем эти модели с NMF (Non-negative Matrix Factorization), которая является альтернативным методом для тематического моделирования․ Выбор между LDA, LSI и NMF часто зависит от характеристик данных и конкретной задачи, и мы проводим эксперименты, чтобы определить наилучший подход․
Классификация Текстов: Автоматическое Распределение по Категориям
Классификация текстов – одна из самых распространенных задач NLP․ Она включает в себя присвоение заранее определенных категорий текстовым документам․ Это может быть классификация спама, определение тематики новостных статей, категоризация отзывов клиентов по продуктам и многое другое․
Для классификации текстов мы активно применяем Scikit-learn․ Эта библиотека предоставляет широкий спектр алгоритмов машинного обучения, таких как SVM (Support Vector Machines), Naive Bayes Classifier, логистическая регрессия и другие․ Мы обычно начинаем с простых моделей, таких как Naive Bayes, которые часто дают хорошие базовые результаты, а затем переходим к более сложным, таким как SVM, для повышения точности․
С развитием глубокого обучения мы стали использовать PyTorch и TensorFlow для создания нейросетей, таких как LSTM (Long Short-Term Memory), которые особенно хорошо справляются с последовательными данными, такими как текст․ А с появлением трансформеров и моделей типа BERT, мы добиваемся еще более впечатляющих результатов, тонко настраивая (fine-tuning) предварительно обученные модели для наших конкретных задач классификации․
Анализ Тональности (Sentiment Analysis): Понимаем Эмоции
Понимание эмоциональной окраски текста – это бесценный навык в современном мире․ Анализ тональности (Sentiment Analysis) позволяет нам определить, является ли текст позитивным, негативным или нейтральным․ Это особенно полезно для анализа отзывов клиентов, постов в социальных сетях и финансовых новостей․
Для быстрого и простого анализа тональности на английском языке мы часто используем VADER (Valence Aware Dictionary and sEntiment Reasoner), который входит в состав NLTK․ VADER специально разработан для работы с текстами из социальных сетей и учитывает такие нюансы, как заглавные буквы, пунктуация и эмодзи․ Для более общих задач и на других языках мы применяем TextBlob, хотя для серьезных проектов мы разрабатываем собственные модели, используя классификаторы Scikit-learn или глубокие нейронные сети, обученные на размеченных данных․
Мы также сталкиваемся с проблемами анализа тональности в социальных сетях, где текст часто содержит сарказм, иронию и сленг․ Для таких случаев мы разрабатываем более сложные модели, которые учитывают контекст и могут различать тонкие оттенки настроения․ Например, мы используем специальные словари сленга и эмодзи, а также трансформерные модели, которые способны улавливать эти сложности․
Глубокое Погружение: Трансформеры и Продвинутые Модели
Последние несколько лет стали революционными для NLP благодаря появлению архитектуры трансформеров․ Эти модели, такие как BERT, GPT, T5, изменили правила игры, позволив достигать беспрецедентных результатов в самых сложных задачах․ Мы были одними из первых, кто начал активно внедрять трансформеры в свои проекты, и теперь они составляют основу многих наших решений․
Эра Трансформеров: Hugging Face и Предварительно Обученные Модели
Библиотека Hugging Face Transformers стала де-факто стандартом для работы с трансформерными моделями․ Она предоставляет удобный интерфейс для загрузки и использования сотен предварительно обученных моделей для различных языков и задач․ Мы используем их для:
- Сложных задач NER: Трансформеры значительно превосходят традиционные методы в распознавании сущностей, особенно в контекстно-зависимых сценариях․
- Классификации: Тонкая настройка (Fine-tuning) BERT-подобных моделей на наших данных даёт исключительные результаты в классификации текстов по различным категориям․
- Генерации текста: Модели GPT-подобных архитектур позволяют нам генерировать связный и осмысленный текст для суммаризации, создания диалогов и даже написания кода․
- Машинного перевода: Трансформерные архитектуры лежат в основе современных систем машинного перевода, обеспечивая высокую точность и естественность перевода․
Одним из ключевых преимуществ трансформеров является возможность тонкой настройки (fine-tuning) предварительно обученных моделей на наших специфических данных․ Это позволяет нам использовать огромные знания, полученные моделью на миллиардах текстов, и адаптировать их к уникальным особенностям нашей задачи, значительно сокращая время и ресурсы на обучение․
Таблица ниже демонстрирует некоторые ключевые трансформерные архитектуры и их основные применения, которые мы активно используем:
| Архитектура | Основные задачи | Ключевые особенности |
|---|---|---|
| BERT (Bidirectional Encoder Representations from Transformers) | NER, классификация, вопросно-ответные системы | Двунаправленное контекстное понимание, маскирование слов |
| GPT (Generative Pre-trained Transformer) | Генерация текста, суммаризация, диалоги | Авторегрессионная генерация, ориентирована на продолжение текста |
| RoBERTa | NER, классификация | Оптимизированная версия BERT с улучшенным предобучением |
| T5 (Text-to-Text Transfer Transformer) | Перевод, суммаризация, вопросно-ответные системы | Все задачи формулируются как "текст в текст" |
| DistilBERT | NER, классификация (легковесная) | Уменьшенная и ускоренная версия BERT с сохранением производительности |
Отдельные Сети: LSTM и Нейросети на PyTorch/TensorFlow
