
- Раскрываем Тайны Текста: Наш Путь в Мир Обработки Естественного Языка с Python
- Первые Шаги: Подготовка Текста к Анализу
- NLTK: Наш Верный Спутник в Токенизации и Стемминге
- Продвинутая Лемматизация и Стемминг: Когда Корня Недостаточно
- Регулярные Выражения (re) и Очистка Текста
- Превращаем Слова в Числа: Векторизация Текста
- Классические Векторизаторы: CountVectorizer и TF-IDF
- Word Embeddings: От Слова к Смыслу (Word2Vec, GloVe, FastText, Doc2Vec)
- Векторизация Предложений и Документов с Учетом Контекста
- Ключевые Задачи NLP: От Распознавания до Тематического Моделирования
- spaCy: Быстрое NER и Синтаксический Парсинг
- Gensim: Властелин Тематического Моделирования
- Scikit-learn: Наш Выбор для Классификации Текстов
- Анализ Тональности (Sentiment Analysis): Понимание Эмоций
- Продвинутые Инструменты и Глубокое Обучение в NLP
- Трансформеры (Hugging Face): Новый Горизонт в NLP
- PyTorch/TensorFlow и LSTM-сети
- Flair: Современный NER и Другие Задачи
- Специализированные Инструменты и Прикладные Задачи
- Извлечение Ключевых Фраз и Суммаризация
- Работа с Различными Источниками Текста
- Многоязычный NLP и Специфические Языки
- Чат-боты и Диалоговые Системы (Rasa)
- Визуализация Текстовых Данных
- Нестандартные Задачи и Новые Горизонты
- Анализ Стилистики и Авторства
- Проверка Грамматики и Орфографии
- Извлечение Фактов и Обнаружение Плагиата
- Big Data NLP и GPU-ускорение
- Оценка Качества Моделей NLP
Раскрываем Тайны Текста: Наш Путь в Мир Обработки Естественного Языка с Python
Добро пожаловать в наш блог, дорогие читатели! Сегодня мы погрузимся в одну из самых увлекательных и быстро развивающихся областей искусственного интеллекта – обработку естественного языка, или NLP (Natural Language Processing). Нам предстоит захватывающее путешествие по миру, где машины учатся понимать, интерпретировать и даже генерировать человеческую речь. Это не просто академическая дисциплина; это ключ к созданию более интуитивных голосовых помощников, интеллектуальных чат-ботов, систем автоматического перевода и многого другого, что уже сегодня меняет нашу повседневную жизнь.
Мы с вами живем в эпоху, когда информация стала самой ценной валютой, а большая её часть представлена в виде текста. От твитов и отзывов до научных статей и юридических документов – мир буквально плавает в словах. Но как заставить компьютер "читать" и "понимать" этот огромный массив данных? Именно здесь на помощь приходит NLP, вооруженный мощными инструментами Python. Мы накопили значительный опыт в этой сфере и хотим поделиться с вами нашими практическими знаниями, начиная с самых основ и заканчивая продвинутыми техниками, которые мы применяем в наших проектах. Приготовьтесь, ведь мы собираемся не просто рассказать, а показать, как можно превратить хаотичный поток слов в структурированные, ценные инсайты.
Первые Шаги: Подготовка Текста к Анализу
Прежде чем мы сможем научить машину "читать", нам нужно подготовить текст. Представьте, что вы хотите испечь пирог. Вы не будете просто бросать все ингредиенты в миску без подготовки. С текстом то же самое – его нужно очистить, разделить на понятные части и привести к стандартному виду. Этот этап, известный как предобработка, является фундаментом любого проекта NLP. Мы используем несколько ключевых техник, чтобы сделать текст пригодным для дальнейшего анализа.
NLTK: Наш Верный Спутник в Токенизации и Стемминге
Одной из первых библиотек, с которой мы познакомились в мире NLP, была NLTK (Natural Language Toolkit). Она стала для нас незаменимым инструментом для базовой предобработки. Начнем с токенизации – процесса разбиения текста на отдельные слова или фразы, которые мы называем токенами. Это как разобрать предложение на кирпичики, из которых оно построено. Мы используем разные токенизаторы: для слов (`word_tokenize`) и для предложений (`sent_tokenize`), в зависимости от наших задач.
