
- Тайны Текста: Как Мы Превращаем Слова в Знания с Помощью Python и NLP
- Вступление: Почему NLP Сегодня Важнее‚ Чем Когда-Либо?
- От Сырого Текста к Чистым Данным: Первые Шаги в Предобработке
- Токенизация‚ Стемминг и Лемматизация: Разбираем Слова на Части
- Регулярные Выражения и Очистка Текста: Полируем Исходники
- Работа с Многоязычными Корпусами: Когда Один Язык Недостаточно
- Превращаем Слова в Числа: Методы Векторизации Текста
- Классические Векторизаторы: От Частотности к Важности
- Word Embeddings: Когда Слова Обретают Смысл в Пространстве
- Контекстные Встраивания и Трансформеры: Революция в Понимании Языка
- Ключевые Задачи NLP: Извлекаем Сущности‚ Темы и Настроения
- Распознавание Именованных Сущностей (NER): Кто‚ Что‚ Где и Когда?
- Тематическое Моделирование: Открываем Скрытые Темы
- Анализ Тональности (Sentiment Analysis): Понимаем Эмоции в Тексте
- Классификация Текстов: Сортируем и Категоризируем
- Суммаризация Текста: Сжимаем Информацию до Сути
- Продвинутые Применения и Специализированные Инструменты
- Генерация Текста и Вопросно-Ответные Системы: Творчество Машин
- Веб-Скрейпинг и Извлечение Информации: Добываем Данные
- Чат-боты и Виртуальные Ассистенты: Диалог с Искусственным Интеллектом
- Анализ Стилистики и Авторского Почерка: Заглядываем Глубже
- Вызовы и Перспективы: Будущее NLP
- Работа с "Грязными" Данными: Реальный Мир Текста
- Оценка Качества Моделей: Как Понять‚ Что Мы Делаем Правильно
- Масштабирование и Большие Данные: NLP в Индустрии
Тайны Текста: Как Мы Превращаем Слова в Знания с Помощью Python и NLP
Приветствуем‚ дорогие читатели и коллеги по цеху! Мы‚ как опытные исследователи и страстные блогеры‚ не перестаем удивляться тому‚ как много скрытой информации таится в обычных словах. Ежедневно в мире генерируются петабайты текстовых данных: от электронных писем и сообщений в социальных сетях до научных статей и юридических документов. И за всем этим потоком слов стоит нечто большее‚ чем просто набор символов. Это эмоции‚ намерения‚ факты‚ тренды и истории‚ ожидающие своего часа‚ чтобы быть обнаруженными и понятыми.
Наше путешествие в мир обработки естественного языка (NLP) на Python началось много лет назад‚ когда мы впервые осознали‚ какой колоссальный потенциал скрыт в способности машин понимать человеческий язык. С тех пор мы прошли долгий путь‚ осваивая различные библиотеки‚ алгоритмы и подходы‚ и хотим поделиться с вами нашим опытом. Эта статья — не просто технический гайд‚ это наше приглашение погрузиться в захватывающий процесс превращения хаотичного текста в структурированные‚ ценные знания. Мы покажем‚ как Python стал нашим верным спутником в этом приключении‚ открывая двери в мир интеллектуального анализа текстов.
Вступление: Почему NLP Сегодня Важнее‚ Чем Когда-Либо?
В эпоху цифровой трансформации и доминирования данных‚ способность эффективно работать с текстовой информацией стала не просто желательной‚ а абсолютно необходимой. Отзывы клиентов‚ новостные ленты‚ медицинские записи‚ юридические контракты‚ посты в социальных сетях – всё это огромные массивы неструктурированных данных‚ которые хранят в себе золотые крупицы инсайтов. Без NLP эти данные остаются мертвым грузом‚ но с его помощью мы можем вдохнуть в них жизнь‚ заставить говорить и раскрывать свои секреты.
Мы видим‚ как NLP меняет отрасли‚ от маркетинга и финансов до здравоохранения и образования. Компании используют его для понимания настроений клиентов‚ банки – для выявления мошенничества‚ медики – для анализа историй болезни‚ а юристы – для быстрого поиска прецедентов. Это не футуристические мечты‚ это наша реальность‚ которую мы строим каждый день‚ шаг за шагом‚ строка за строкой кода на Python. И мы здесь‚ чтобы показать вам‚ как вы можете стать частью этой революции.