До эпохи трансформеров, рекуррентные нейронные сети, в частности LSTM (Long Short-Term Memory), были передовым решением для обработки последовательных данных․ Мы по-прежнему используем LSTM-сети, построенные с помощью PyTorch или TensorFlow/Keras, для специфических задач, где требуется моделирование длинных зависимостей в тексте, например, для анализа временных рядов в текстовых данных или для создания более простых, но эффективных моделей без тяжелой трансформерной архитектуры․ Они остаются ценным инструментом в нашем арсенале, особенно когда требуется более легкая и быстрая модель․
Практические Приложения и Специальные Вызовы
NLP – это не только теоретические модели, но и мощный инструмент для решения реальных проблем․ В нашей практике мы сталкиваемся с самыми разнообразными задачами, требующими творческого подхода и глубокого понимания как языка, так и технологий․
Создание Интеллектуальных Систем: От QA до Чат-ботов
Вопросно-ответные системы (QA): Мы разрабатываем QA-системы, которые могут автоматически отвечать на вопросы на основе большого корпуса документов․ Это может быть извлечение точного ответа (экстрактивные QA) или генерация нового ответа (абстрактивные QA)․ Трансформеры, такие как BERT, стали основой для создания высокоточных экстрактивных QA-систем․
Чат-боты: Разработка чат-ботов на Python, особенно с использованием фреймворка Rasa, позволяет нам создавать интеллектуальных виртуальных ассистентов, способных понимать намерения пользователя, извлекать сущности из запросов и вести диалог․ Мы используем NLP для обработки естественного языка в диалоговых системах, улучшая их способность к взаимодействию․
Суммаризация текста: Мы создаем системы для автоматической суммаризации текста, которые могут быть как экстрактивными (извлечение ключевых предложений), так и абстрактивными (генерация нового, сокращенного текста)․ Для экстрактивной суммаризации мы часто используем алгоритмы на основе графов, такие как TextRank, а для абстрактивной – трансформерные модели․
Анализ и Извлечение Информации: От Ключевых Фраз до Юридических Документов
Извлечение ключевых фраз: Для быстрого извлечения наиболее важных фраз из текста мы применяем алгоритмы, такие как RAKE (Rapid Automatic Keyword Extraction), а также методы на основе TF-IDF и TextRank․
Анализ частотности слов и n-грамм: Это базовый, но очень информативный метод для понимания структуры текста, выявления популярных тем и определения стилистики․ Мы также анализируем частотность имен собственных и редких слов, чтобы получить более глубокое понимание․
Работа с многоязычными корпусами: Мы регулярно работаем с текстами на разных языках․ Библиотеки Polyglot и Stanza являются нашими основными инструментами для обработки многоязычных текстовых корпусов, предоставляя возможности для токенизации, лемматизации и POS-теггинга для языков с богатой морфологией․
Анализ юридических и финансовых документов: Это сложная, но крайне важная область․ Мы используем NLP для извлечения ключевых дат, имен, сумм, условий и других сущностей из юридических контрактов и финансовых отчетов․ Это помогает автоматизировать процессы аудита и анализа․
Обнаружение плагиата: Сравнение текстов для выявления сходства – еще одна задача, где NLP незаменим․ Мы применяем различные метрики сходства, такие как Jaccard, Cosine Similarity, а также библиотеки типа TextDistance и Jellyfish для сравнения строк и выявления дубликатов․
Специфические Вызовы и Инструменты
Обработка неполных и ошибочных данных: Реальный мир редко предлагает идеальные данные․ Мы разрабатываем инструменты для проверки грамматики и исправления орфографии, используем эвристические правила и модели глубокого обучения для работы с "шумными" данными․
Анализ стилистики текстов: Определение авторского почерка, тональности, сложности предложений – все это возможно с помощью NLP․ Мы анализируем лексическое богатство, частотность определенных конструкций и другие стилистические признаки․
Визуализация текстовых данных: Для лучшего понимания данных мы используем такие инструменты, как Word Clouds (облака слов) для визуализации частотности слов и Heatmaps для отображения взаимосвязей между терминами․
Big Data NLP: Когда объемы текстовых данных становятся колоссальными, мы применяем распределенные вычисления и оптимизированные библиотеки, такие как Gensim, для эффективной обработки больших текстовых массивов․
Обработка в реальном времени (Streaming NLP): Для таких задач, как анализ сообщений в социальных сетях, нам приходится обрабатывать текст в режиме реального времени․ Это требует оптимизированных пайплайнов и эффективных моделей․
Мы прошли долгий путь, от основ токенизации до сложнейших трансформерных архитектур, исследуя бескрайние возможности NLP на Python․ Наш опыт показывает, что эта область продолжает стремительно развиваться, предлагая все новые и новые инструменты для понимания и взаимодействия с человеческим языком․ От анализа отзывов клиентов и автоматизации юридических процессов до создания интеллектуальных ассистентов и систем машинного перевода – NLP уже сегодня меняет наш мир, и его потенциал огромен․
Мы надеемся, что это путешествие вдохновило вас на собственные исследования и эксперименты․ Не бойтесь начинать с малого, использовать готовые библиотеки и постепенно углубляться в математику и алгоритмы․ Мир NLP открыт для всех, кто готов разгадывать тайны текста․ Помните, что каждый текст – это не просто набор символов, это источник информации, знаний и эмоций, который с помощью правильных инструментов мы можем раскрыть и использовать во благо․ Продолжайте учиться, экспериментировать и творить, ведь будущее, где машины и люди беспрепятственно общаются, уже не за горами․
На этом статья заканчивается․
Подробнее
| Python NLP библиотеки | Токенизация и стемминг NLTK | Распознавание именованных сущностей spaCy | Тематическое моделирование Gensim | Анализ тональности Python |
| Word Embeddings Word2Vec GloVe | Трансформеры Hugging Face | Классификация текстов Scikit-learn | Лемматизация текста Python | Разработка чат-ботов Python |