После токенизации часто возникает другая проблема: одно и то же слово может иметь разные формы (например, "бежать", "бежит", "бегал"). Чтобы компьютер воспринимал их как одно и то же понятие, мы применяем стемминг или лемматизацию. Стемминг – это процесс отсечения окончаний и суффиксов, чтобы получить "корень" слова (например, "бежать" -> "беж"). Мы часто используем стеммеры вроде Портера или Сноуболла. Хотя стемминг быстр, он не всегда дает реальное слово, а скорее его "основу".
Продвинутая Лемматизация и Стемминг: Когда Корня Недостаточно
Как мы уже упоминали, стемминг может быть немного "грубым". Он отрезает части слова, не заботясь о том, является ли результат настоящим словом. Например, "красивый", "красота" могут стать "красив". В случаях, когда нам требуется лингвистически корректная базовая форма слова, мы переходим к лемматизации. Лемматизация использует словарь и морфологический анализ, чтобы привести слово к его словарной форме (лемме). Так, "бежал", "бежит", "бегущий" станут "бежать". Для русского языка мы часто обращаемся к библиотекам, которые поддерживают богатую морфологию, таким как spaCy или Stanza, о которых мы поговорим чуть позже. Они предоставляют более точные леммы, что критически важно для многих задач, например, для построения языковых моделей или анализа текстов отзывов.
Регулярные Выражения (re) и Очистка Текста
Помимо токенизации и лемматизации, нам постоянно приходится иметь дело с "шумом" в тексте. Это могут быть HTML-теги, пунктуация, специальные символы, ссылки, цифры или стоп-слова (часто встречающиеся слова, не несущие смысловой нагрузки, такие как "и", "в", "на"). Для борьбы с этим мы активно используем регулярные выражения (библиотека `re` в Python). Это мощный инструмент для поиска и замены текстовых паттернов.
Вот типичные задачи очистки, которые мы выполняем:
- Удаление HTML-тегов: часто при веб-скрейпинге мы получаем текст с разметкой. Регулярные выражения позволяют нам легко удалить все `
`, `
` и другие теги. - Нормализация пунктуации: иногда мы удаляем всю пунктуацию, а иногда заменяем её пробелами или стандартизируем.
- Удаление стоп-слов: с помощью предопределенных списков стоп-слов (доступных в NLTK или spaCy) мы фильтруем слова, которые не добавляют ценности нашему анализу.
- Работа с эмодзи и сленгом: в социальных сетях эмодзи и сленг играют огромную роль. Мы разрабатываем специальные словари и правила для их обработки, чтобы они не теряли смысл, или же удаляем их, если они нерелевантны.
- Обработка неполных и ошибочных данных: в реальных данных часто встречаются опечатки, сокращения, неполные предложения. Для этого мы применяем методы нечеткого поиска, сравнения строк (например, с библиотекой Jellyfish) и даже собственные правила нормализации.
Мы часто создаем собственный инструментарий для очистки текста, адаптированный под конкретные задачи. Например, для анализа лог-файлов или юридических документов требуются совершенно разные подходы к фильтрации и извлечению информации.
Превращаем Слова в Числа: Векторизация Текста
Компьютеры понимают только числа. Поэтому, после тщательной предобработки, следующим критически важным шагом является преобразование текста в числовое представление – векторизация. Это позволяет нам применять математические и статистические методы, а также алгоритмы машинного обучения. Мы используем различные подходы, каждый из которых имеет свои преимущества.
Классические Векторизаторы: CountVectorizer и TF-IDF
Начнем с простых, но эффективных методов. CountVectorizer из библиотеки Scikit-learn просто подсчитывает частоту появления каждого слова в документе. Мы получаем вектор, где каждая позиция соответствует уникальному слову из всего корпуса текстов, а значение – количеству его появлений в текущем документе. Это отличный способ для первого знакомства с векторизацией.