От Сырого Текста к Чистым Данным: Первые Шаги в Предобработке
Прежде чем машина сможет "понять" текст‚ его необходимо подготовить. Представьте себе сырой алмаз – красивый‚ но требующий огранки. Точно так же и с текстом. Он полон шума‚ лишних символов‚ различных форм слов‚ которые могут сбить с толку даже самые продвинутые алгоритмы. Наш первый и один из самых важных шагов в любом проекте NLP – это тщательная предобработка данных. Именно здесь мы закладываем фундамент для всех последующих анализов.
Мы начинаем с того‚ что превращаем необработанный текст в нечто‚ что компьютер может обрабатывать; Это может быть извлечение текста из PDF с помощью PyMuPDF или очистка HTML-тегов после веб-скрейпинга с Beautiful Soup. Каждый из этих инструментов играет свою роль в подготовке данных к следующему этапу – лингвистическому анализу. Без этого этапа все наши дальнейшие усилия могут оказаться напрасными‚ поэтому мы уделяем ему особое внимание.
Токенизация‚ Стемминг и Лемматизация: Разбираем Слова на Части
Сердцем предобработки является разбиение текста на более мелкие‚ осмысленные единицы. Этот процесс называется токенизацией. Мы используем NLTK для токенизации слов и предложений‚ что позволяет нам получить базовые "кирпичики" текста. Представьте‚ что вы разбираете предложение на отдельные слова и знаки препинания. Это необходимо для того‚ чтобы каждый элемент можно было анализировать индивидуально.
Однако просто токенизировать слова недостаточно. Слова могут иметь разные формы: "бежать"‚ "бежит"‚ "бежал". Для машины это три разных слова‚ хотя они имеют один корень. Здесь на помощь приходят стемминг и лемматизация. Стемминг‚ как правило‚ отсекает окончания‚ пытаясь найти "корень" слова‚ но иногда может давать не совсем корректные результаты. Мы часто используем его для быстрого сокращения словаря. Лемматизация же‚ с помощью SpaCy или NLTK‚ стремится привести слово к его базовой словарной форме (лемме)‚ что является более точным‚ поскольку учитывает морфологию языка. Например‚ "бежал"‚ "бежит" и "бегущий" превратятся в "бежать". Для русского языка и других морфологически богатых языков мы часто обращаемся к Stanza‚ который предоставляет более продвинутые возможности для лемматизации и морфологического анализа.
Различия между стеммингом и лемматизацией часто становятся предметом наших внутренних дискуссий. Мы пришли к выводу‚ что выбор зависит от конкретной задачи: для быстрого поиска и сокращения словаря стемминг может быть достаточен‚ но для задач‚ требующих глубокого понимания семантики‚ лемматизация предпочтительнее. Мы также работаем над созданием инструмента для нормализации сленга и обработки эмодзи‚ чтобы наши модели могли адекватно реагировать на постоянно меняющийся язык социальных сетей.
Регулярные Выражения и Очистка Текста: Полируем Исходники
После токенизации и нормализации форм слов‚ мы переходим к очистке текста от нежелательных элементов. Это могут быть ссылки‚ специальные символы‚ числа‚ которые не несут смысловой нагрузки для нашей конкретной задачи‚ или даже стоп-слова (часто встречающиеся слова вроде "и"‚ "в"‚ "на"‚ которые обычно удаляются для уменьшения шума). Для этих целей мы активно используем регулярные выражения (библиотека `re`)‚ которые являются мощным инструментом для поиска и замены паттернов в тексте.
Обработка неструктурированного текста часто включает в себя такие этапы‚ как удаление пунктуации‚ приведение текста к нижнему регистру‚ а также работу с неполными и ошибочными данными. Мы можем столкнуться с опечатками‚ грамматическими ошибками‚ и для этого мы разрабатываем инструменты для проверки грамматики и орфографии. Наша цель – максимально очистить текст‚ чтобы он представлял собой только ту информацию‚ которая действительно важна для анализа‚ минимизируя шум‚ который может исказить результаты.
Работа с Многоязычными Корпусами: Когда Один Язык Недостаточно
Современный мир глобален‚ и текстовые данные приходят к нам на самых разных языках. Наша работа часто выходит за рамки одного языка‚ и здесь на помощь приходят специализированные библиотеки. Мы используем Polyglot для мультиязычной обработки‚ а также Stanza‚ который отлично справляется с языками‚ обладающими богатой морфологией‚ такими как русский. Эти инструменты позволяют нам проводить токенизацию‚ POS-теггинг и лемматизацию для множества языков‚ что критически важно для проектов‚ работающих с международными данными.