Однако, проблема с CountVectorizer заключается в том, что очень частые слова (вроде "и", "в" – даже после удаления стоп-слов) могут доминировать, не неся при этом много уникальной информации. Здесь на помощь приходит TfidfVectorizer (Term Frequency-Inverse Document Frequency). Этот метод не только учитывает частоту слова в документе (TF), но и его редкость во всем корпусе документов (IDF). Чем реже слово встречается в целом, тем больше его "вес" в конкретном документе. Это позволяет нам выделить наиболее информативные слова.
Мы часто сравниваем эти методы:
| Метод | Преимущества | Недостатки | Применение |
|---|---|---|---|
| CountVectorizer | Прост, быстр, сохраняет информацию о частоте. | Не учитывает важность слова в контексте всего корпуса. | Базовая классификация, анализ частотности слов. |
| TfidfVectorizer | Учитывает важность слова, выделяет уникальные термины. | Более сложен, может создавать очень разреженные матрицы. | Поиск релевантных документов, тематическое моделирование, классификация. |
Word Embeddings: От Слова к Смыслу (Word2Vec, GloVe, FastText, Doc2Vec)
Классические векторизаторы рассматривают слова как независимые сущности. Но мы знаем, что слова имеют смысл и контекст. Здесь в игру вступают Word Embeddings – векторные представления слов, которые улавливают их семантические отношения. Идея в том, что слова, появляющиеся в похожих контекстах, должны иметь похожие векторные представления.
Мы активно используем:
- Word2Vec (Gensim): Эта модель, разработанная Google, позволяет нам обучать векторные представления слов. Она имеет два основных подхода: Skip-gram (предсказывает контекстные слова по целевому слову) и CBOW (предсказывает целевое слово по контексту). Мы часто используем Gensim для эффективного обучения Word2Vec на наших собственных корпусах текстов.
- GloVe (Global Vectors for Word Representation): GloVe – еще один популярный метод, который сочетает в себе преимущества глобальных матриц частотности и локальных контекстных окон. Он также создает плотные векторы, которые хорошо улавливают семантику.
- FastText: Разработанный Facebook, FastText расширяет идею Word2Vec, учитывая подсловные единицы (n-граммы символов). Это делает его особенно эффективным для работы с редкими словами и языками с богатой морфологией, где многие слова встречаются редко. Мы ценим FastText за его способность создавать векторы даже для слов, которых не было в обучающем корпусе.
- Doc2Vec (Gensim): Если Word2Vec дает векторы для слов, то Doc2Vec (также известный как Paragraph Vector) позволяет получать векторные представления для целых предложений, параграфов или документов. Это невероятно полезно, когда нам нужно сравнивать документы по смыслу или кластеризовать их.
Векторизация Предложений и Документов с Учетом Контекста
С развитием глубокого обучения появились еще более продвинутые методы векторизации, которые учитывают не только семантику слов, но и их контекст в предложении. Sentence Transformers – это библиотека, которая позволяет нам получать высококачественные векторные представления предложений и документов, которые можно напрямую использовать для сравнения сходства, кластеризации и поиска. Векторизация с учетом контекста, такая как та, что используется в BERT и других трансформерах, произвела революцию в NLP, позволяя нам улавливать тончайшие нюансы смысла.
Ключевые Задачи NLP: От Распознавания до Тематического Моделирования
Теперь, когда мы умеем подготавливать текст и превращать его в числа, пришло время решать реальные задачи. Мир NLP огромен, и мы используем множество библиотек и техник для различных целей.
spaCy: Быстрое NER и Синтаксический Парсинг
Если NLTK – это наша "швейцарская армия" для основ, то spaCy – это наш "скоростной болид" для промышленного NLP. Эта библиотека известна своей скоростью и оптимизацией. Мы используем spaCy для:
- Распознавания именованных сущностей (NER): spaCy позволяет нам быстро извлекать из текста такие сущности, как имена людей, организации, местоположения, даты и денежные суммы. Это критически важно для извлечения информации из неструктурированного текста. Например, в юридических документах мы используем NER для автоматического выявления сторон, дат и условий договора.
- Синтаксического парсинга и анализа зависимостей: spaCy строит синтаксическое дерево предложения, показывая, как слова связаны друг с другом. Это помогает нам понять структуру предложения и роль каждого слова. Анализ зависимостей незаменим для более глубокого понимания текста, например, при разработке вопросно-ответных систем.
- POS-теггинга (Part-of-Speech Tagging): Определение части речи каждого слова (существительное, глагол, прилагательное и т.д.).
Мы часто сравниваем spaCy с NLTK по скорости и возможностям для конкретных задач, и для продакшн-систем spaCy обычно наш выбор из-за его производительности.
Gensim: Властелин Тематического Моделирования
Когда у нас есть большой корпус документов, и мы хотим понять, о чем они, мы обращаемся к тематическому моделированию. Gensim – это наша go-to библиотека для этой задачи.
- LDA (Latent Dirichlet Allocation): Одна из самых популярных моделей тематического моделирования. LDA позволяет нам обнаружить "скрытые" темы в коллекции документов, предполагая, что каждый документ представляет собой смесь нескольких тем, а каждая тема – это смесь слов. Мы используем LDA для анализа текстов отзывов клиентов, чтобы выявить основные проблемы или преимущества продукта.
- LSI (Latent Semantic Indexing): Другой метод тематического моделирования, основанный на сингулярном разложении (SVD) матрицы "терм-документ". LSI помогает нам выявить скрытые семантические связи между словами и документами.
Мы часто проводим сравнение моделей тематического моделирования (LDA vs NMF). NMF (Non-negative Matrix Factorization) – это еще один мощный метод, который часто дает более интерпретируемые темы, особенно когда мы работаем с разреженными данными. Выбор между ними зависит от характеристик данных и конкретной цели проекта.
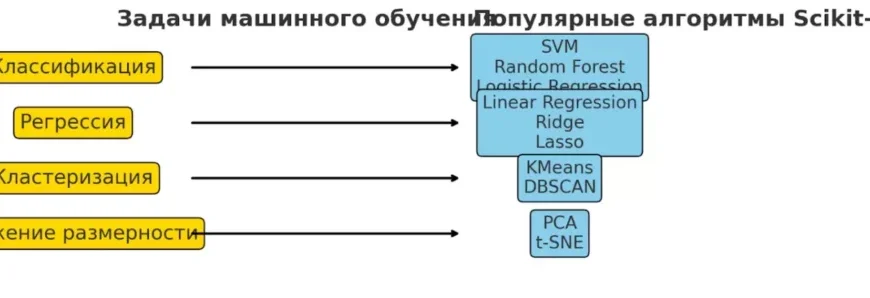
Scikit-learn: Наш Выбор для Классификации Текстов
Scikit-learn – это универсальная библиотека машинного обучения, и, конечно, мы активно используем её для задач NLP, в частности для классификации текстов. Будь то спам-фильтр, категоризация новостных статей или анализ тональности, Scikit-learn предоставляет широкий спектр алгоритмов.
Вот некоторые из тех, что мы применяем:
- Наивный байесовский классификатор (Naive Bayes): Простой, но часто очень эффективный для классификации текста, особенно на больших наборах данных.
- Метод опорных векторов (SVM — Support Vector Machine): Отлично справляется с текстами, особенно когда данных не очень много, но они хорошо разделяются.
- Логистическая регрессия, случайный лес, градиентный бустинг: Эти методы также показывают хорошие результаты в зависимости от сложности задачи и характеристик данных.
Мы также используем Scikit-learn для кластеризации текстов (например, K-Means или DBSCAN), когда нам нужно найти естественные группы документов без предварительной разметки.
Анализ Тональности (Sentiment Analysis): Понимание Эмоций
Понимание эмоциональной окраски текста – это одна из самых востребованных задач NLP. Мы используем анализ тональности для множества целей: от мониторинга социальных сетей до анализа отзывов клиентов и финансовых новостей.