Разработка систем машинного перевода на Python является одной из самых сложных‚ но и самых увлекательных задач. Хотя мы не создаем с нуля промышленные системы‚ мы активно используем предварительно обученные Transformer-модели от Hugging Face для высококачественного перевода и адаптации существующих решений. Это позволяет нам работать с текстами на разных языках‚ не теряя при этом их смыслового содержания‚ и открывает широкие возможности для анализа глобальных трендов и мнений.
Превращаем Слова в Числа: Методы Векторизации Текста
После того как текст тщательно очищен и подготовлен‚ возникает следующая фундаментальная задача: как представить слова и документы в виде‚ понятном для алгоритмов машинного обучения? Компьютеры понимают числа‚ а не слова. Поэтому нам необходимо векторизовать текст‚ то есть преобразовать его в числовые векторы. Это один из самых креативных и быстро развивающихся аспектов NLP‚ где мы видим постоянные инновации.
Наш выбор метода векторизации напрямую влияет на качество и производительность последующих моделей. От простых‚ но эффективных подходов‚ основанных на частотности‚ до сложных нейросетевых встраиваний‚ которые улавливают тончайшие семантические нюансы – каждый метод имеет свои преимущества и области применения. Мы постоянно экспериментируем‚ сравниваем и выбираем оптимальные решения для наших задач;
Классические Векторизаторы: От Частотности к Важности
Наши первые шаги в векторизации текста часто начинаются с классических методов. CountVectorizer просто подсчитывает частоту появления каждого слова в документе‚ создавая разреженную матрицу. Это отличный способ быстро получить числовое представление текста‚ но он не учитывает важность слова. Для этого мы используем TfidfVectorizer (TF-IDF)‚ который взвешивает частоту слова в документе обратно пропорционально его частоте во всем корпусе документов. То есть‚ слова‚ которые часто встречаются в одном документе‚ но редко в других‚ получают более высокий вес‚ что делает их более значимыми.
Мы часто сравниваем эти методы‚ чтобы понять‚ какой из них лучше подходит для конкретной задачи. Например‚ для классификации спама CountVectorizer может быть вполне достаточен‚ тогда как для тематического моделирования или извлечения ключевых фраз TF-IDF показывает себя гораздо эффективнее. Разработка собственных векторизаторов текста также является частью нашего арсенала‚ когда стандартные решения не полностью удовлетворяют нашим специфическим требованиям.
Word Embeddings: Когда Слова Обретают Смысл в Пространстве
Классические векторизаторы страдают от отсутствия семантического понимания: они не знают‚ что "король" и "королева" похожи‚ а "король" и "стол" – нет. Word Embeddings стали прорывом‚ представляя слова как плотные векторы в многомерном пространстве‚ где семантически близкие слова находятся рядом. Мы активно используем Word2Vec и GloVe из библиотеки Gensim‚ которые обучаются на больших текстовых корпусах и улавливают эти семантические связи.
Помимо Word2Vec и GloVe‚ мы также работаем с FastText‚ который особенно хорош для работы с редкими словами и языками с богатой морфологией‚ так как он учитывает морфемы (части слов). А для представления целых документов или предложений мы обращаемся к Doc2Vec и Sentence Transformers. Эти методы позволяют нам не только векторизовать отдельные слова‚ но и получать осмысленные представления для более крупных текстовых единиц‚ что незаменимо для задач‚ требующих сравнения документов или поиска схожих предложений.
Контекстные Встраивания и Трансформеры: Революция в Понимании Языка
Самым значительным прорывом последних лет в области NLP стали контекстные встраивания и архитектура Трансформеров. В отличие от Word Embeddings‚ которые дают одно представление для каждого слова независимо от контекста‚ контекстные встраивания‚ как‚ например‚ в BERT‚ генерируют вектор слова‚ учитывая его окружение в предложении. Это позволяет моделям различать значения омонимов и более тонко понимать смысл текста.