- VADER (Valence Aware Dictionary and sEntiment Reasoner): Это лексический и основанный на правилах анализатор тональности, который специально обучен на текстах из социальных сетей. VADER отлично подходит для быстрого анализа тональности, особенно на коротких текстах. Он учитывает не только слова, но и их интенсивность, использование заглавных букв и пунктуацию.
- TextBlob: Для более простых случаев, когда нам нужен быстрый и легкий анализ тональности, мы обращаемся к TextBlob. Он предоставляет удобный интерфейс для определения полярности (позитивный/негативный) и субъективности текста.
- Модели машинного обучения: Для более сложных задач и специфических доменов (например, анализ тональности финансовых новостей или медицинских записей), мы обучаем собственные модели классификации, используя Scikit-learn или глубокое обучение. Мы также работаем над анализом тональности с учетом сарказма, что является одной из сложнейших задач в этой области.
"Язык – это дорожная карта культуры. Он говорит вам, откуда пришли его люди и куда они идут."
— Рита Мэй Браун
Продвинутые Инструменты и Глубокое Обучение в NLP
С появлением глубокого обучения и, в частности, архитектуры трансформеров, возможности NLP расширились до невообразимых пределов. Мы активно исследуем и применяем эти передовые технологии в наших проектах.
Трансформеры (Hugging Face): Новый Горизонт в NLP
Библиотека Hugging Face Transformers стала для нас настоящим открытием и краеугольным камнем в работе с современными моделями NLP. Это не просто библиотека, это целая экосистема, которая предоставляет доступ к сотням предварительно обученных моделей, таких как BERT, GPT, T5 и многие другие.
Что мы делаем с трансформерами:
- Сложные задачи NER: Трансформеры значительно превосходят традиционные методы в точности распознавания сущностей, особенно в сложных контекстах. Мы используем их для автоматической разметки сущностей и выявления связей между ними.
- Классификация текстов: С помощью BERT и его производных мы достигаем State-of-the-Art результатов в классификации, будь то анализ тональности или категоризация документов.
- Разработка систем вопросно-ответных систем (QA): Трансформеры позволяют нам строить системы, которые могут "читать" документ и отвечать на вопросы по его содержанию, что является огромным шагом вперед в информационном поиске.
- Суммаризация текста (Abstractive vs Extractive): Мы используем трансформеры для создания как экстрактивных (извлечение ключевых предложений), так и абстрактивных (генерация нового текста, передающего суть) суммаризаторов.
- Машинный перевод: Transformer-модели лежат в основе самых передовых систем машинного перевода, позволяя нам работать с многоязычными текстовыми корпусами и создавать системы автоматического перевода узкоспециализированных текстов.
- Генерация текста (GPT): Мы экспериментируем с моделями GPT для создания диалогов, генерации кода и даже написания креативных текстов.
- Тонкая настройка (Fine-tuning): Одной из ключевых особенностей трансформеров является возможность тонкой настройки предварительно обученных моделей на наших собственных данных, что позволяет адаптировать их под специфические задачи без необходимости обучать модель с нуля.
PyTorch/TensorFlow и LSTM-сети
До эпохи трансформеров, рекуррентные нейронные сети (RNN), особенно их разновидности LSTM (Long Short-Term Memory), были стандартом для многих задач NLP, требующих обработки последовательностей. Мы до сих пор используем PyTorch и TensorFlow/Keras для создания LSTM-сетей, особенно когда работаем с относительно небольшими наборами данных или когда требуется более прозрачная архитектура модели. LSTM-сети отлично подходят для задач, где важен порядок слов, таких как распознавание именованных сущностей или части речи. Мы применяем их для создания нейросетей NLP, когда трансформеры могут быть избыточными или слишком ресурсоемкими.
Flair: Современный NER и Другие Задачи
Библиотека Flair – это еще один мощный инструмент, который мы используем для современного NLP. Flair выделяется своими передовыми векторными представлениями слов (word embeddings), которые являются контекстуализированными и позволяют достигать высокой точности в таких задачах, как NER и POS-теггинг. Мы ценим Flair за его простоту использования и отличные результаты, особенно для многоязычных моделей. Он также предлагает возможности для суммаризации текста.