Мы активно применяем Трансформеры (Hugging Face) для решения самых сложных задач NLP. Они стали краеугольным камнем для создания современных нейросетей‚ используемых для машинного перевода‚ генерации текста (GPT)‚ вопросно-ответных систем (QA) и даже генерации кода. Возможности этих моделей поражают воображение‚ и мы постоянно исследуем новые способы их применения и тонкой настройки (Fine-tuning) для специфических задач. Это открывает перед нами двери к созданию по-настоящему интеллектуальных систем‚ способных не просто обрабатывать‚ но и творчески взаимодействовать с языком.
Ключевые Задачи NLP: Извлекаем Сущности‚ Темы и Настроения
После того как текст очищен и векторизован‚ мы переходим к основной части работы: извлечению ценной информации и выполнению различных аналитических задач. Здесь мы используем весь арсенал алгоритмов и моделей‚ чтобы заставить текст "говорить". От понимания‚ кто‚ что‚ где и когда упоминается в тексте‚ до определения его общего настроения или скрытых тем – каждый инструмент служит своей уникальной цели‚ помогая нам превращать данные в actionable insights.
В этом разделе мы погрузимся в основные задачи NLP‚ с которыми мы сталкиваемся в нашей практике. Мы увидим‚ как различные библиотеки и подходы позволяют нам решать широкий спектр проблем‚ от довольно простых до чрезвычайно сложных‚ требующих глубокого понимания как лингвистики‚ так и машинного обучения.
Распознавание Именованных Сущностей (NER): Кто‚ Что‚ Где и Когда?
Одной из наиболее фундаментальных и полезных задач в NLP является Распознавание Именованных Сущностей (NER). Суть NER заключается в идентификации и классификации именованных сущностей в тексте‚ таких как имена людей‚ названия организаций‚ географические местоположения‚ даты и денежные суммы. Это позволяет нам быстро извлекать ключевые факты из больших объемов текста.
Мы активно используем spaCy для быстрого NER‚ который известен своей производительностью и точностью. Для более сложных задач и языков мы обращаемся к библиотеке Flair‚ а также к моделям‚ основанным на CRF и‚ конечно же‚ BERT‚ который демонстрирует выдающиеся результаты благодаря своему контекстному пониманию. Разработка систем для автоматической разметки сущностей и выявления связей между сущностями – это то‚ над чем мы постоянно работаем‚ чтобы извлекать еще более глубокие и сложные структуры из текста.
Тематическое Моделирование: Открываем Скрытые Темы
Представьте‚ что у вас есть огромный архив документов‚ и вы хотите понять‚ о чем они вообще. Ручной анализ займет вечность. Здесь на помощь приходит тематическое моделирование – набор алгоритмов‚ которые автоматически обнаруживают абстрактные "темы" в коллекции документов. Для этого мы активно используем библиотеку Gensim‚ в частности‚ алгоритмы LDA (Латентное размещение Дирихле) и LSI (Латентно-семантический анализ).
Мы часто проводим сравнение моделей тематического моделирования (LDA vs NMF)‚ чтобы выбрать наиболее подходящую для конкретного набора данных. Тематическое моделирование незаменимо для анализа текстов отзывов клиентов‚ блогов‚ новостей‚ позволяя нам быстро идентифицировать основные проблемы‚ интересы или обсуждаемые темы‚ даже если они не выражены напрямую. Это мощный инструмент для понимания общего ландшафта информации.
Анализ Тональности (Sentiment Analysis): Понимаем Эмоции в Тексте
В современном мире‚ где репутация бренда и общественное мнение играют ключевую роль‚ понимание эмоционального окраса текста становится критически важным. Анализ тональности (Sentiment Analysis) позволяет нам определить‚ является ли отзыв‚ комментарий или статья позитивной‚ негативной или нейтральной. Мы начинаем с простых‚ но эффективных инструментов‚ таких как VADER для англоязычного текста‚ который хорошо справляется с эмоциями в социальных сетях‚ а также TextBlob для простого NLP‚ который также включает функционал анализа тональности.
Однако задачи анализа тональности могут быть гораздо сложнее‚ особенно когда речь идет о анализе тональности сообщений в социальных сетях (Twitter/Reddit) с учетом сарказма или анализе тональности финансовых новостей‚ где контекст имеет огромное значение. Для этих целей мы часто используем более продвинутые модели‚ включая Transformer-модели для распознавания эмоций‚ которые способны улавливать более тонкие нюансы эмоционального состояния. Мы также разрабатываем собственные словари и тезаурусы для улучшения точности анализа в специфических предметных областях.