Специализированные Инструменты и Прикладные Задачи
Мир NLP не ограничивается только обработкой английского языка или стандартными задачами. Мы постоянно сталкиваемся с уникальными вызовами и используем специализированные инструменты для их решения.
Извлечение Ключевых Фраз и Суммаризация
Чтобы быстро понять суть большого текста, нам нужно извлечь ключевые слова или фразы.
- RAKE (Rapid Automatic Keyword Extraction): Это простой, но эффективный алгоритм для извлечения ключевых слов из текста на основе частотности и со-встречаемости слов. Мы часто используем его для быстрого анализа небольших текстов.
- TextRank: Основанный на алгоритме PageRank, TextRank позволяет нам извлекать ключевые слова и даже ключевые предложения. Это очень полезно для создания экстрактивных суммаризаторов, когда мы хотим выбрать наиболее важные предложения из документа. Мы применяем его для анализа статей и отчетов, чтобы быстро получить их краткое содержание.
Мы также работаем над разработкой системы суммаризации текста, сравнивая подходы: экстрактивный (выбор наиболее важных предложений из оригинала) и абстрактивный (генерация нового, более краткого текста, который передает основную идею). Для абстрактивной суммаризации мы чаще всего обращаемся к трансформерным моделям.
Работа с Различными Источниками Текста
Текст поступает к нам из самых разных источников, и для каждого из них у нас есть свои инструменты:
- Beautiful Soup для веб-скрейпинга: Если нам нужен текст с веб-сайтов, мы используем библиотеку Beautiful Soup. Она позволяет нам парсить HTML и XML документы, легко извлекая нужный контент. Это наш основной инструмент для сбора больших текстовых массивов из интернета.
- PyMuPDF для извлечения текста из PDF: PDF-файлы – это распространенный формат для документов, и извлечение из них текста может быть нетривиальной задачей. PyMuPDF – это быстрая и надежная библиотека для работы с PDF, которая позволяет нам извлекать текст, изображения и метаданные. Мы используем её для анализа юридических документов, научных статей и отчетов.
- Анализ лог-файлов: Лог-файлы – это еще один источник неструктурированных текстовых данных, которые могут содержать ценную информацию. Мы разрабатываем специфические правила и регулярные выражения для извлечения ключевых событий, ошибок и временных меток из логов.
Многоязычный NLP и Специфические Языки
Мир не ограничивается одним языком, и наши проекты тоже.
- Polyglot: Эта библиотека позволяет нам работать с мультиязычными текстовыми корпусами, предоставляя поддержку для множества языков, включая их морфологический анализ, NER и определение языка. Мы используем Polyglot для анализа редких языков или когда нужна быстрая поддержка для большого количества языков.
- Stanza (Stanford NLP Group): Stanza – это мощная библиотека для NLP, разработанная Стэнфордским университетом. Она предоставляет предобученные нейронные сети для более чем 70 языков. Мы используем Stanza для языков с богатой морфологией, таких как русский, где требуется глубокий синтаксический и морфологический анализ. Stanza особенно полезна для точной лемматизации, POS-теггинга и анализа зависимостей на русском языке.
- Обработка нелатинских алфавитов: Работа с арабским, китайским или другими нелатинскими алфавитами требует особого подхода к токенизации, нормализации и векторизации. Мы используем специализированные модели и техники, чтобы корректно обрабатывать такие тексты.
Чат-боты и Диалоговые Системы (Rasa)
Разработка чат-ботов – это одно из самых захватывающих направлений NLP. Мы используем фреймворк Rasa для создания интеллектуальных чат-ботов на Python. Rasa позволяет нам строить сложные диалоговые системы с пониманием естественного языка (NLU) и управлением диалогом. Мы разрабатываем чат-боты для поддержки клиентов, автоматизации процессов и интерактивного взаимодействия с пользователями.
Визуализация Текстовых Данных
Визуализация помогает нам лучше понять данные и представить результаты анализа.
- Word Clouds: Облака слов – простой и наглядный способ показать наиболее частые слова в тексте. Чем больше слово, тем чаще оно встречается.
- Heatmaps: Тепловые карты мы используем для визуализации матриц сходства, например, между документами или темами.
- Sweetviz: Эта библиотека позволяет нам быстро проводить разведочный анализ данных, включая текстовые поля, и генерировать красивые визуальные отчеты.
Нестандартные Задачи и Новые Горизонты
Мир NLP постоянно развивается, и мы постоянно ищем новые способы применения этих технологий.
Анализ Стилистики и Авторства
Интересная область – анализ стилистики текстов и определение авторства. Мы используем различные лингвистические характеристики (длина предложений, частотность стоп-слов, использование определенных грамматических конструкций) для создания "отпечатка" стиля автора. Это может быть полезно в криминалистике, литературоведении или для проверки подлинности документов. Мы разрабатываем системы для определения стиля письма и авторства на основе этих метрик.
Проверка Грамматики и Орфографии
Мы также работаем над разработкой инструментов для проверки грамматики и исправления орфографии. Используя языковые модели и правила, мы можем выявлять и предлагать исправления для ошибок в тексте. Это важно для создания качественного контента и улучшения пользовательского опыта.
Извлечение Фактов и Обнаружение Плагиата
Разработка систем для извлечения фактов из новостей: С помощью NER и анализа зависимостей мы можем автоматически извлекать ключевые факты (кто, что, где, когда) из новостных статей.
Разработка систем обнаружения плагиата: Сравнение текстов на предмет сходства является ключевой задачей. Мы используем методы векторизации (TF-IDF, Doc2Vec) и библиотеки для измерения сходства строк/документов (например, Textdistance) для выявления плагиата.
Big Data NLP и GPU-ускорение
Работа с большими текстовыми массивами (Big Data NLP) требует особых подходов. Мы используем распределенные вычислительные системы и облачные платформы для обработки огромных объемов текста. Кроме того, для обучения и инференса сложных нейросетевых моделей, особенно трансформеров, мы активно применяем GPU-ускорение, что значительно сокращает время обработки.
Оценка Качества Моделей NLP
Любая модель бесполезна, если мы не можем оценить её эффективность. Мы используем стандартные метрики для оценки качества наших моделей NLP:
- Precision (точность): Доля правильно предсказанных положительных случаев из всех предсказанных положительных.
- Recall (полнота): Доля правильно предсказанных положительных случаев из всех реальных положительных.
- F1-score: Гармоническое среднее Precision и Recall, часто используемое как общая метрика производительности, особенно когда классы несбалансированы.
- Accuracy (правильность): Общая доля правильных предсказаний.
Мы также применяем эти метрики для оценки качества NER-моделей, классификаторов и других систем.
Как вы видите, мир обработки естественного языка огромен и постоянно предлагает новые вызовы и возможности. Мы, как блогеры и практики, стараемся быть на острие технологий, постоянно изучая новые библиотеки, алгоритмы и подходы. От простейшей токенизации до сложнейших трансформерных архитектур – каждый шаг в этом путешествии приносит нам новые знания и позволяет создавать всё более интеллектуальные системы.
Мы верим, что Python с его богатой экосистемой библиотек (NLTK, spaCy, Gensim, Scikit-learn, Hugging Face, PyTorch, TensorFlow и многие другие) является идеальным инструментом для исследования и применения NLP. Наш опыт показывает, что, несмотря на сложность человеческого языка, мы можем научить машины понимать его и извлекать из него ценные инсайты. Мы продолжим делиться нашими открытиями и практическими советами, вдохновляя вас на собственные эксперименты в этом увлекательном мире.
Подробнее
| Основы NLTK | spaCy NER | Gensim LDA | Трансформеры Hugging Face | Анализ тональности Python |
| Word Embeddings | Scikit-learn классификация | Продвинутая лемматизация | Разработка чат-ботов | Обработка Big Data NLP |