"Овладение языком – это не овладение набором правил‚ а овладение искусством использовать его для достижения целей."
— Людвиг Витгенштейн
Классификация Текстов: Сортируем и Категоризируем
Классификация текстов – это задача отнесения документа к одной или нескольким предопределенным категориям. Это может быть классификация новостных статей по темам (спорт‚ политика‚ экономика)‚ определение спама в почтовых сообщениях или категоризация отзывов о продуктах. Мы активно используем применение Scikit-learn для классификации текстов‚ которое предоставляет широкий спектр алгоритмов машинного обучения‚ таких как SVM (Метод опорных векторов) и наивный байесовский классификатор.
Для более сложных задач‚ требующих высокой точности и работы с большими объемами данных‚ мы переходим к применению PyTorch/TensorFlow для создания нейросетей NLP‚ в частности‚ LSTM-сетей‚ а также используем BERT для задач классификации. Мы также исследуем методы машинного обучения без учителя (кластеризация) с использованием Scikit-learn‚ когда предопределенные категории отсутствуют. Это позволяет нам не только категоризировать существующие данные‚ но и разрабатывать системы автоматической категоризации статей и тегования контента‚ что значительно упрощает управление информацией.
Суммаризация Текста: Сжимаем Информацию до Сути
В мире информационного переизбытка‚ способность быстро извлекать суть из длинных документов становится бесценной. Суммаризация текста – это процесс создания краткого‚ но информативного изложения исходного текста. Мы различаем два основных подхода: экстрактивную суммаризацию‚ которая выбирает наиболее важные предложения из оригинального текста‚ и абстрактивную суммаризацию‚ которая генерирует новые предложения‚ перефразируя исходный текст.
Для экстрактивной суммаризации мы часто используем библиотеку TextRank‚ которая основана на алгоритме PageRank и выявляет наиболее важные предложения. Для абстрактивной суммаризации мы обращаемся к мощным Transformer-моделям‚ которые могут генерировать связные и осмысленные резюме. Сравнение моделей суммирования: экстрактивная и абстрактная – это постоянная задача в нашей работе‚ поскольку каждая имеет свои преимущества и недостатки в зависимости от контекста и требований к краткости и точности.
Продвинутые Применения и Специализированные Инструменты
Помимо базовых задач‚ мир NLP изобилует сложными и инновационными применениями‚ которые позволяют нам решать по-нанастоящему амбициозные проблемы. От генерации текста‚ неотличимого от человеческого‚ до создания интеллектуальных чат-ботов и глубокого анализа специфических типов документов – эти области требуют более продвинутых знаний и специализированных инструментов. Мы постоянно расширяем наш арсенал‚ исследуя новые границы возможностей NLP.
В этом разделе мы затронем некоторые из этих продвинутых тем‚ демонстрируя‚ как мы применяем самые современные технологии‚ чтобы не просто обрабатывать‚ но и творчески взаимодействовать с языком. Мы покажем‚ как эти инструменты помогают нам создавать решения‚ которые еще несколько лет назад казались научной фантастикой.
Генерация Текста и Вопросно-Ответные Системы: Творчество Машин
Одним из самых захватывающих направлений в NLP является генерация текста. С появлением таких моделей‚ как GPT и других Transformer-моделей‚ мы можем создавать тексты‚ которые порой трудно отличить от написанных человеком. Это открывает двери для автоматического создания контента‚ генерации ответов в чат-ботах‚ написания сценариев и даже генерации кода. Мы используем Transformer-модели для генерации диалогов‚ что является основой для создания интерактивных систем.
Не менее важной задачей является разработка систем вопросно-ответных систем (QA)‚ которые могут находить ответы на вопросы пользователя в большом корпусе документов. Мы применяем BERT и другие трансформерные архитектуры для этих целей‚ позволяя машинам не просто искать ключевые слова‚ но и понимать смысл вопроса‚ чтобы выдавать наиболее релевантные и точные ответы. Мы также работаем над разработкой системы для создания FAQ на основе документов‚ автоматизируя процесс создания справочной информации.
Веб-Скрейпинг и Извлечение Информации: Добываем Данные
Прежде чем мы сможем анализировать текст‚ его нужно где-то взять. Часто источником данных становятся веб-страницы‚ PDF-документы или другие файлы. Для веб-скрейпинга текста мы используем библиотеку Beautiful Soup‚ которая позволяет нам парсить HTML и извлекать нужный контент. А для извлечения текста из PDF мы обращаемся к PyMuPDF‚ который демонстрирует отличную производительность и точность.
После извлечения сырых данных мы применяем различные техники для анализа текста для извлечения ключевых фраз и извлечения информации. Мы используем RAKE и TextRank для автоматического выделения наиболее значимых фраз и предложений. Это особенно полезно при работе с анализом текста в медицинских записях‚ юридических документах или финансовой отчетности‚ где каждый термин имеет критическое значение.
Чат-боты и Виртуальные Ассистенты: Диалог с Искусственным Интеллектом
Разработка чат-ботов на Python – это одно из самых популярных и прикладных направлений NLP. Мы используем фреймворки‚ такие как Rasa framework‚ который позволяет создавать диалоговые системы‚ способные понимать намерения пользователя‚ извлекать сущности и генерировать осмысленные ответы. Это включает в себя не только понимание запроса‚ но и поддержание контекста диалога‚ что является ключевым для естественного взаимодействия.
Наша работа включает анализ поведенческих паттернов в чатах и анализ пользовательских запросов‚ чтобы постоянно улучшать качество взаимодействия. Создание эффективного чат-бота – это и искусство‚ и наука‚ требующее тонкой настройки языковых моделей‚ продуманной архитектуры диалогов и постоянного обучения на реальных данных. Мы стремимся к тому‚ чтобы наши чат-боты были не просто автоматизированными ответами‚ а настоящими помощниками‚ способными решать задачи и улучшать пользовательский опыт.
Анализ Стилистики и Авторского Почерка: Заглядываем Глубже
Иногда задача NLP выходит за рамки простого понимания смысла слов. Нам нужно понять‚ кто стоит за текстом‚ или какой стиль письма используется. Анализ стилистики текстов (авторский почерк) – это увлекательная область‚ где мы пытаемся идентифицировать уникальные характеристики письма. Это может быть полезно для разработки систем определения авторства текста или для анализа лексического богатства текстов.
Мы используем различные метрики‚ такие как анализ частотности слов и n-грамм‚ а также более сложные подходы‚ основанные на векторизации предложений и документов‚ чтобы создать "отпечаток" стиля автора. Это также включает в себя анализ частотности редких слов и их значение‚ а также анализ частотности имен собственных. Такие методы находят применение в криминалистике‚ литературоведении и для разработки систем обнаружения плагиата‚ где TextDistance для поиска дубликатов играет ключевую роль.
Вызовы и Перспективы: Будущее NLP
Как и любая передовая область‚ NLP постоянно сталкивается с новыми вызовами и открывает захватывающие перспективы. Мы‚ как блогеры и практики‚ всегда находимся на переднем крае этих изменений‚ исследуя новые алгоритмы‚ адаптируя существующие решения и предвидя будущие тренды. Наш путь в NLP – это бесконечный процесс обучения и совершенствования.
В этом заключительном разделе мы хотим обсудить некоторые из наиболее актуальных проблем‚ с которыми мы сталкиваемся‚ а также заглянуть в будущее‚ чтобы понять‚ куда движется эта удивительная область. От работы с несовершенными данными до масштабирования решений для огромных объемов информации – каждый вызов представляет собой возможность для инноваций и роста.
Работа с "Грязными" Данными: Реальный Мир Текста
В идеальном мире все текстовые данные были бы чистыми‚ хорошо структурированными и без ошибок. В реальности же мы постоянно сталкиваемся с проблемами обработки неполных и ошибочных данных; Опечатки‚ грамматические ошибки‚ неполные предложения‚ сленг‚ аббревиатуры – все это делает предобработку текста настоящим искусством. Мы разрабатываем инструменты для исправления орфографии и проверки грамматики‚ часто используя библиотеку Jellyfish для сравнения строк‚ чтобы находить и исправлять похожие слова.
Особенно сложной является работа с эмодзи и сленгом в современных текстах‚ которые постоянно меняются и не всегда имеют однозначную трактовку. Наш опыт показывает‚ что для эффективной работы с такими данными требуется не только техническая подкованность‚ но и глубокое понимание культурного и социального контекста‚ а также постоянное обновление словарей и моделей. Мы также активно используем Sweetviz для анализа текстовых данных‚ что помогает нам быстро выявлять аномалии и качество данных.
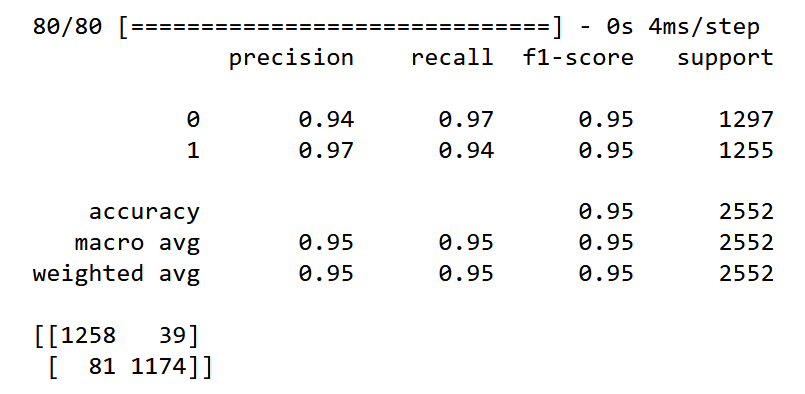
Оценка Качества Моделей: Как Понять‚ Что Мы Делаем Правильно
Разработка модели – это только половина дела. Крайне важно уметь объективно оценивать ее производительность и понимать‚ насколько хорошо она справляется со своей задачей. Для оценки качества NER-моделей‚ классификаторов и других систем мы используем стандартные метрики‚ такие как F1-score‚ Precision и Recall. Эти метрики помогают нам понять‚ насколько точно модель идентифицирует нужные элементы и сколько ошибок она допускает.
Мы также проводим сравнение эффективности различных токенизаторов‚ методов лемматизации (SpaCy vs NLTK) и методов векторизации (TF-IDF vs Word2Vec)‚ чтобы убедиться‚ что мы используем наиболее оптимальный подход для каждой конкретной задачи. Разработка инструмента для автоматической разметки данных является еще одним важным направлением‚ поскольку качественная разметка – это основа для обучения высокоточных моделей.
Масштабирование и Большие Данные: NLP в Индустрии
По мере роста объемов текстовых данных‚ с которыми мы работаем‚ вопросы обработки больших текстовых массивов (Big Data NLP) становятся все более актуальными. Для эффективной работы с терабайтами текста нам приходится оптимизировать наши алгоритмы‚ использовать распределенные вычисления и задействовать GPU-ускорение для обучения глубоких нейросетей. Использование библиотеки Gensim для анализа больших данных является одним из наших ключевых подходов.
Мы постоянно ищем способы улучшить скорость и масштабируемость наших решений‚ будь то обработка текста в режиме реального времени (Streaming NLP) или создание инфраструктуры для анализа огромных корпоративных архивов. Анализ временных рядов в текстовых данных также открывает новые возможности для выявления сезонности и динамики трендов. Будущее NLP неразрывно связано с его способностью обрабатывать и извлекать ценность из постоянно растущих объемов информации.
Наше путешествие по миру обработки естественного языка на Python – это непрерывное приключение‚ полное открытий и интеллектуальных вызовов. Мы видели‚ как простые текстовые данные могут превращаться в ценные инсайты‚ как машины учатся понимать нюансы человеческой речи‚ и как эти знания меняют наш мир. От базовой токенизации до продвинутых трансформерных моделей‚ от анализа тональности до генерации диалогов – каждый шаг в этой области приближает нас к созданию по-настоящему интеллектуальных систем‚ способных взаимодействовать с нами на нашем собственном языке.
Мы надеемся‚ что эта статья вдохновила вас на собственные эксперименты и исследования в области NLP. Python предоставляет невероятно мощный и гибкий набор инструментов‚ который делает эту область доступной для каждого‚ кто готов погрузиться в нее. Продолжайте учиться‚ экспериментировать и делиться своими открытиями. Ведь именно вместе мы сможем разгадать все тайны текста и построить будущее‚ где машины и люди смогут общаться без барьеров.
Подробнее
| Python NLP | Анализ текста | Машинное обучение текста | Нейронные сети NLP | Обработка естественного языка |
| Word Embeddings | Трансформеры Hugging Face | Тематическое моделирование | Анализ тональности Python | Распознавание сущностей |





